翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# 局所的 (ローカル) な解釈可能性
複雑なモデルをローカルに解釈するための最も一般的な方法は、Shapley Additive Explanations (SHAP) [[8](resources.md)] または 積分勾配 [[11](resources.md)]です。それぞれの方法には、モデルタイプに固有のさまざまなバリエーションがあります。
## ツリーアンサンブルモデルの場合は、Tree SHAP を使用してください
ツリーベースのモデルの場合、動的プログラミングにより各特徴量の[シャープレイ値](https://en.wikipedia.org/wiki/Shapley_value)を高速かつ正確に計算できるため、ツリーアンサンブルモデルでの局所的な解釈にはこの方法が推奨されます。([7](resources.md)]を参照。実装は [https://github.com/slundberg/shap](https://github.com/slundberg/shap) にあります。)
## ニューラルネットワークと微分可能なモデルには、積分勾配とコンダクタンスを使用してください
積分勾配は、ニューラルネットワークの特徴量アトリビューションを計算する簡単な方法を提供します。コンダクタンスは積分勾配に基づいて構築されるため、レイヤーや個々のニューロンなどのニューラルネットワークの一部からのアトリビューションを解釈しやすくなります。([[3,11](resources.md)] を参照。実装は[ https://captum.ai/](https://captum.ai/) にあります)。勾配を使用しないモデルでは、これらのメソッドを使用することはできません。そのような場合は、代わりに Karnel SHAP (次のセクションで説明) を使用することができます。勾配が利用できる場合は、Karnel SHAP のアトリビューションよりも積分勾配アトリビューションのほうが速く計算できます。積分勾配を使用する際の課題は、解釈を導き出すための最適な基準点を選択することです。たとえば、画像モデルの基点が全ピクセルの強度がゼロの画像である場合、画像の重要な暗い領域には、人間の直感と一致するアトリビューションがない可能性があります。この問題に対処する 1 つの方法は、複数のベースポイントアトリビューションを使用してそれらを合計することです。これは、画像の XRAI 特徴量アトリビューションメソッド [[5](resources.md)] で採用されているアプローチの一部です。このメソッドでは、黒の参照画像と白の参照画像を使用する積分勾配アトリビューションを加算して、より一貫性のあるアトリビューションを作成します。
## それ以外の場合は、Kernel SHAP を使用してください
[Kernel SHAP はどのモデルの特徴量アトリビューションの計算にも使用できますが、Shapley の全値を計算するための近似値であり、計算コストも高くなります ([8](resources.md)] を参照)。Kernel SHAP に必要な計算リソースは、特徴量の数が増えるにつれて急速に増加します。そのためには、説明の正確性、再現性、堅牢性を低下させる可能性のある近似法が必要です。Amazon SageMaker AI Clarify には、Kernal SHAP 値を計算するための構築済みコンテナを個別のインスタンスに展開する便利なメソッドが用意されています。(例については、GitHub リポジトリの「[SageMaker AI Clarify による公平性と説明性](https://github.com/aws/amazon-sagemaker-examples/blob/35e2faf7d1cc48ccedf0b2ede1da9987a18727a5/sagemaker_processing/fairness_and_explainability/fairness_and_explainability.ipynb)」を参照してください)。
