サポート終了通知: 2026 年 5 月 31 日、 AWS は のサポートを終了します AWS Panorama。2026 年 5 月 31 日以降、 AWS Panorama コンソールまたは AWS Panorama リソースにアクセスできなくなります。詳細については、AWS Panorama 「サポート終了」を参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
コンピュータービジョンモデル
コンピュータビジョンモデルは、画像内のオブジェクトを検出するようにトレーニングされたソフトウェアプログラムです。モデルは、最初にトレーニングを通じてそれらのオブジェクトの画像を分析することで、一連のオブジェクトを認識することを学習します。コンピュータビジョンモデルは、画像を入力として受け取り、検出したオブジェクトに関する情報 (オブジェクトのタイプや位置など) を出力します。AWS Panorama は PyTorch、Apache MXNet、TensorFlow で構築されたコンピュータビジョンモデルをサポートしています。
注記
AWS Panorama でテストされたビルド済みモデルのリストについては、「モデルの互換性」
コード内でのモデルの使用
モデルは 1 つ以上の結果を返します。これには、検出されたクラスの確率、位置情報、その他のデータが含まれる場合があります。次の例は、ビデオストリームの画像に対して推論を実行し、モデルの出力を処理関数に送信する方法を示しています。
例アプリケーション.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
次の例は、基本分類モデルから結果を処理する関数を示しています。サンプルモデルは確率の配列を返します。これは結果配列の最初で唯一の値です。
例アプリケーション.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
アプリケーションコードは確率が最も高い値を見つけて、初期化時に読み込まれるリソースファイル内のラベルにマッピングします。
カスタムモデルの構築
PyTorch、Apache MXNet、TensorFlow で構築したモデルを AWS Panorama アプリケーションで使用できます。SageMaker AI でモデルを構築およびトレーニングする代わりに、トレーニング済みモデルを使用するか、サポートされているフレームワークを使用して独自のモデルを構築およびトレーニングし、ローカル環境または Amazon EC2 にエクスポートできます。
注記
SageMaker AI Neo でサポートされているフレームワークのバージョンとファイル形式の詳細については、Amazon SageMakerデベロッパーガイド」の「サポートされているフレームワーク」を参照してください。
このガイドのリポジトリには、TensorFlow SavedModel形式の Keras モデルのこのワークフローを示すサンプルアプリケーションが用意されています。TensorFlow 2 を使用しており、仮想環境でローカルに実行することも、Docker コンテナで実行することもできます。サンプルアプリケーションには、Amazon EC2 インスタンスでモデルを構築するためのテンプレートとスクリプトも含まれています。
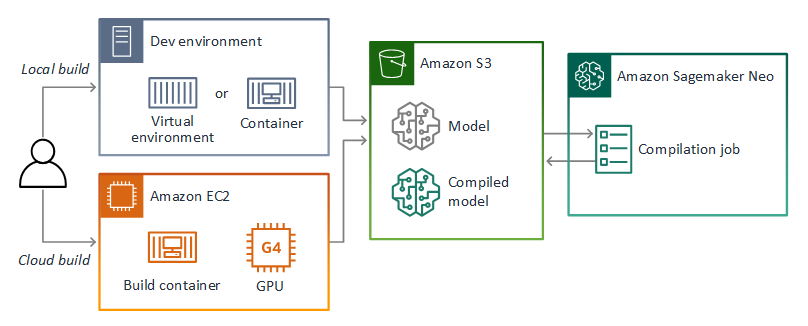
AWS Panorama は SageMaker AI Neo を使用して、AWS Panorama アプライアンスで使用するモデルをコンパイルします。フレームワークごとに、SageMaker AI Neo でサポートされている形式を使用し、モデルを.tar.gzアーカイブにパッケージ化します。
詳細については、Amazon SageMaker SageMaker AI デベロッパーガイド」の「Neo でモデルをコンパイルしてデプロイする」を参照してください。
モデルのパッケージ化
モデルパッケージは、記述子、パッケージ構成、モデルアーカイブで構成されます。アプリケーションイメージパッケージと同様に、パッケージ構成は、モデルと記述子が Amazon S3 のどこに保存されているかを AWS Panorama サービスに伝えます。
例 packages/123456789012-SQUEEZENET_PYTORCH-1.0/descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
注記
フレームワークバージョンのメジャーバージョンとマイナーバージョンのみを指定してください。サポートされている PyTorch、Apache MXNet、および TensorFlow バージョンのリストについては、「サポートされているフレームワーク」を参照してください。
モデルをインポートするには、AWS Panorama アプリケーション CLI import-raw-model コマンドを使用します。モデルやその記述子に変更を加えた場合は、このコマンドを再実行してアプリケーションのアセットを更新する必要があります。詳細については、「コンピュータービジョンモデルの変更」を参照してください。
ディスクリプターファイルの JSON スキーマについては、「AssetDescriptor.schema.json」
モデルのトレーニング
モデルをトレーニングするときは、ターゲット環境、またはターゲット環境によく似たテスト環境のイメージを使用してください。モデルのパフォーマンスに影響を与える可能性がある以下の要因を考慮してください。
-
照明 — 被写体が反射する光の量によって、モデルがどの程度詳細に分析しなければならないかが決まります。明るい被写体の画像でトレーニングしたモデルは、暗い場所や逆光の環境ではうまく機能しない可能性があります。
-
解像度 — モデルの入力サイズは、通常、幅 224 ~ 512 ピクセル (縦横比) の解像度に固定されます。ビデオのフレームをモデルに渡す前に、必要なサイズに合うように縮小またはトリミングできます。
-
画像のゆがみ — カメラの焦点距離とレンズの形状により、画像がフレームの中心から離れるにつれて歪みが生じることがあります。また、カメラの位置によって、被写体のどの部分が見えるかが決まります。たとえば、広角レンズを搭載したオーバーヘッドカメラでは、被写体がフレームの中央にあるときは被写体の上部が表示され、中心から遠ざかるにつれて被写体の側面が歪んで表示されます。
このような問題に対処するには、画像をモデルに送る前に前処理を行い、実世界の環境の変化を反映するさまざまな画像でモデルをトレーニングできます。照明環境やさまざまなカメラでモデルを動作させる必要がある場合は、トレーニングのためにより多くのデータが必要になります。より多くの画像を収集するだけでなく、歪んだ画像や照明が異なる既存の画像のバリエーションを作成することで、より多くのトレーニングデータを取得できます。
