翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ステップ 1: ユースケースと論理データモデルを特定する
自動車企業は、利用可能なすべての自動車部品を保存して検索し、さまざまなコンポーネントと部品間の関係を構築するためのトランザクションコンポーネント管理システムを構築したいと考えています。例えば、自動車には複数のバッテリーが搭載されており、各バッテリーには複数の上位レベルモジュールが含まれ、各モジュールには複数のセルが含まれ、各セルには複数の下位レベルコンポーネントが含まれているとします。
一般に、階層関係モデルを構築するには、Amazon Neptune のようなグラフデータベースを使用すると良いです。ただし、柔軟性、セキュリティ、パフォーマンス、スケールにより、階層データモデリングには Amazon DynamoDB の方が適している場合もあります。
例えば、クエリの 80~90% がトランザクションであるシステムを構築することができますが、このシステムでは DynamoDB の方が適しています。この例では、クエリの残りの 10~20% はリレーショナルであり、Neptune などのグラフデータベースの方が適しています。この場合、クエリの 10~20% しか処理できないようにアーキテクチャに追加のデータベースを含めると、コストが増加する可能性があります。また、複数のシステムを維持し、データを同期するという運用上の負担も増加します。代わりに、その 10~20% のリレーショナルクエリを DynamoDB でモデル化することができます。
自動車コンポーネントのツリーの例を図式化すると、コンポーネント間の関係をマッピングしやすくなります。次の図は、4 つの階層の依存関係をグラフに示しています。CM1 はサンプルカー自体の最上位コンポーネントです。これには 2 つのサブコンポーネントがあります。CM2 と CM3 のサンプルバッテリーです。各バッテリーには 2 つのサブコンポーネントがあり、これをモジュールといいます。CM2 には CM4 と CM5 のモジュールがあり、CM3 には CM6 と CM7 のモジュールがあります。この各モジュールには複数のサブコンポーネントがあり、これをセルといいます。CM4 のモジュールには CM8 と CM9 の 2 つのセルがあります。CM5 には CM10 というセルが 1 つあります。CM6 と CM7 はまだ関連するセルがありません。
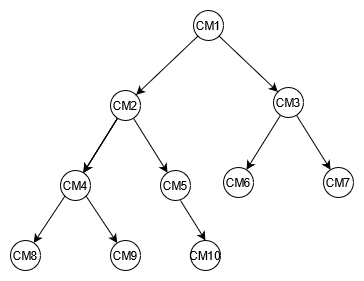
このガイドでは、このツリーとそのコンポーネント ID を参考として使用します。上位のコンポーネントは親、サブコンポーネントは子と呼びます。例えば、最上位コンポーネントである CM1 は CM2 と CM3 の親です。CM2 は CM4 と CM5 の親です。これは親子関係をグラフ化したものとなります。
ツリーでは、コンポーネントの完全な依存関係をグラフで見ることができます。例えば、CM8 は CM4 に依存し、CM4 は CM2 に依存、CM2 は CM1 に依存しています。ツリーでは依存関係グラフ全体をパスとして定義します。パスは、次の 2 つを表します。
-
依存関係グラフ
-
ツリー内の位置
ビジネス要件のテンプレートに入力します。
ユーザーに関する情報を提供する:
ユーザー |
説明 |
従業員 |
自動車とそのコンポーネントの情報を必要とする自動車会社の内部従業員 |
データソースとデータの取り込み方法に関する情報を提供する:
ソース |
説明 |
ユーザー |
管理システム |
使用可能な自動車部品と他のコンポーネントや部品との関係に関連するすべてのデータを保存するシステム。 |
従業員 |
データがどのように消費されるかについての情報を提供する:
コンシューマー |
説明 |
ユーザー |
管理システム |
親コンポーネント ID の直接の子コンポーネントをすべて取得します。 |
従業員 |
管理システム |
コンポーネント ID のすべての子コンポーネントの再帰リストを取得します。 |
従業員 |
管理システム |
コンポーネントの祖先を参照してください。 |
従業員 |