単一ツリーモデルの場合、分割変数とリーフ値ですぐに説明できるモデルになりますが、前に説明した方法では追加の洞察は得られません。同様に、線形モデルの場合は、係数によってモデルの動作が明確に説明されます。(SHAP メソッドと統合勾配メソッドはどちらも、係数によって決定される寄与を返します)。
SHAP と統合勾配ベースのメソッドにはどちらも弱点があります。SHAP では、すべての特徴量の組み合わせの加重平均からアトリビューションを導き出す必要があります。この方法で取得されたアトリビューションは、特徴量間に強い相互作用がある場合、特徴量の重要度を推定する際に誤解を招く可能性があります。大規模なニューラルネットワークには多数の次元が存在するため、統合勾配に基づく方法は解釈が難しい場合があり、これらの方法は基点の選択に敏感です。より一般的には、モデルはある程度のパフォーマンスを達成するために予期しない方法で機能を使用する場合があり、その方法はモデルによって異なる場合があります。特徴量の重要性は常にモデルによって異なります。
## 推奨される視覚化機能
次の表は、前のセクションで説明した局所的な解釈を視覚化するいくつかの推奨方法を示しています。表形式のデータについては、アトリビューションを簡単に比較したり、モデルがどのように予測を行っているかを推測したりできるように、アトリビューションを示すシンプルな棒グラフをお勧めします。
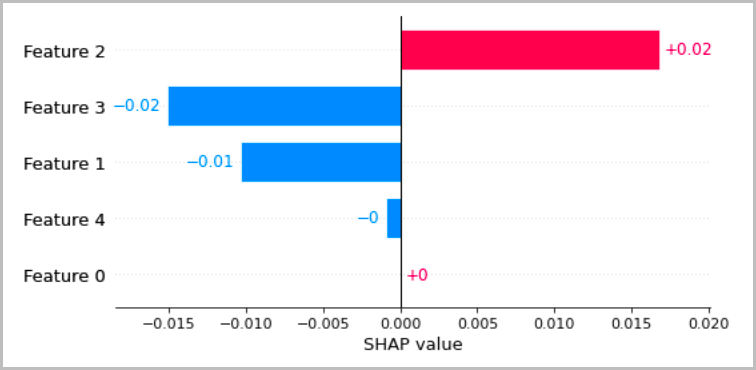
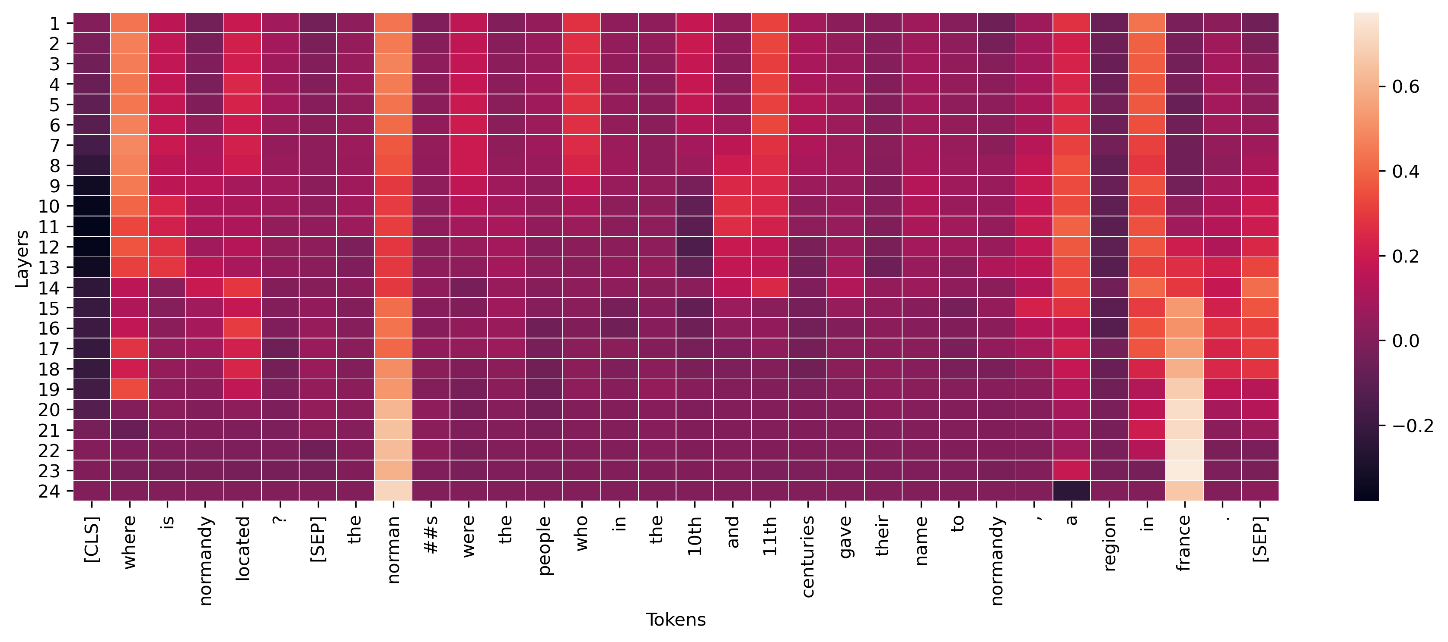
テキストデータの場合、トークンを埋め込むと多数のスカラー入力が発生します。前のセクションで推奨した方法では、埋め込みの各ディメンションと各出力ごとにアトリビューションを生成します。この情報を視覚化にまとめるには、特定のトークンのアトリビューションを合計します。次の例は、SQUAD データセットでトレーニングされた BERT ベースの質問応答モデルのアトリビューションの合計を示しています。この場合、予測された正しいラベルは「france(フランス)」という単語のトークンです。

それ以外の場合は、次の例のように、トークンアトリビューションのベクトルノルムをアトリビューション値の合計として割り当てることができます。

深層学習モデルの中間層では、次の例に示すように、同様の集計をコンダクタンスに適用して視覚化できます。この変換レイヤーのトークンコンダクタンスのベクトルノルムは、最終的なエンドトークン予測 ("france") のアクティベーションを示しています。
コンセプトアクティベーションベクトルは、ディープニューラルネットワークをより詳細に研究するメソッドを提供します [[6](resources.md)]。このメソッドでは、学習済みのネットワーク内のレイヤーから特徴量を抽出し、それらの特徴量に基づいて線形分類器に学習させ、レイヤー内の情報を推測します。たとえば、BERT ベースの言語モデルのどのレイヤーに品詞に関する情報が最も多く含まれているかを調べたい場合があります。この場合、各レイヤーの出力で線形品詞モデルを学習させ、最もパフォーマンスの高い分類器が品詞情報が最も多い層に関連していると大まかに見積もることができます。これをニューラルネットワークを解釈するための主要な方法としては推奨しませんが、より詳細な研究を行うためのオプションとなり、ネットワークアーキテクチャの設計に役立つ可能性があります。