翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
サービスごとのデータベースパターン
各マイクロサービスはそれぞれ独自のデータストアに情報を格納し、そこから情報を取り出すことができるため、疎結合はマイクロサービスアーキテクチャの核となる特性です。サービスごとのデータベースパターンを導入することで、アプリケーションやビジネス要件に最も適したデータストア (例えば、リレーショナルデータベースや非リレーショナルデータベースなど) を選択できます。つまり、マイクロサービスはデータレイヤーを共有せず、マイクロサービスの個々のデータベースを変更しても他のマイクロサービスには影響せず、個々のデータストアには他のマイクロサービスから直接アクセスできず、永続データには API のみがアクセスすることになります。データストアを分離すると、アプリケーション全体の耐障害性が向上し、1 つのデータベースが単一障害点になることがなくなります。
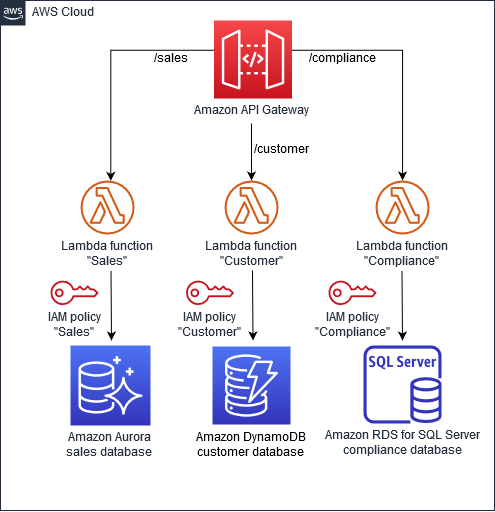
次の図では、「Sales」、「Customer」、および「Compliance」マイクロサービスによって異なる AWS データベースが使用されています。これらのマイクロサービスは関数として AWS Lambda デプロイされ、Amazon API Gateway API を介してアクセスされます。 AWS Identity and Access Management (IAM) ポリシーは、データがプライベートに保持され、マイクロサービス間で共有されないようにします。各マイクロサービスは、それぞれの要件を満たすデータベースタイプを使用します。たとえば、「セールス」は Amazon Aurora を使用し、「カスタマー」は Amazon DynamoDB を使用し、「コンプライアンス」は SQL Server 用の Amazon Relational Database Service (Amazon RDS) を使用します。
このパターンの使用を検討すべきなのは、次のような場合です。
-
マイクロサービス間の疎結合が必要です。
-
マイクロサービスは、データベースに対するコンプライアンスやセキュリティ要件が異なります。
-
スケーリングをよりきめ細かく制御する必要があります。
サービスごとのデータベースパターンを使用する場合、次のような欠点があります。
-
複数のマイクロサービスやデータストアにまたがる複雑なトランザクションやクエリを実装するのは難しいかもしれません。
-
複数のリレーショナルデータベースと非リレーショナルデータベースを管理する必要があります。
-
データストアは、CAP 定理
の 2 つの要件、つまり、一貫性、可用性、または分断耐性を満たす必要があります。
注記
サービスごとのデータベースパターンを使用する場合は、 またはその他のパターンをデプロイして、複数のマイクロサービスにまたがるクエリを実装する必要があります。(CQRS パターン で高速化できる) API 構成パターン またはイベントソーシングパターンを使用して、集計結果を作成できます。
