翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
# Microsoft SQL Server から Amazon Aurora PostgreSQL 互換エディションへのデータベース移行をサポートするように Python と Perl アプリケーションを変更する
*Amazon Web Services、Dwarika Patra、Deepesh Jayaprakash*
## 概要
このパターンでは、Microsoft SQL Server から Amazon Aurora PostgreSQL 互換エディションにデータベースを移行する際に、場合によっては必要になるアプリケーションリポジトリに変更します。このパターンでは、これらのアプリケーションが Python または Perl ベースであることを前提としており、これらのスクリプト言語には個別の指示が記載されています。
SQL Server データベースから Aurora PostgreSQL 互換に移行するには、スキーマ変換、データベースオブジェクト変換、データ移行、およびデータ読み込みが必要です。 PostgreSQL と SQL Server には (データ型、接続オブジェクト、構文、ロジックに関する) 違いがあるため、PostgreSQL で正しく動作するようにコードベースに必要な変更を追加するのが最も難しい移行作業です。
Python ベースのアプリケーションでは、接続オブジェクトとクラスはシステム全体に分散されています。また、Python コードベースは複数のライブラリを使用してデータベースに接続している場合があります。データベース接続インターフェースが変更された場合、アプリケーションのインラインクエリを実行するオブジェクトも変更する必要があります。
Perl ベースのアプリケーションの場合、変更には接続オブジェクト、データベース接続ドライバー、静的および動的なインライン SQL ステートメント、およびアプリケーションが複雑な動的 DML クエリと結果をセットで処理する方法が含まれます。
アプリケーションを移行する際には、FTP サーバーを Amazon Simple Storage Service (Amazon S3) アクセスに置き換えるなど、AWS で可能な機能強化を検討することもできます。
アプリケーションの移行プロセスには、以下の問題があります。
+ 接続オブジェクト。接続オブジェクトが複数のライブラリや、関数呼び出しを含むコードに分散している場合、PostgreSQL をサポートするようにオブジェクトを変更する共通の方法を見つける必要があるかもしれません。
+ レコードの取得または更新中のエラーや例外の処理。変数、結果セット、またはデータフレームを返す条件付きの作成、読み取り、更新、削除 (CRUD) 操作をデータベースで実行すると、エラーや例外によってアプリケーションエラーが発生し、連鎖的な影響が発生する可能性があります。これらの処理は、適切な検証を行いながら、ポイントを保存して慎重に処理する必要があります。このようなセーブポイントの 1 つとして、`BEGIN...EXCEPTION...END` ブロック内で大規模なインライン SQL クエリやデータベースオブジェクトを呼び出すことがあります。
+ トランザクションの制御と検証。手動および自動のコミットとロールバックが含まれます。Perl 用の PostgreSQL ドライバーでは、常に自動コミット属性を明示的に設定する必要があります。
+ 動的 SQL クエリを処理します。これには、クエリが意図したとおりに動作することを確実にするため、クエリロジックと反復テストを詳しく理解する必要があります。
+ パフォーマンス コードを変更しても、アプリケーションのパフォーマンスが低下しないようにする必要があります。
このパターンでは、変換プロセスを詳しく説明します。
## 前提条件と制限
**前提条件**
+ Python と Perl の構文に関する実用的な知識。
+ SQL Server および PostgreSQL に関する基本スキル
+ 既存のアプリケーションアーキテクチャを理解しましょう。
+ アプリケーションコード、SQL Server データベース、および PostgreSQL データベースにアクセスできます。
+ アプリケーションの変更を開発、テスト、検証するための認証情報を使用して Windows または Linux (または他の Unix) 開発環境にアクセスできます。
+ Python ベースのアプリケーションでは、データフレームを処理するための **Pandas** や、データベース接続用の **psycopg2** や **SQLAlchemy** など、アプリケーションが必要とする標準の Python ライブラリが必要です。
+ Perl ベースのアプリケーションでは、依存ライブラリまたはモジュールを含む Perl パッケージが必要です。包括的な Perl Archive Network (CPAN) モジュールは、ほとんどのアプリケーション要件をサポートします。
+ 必要なすべての依存関係のあるカスタマイズされたライブラリまたはモジュール。
+ SQL Server への読み込みアクセスと Aurora への読み込み/書き込みアクセス用のデータベース認証情報。
+ PostgreSQL は、サービスやユーザーによるアプリケーションの変更を検証およびデバッグします。
+ アプリケーションの移行中に Visual Studio Code、Sublime Text、**pgAdmin** などの開発ツールにアクセスできます。
**機能制限**
+ Python や Perl のバージョン、モジュール、ライブラリ、パッケージの中には、クラウド環境と互換性のないものがあります。
+ SQL Server に使用されているサードパーティのライブラリやフレームワークの中には、PostgreSQL への移行をサポートするように置き換えられないものがあります。
+ パフォーマンスの変動により、アプリケーション、インライン Transact-SQL (T-SQL) クエリ、データベース関数、ストアドプロシージャの変更が必要な場合があります。
+ PostgreSQL は、テーブル名、列名、および他のデータベースオブジェクトの小文字名をサポートします。
+ UUID 列などの一部のデータタイプは小文字のみで保存されます。Python と Perl のアプリケーションは、このような大文字と小文字の違いを処理する必要があります。
+ 文字エンコーディングの違いは、PostgreSQL データベース内の対応するテキスト列の正しいデータタイプで処理する必要があります。
**製品バージョン**
+ Python 3.6 以降 (オペレーティングシステムをサポートするバージョンを使用してください)
+ Perl 5.8.3 以降 (オペレーティングシステムをサポートするバージョンを使用してください)
+ Aurora PostgreSQL 互換エディション 4.2 以降 (「[詳細](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.Updates.20180305.html#AuroraPostgreSQL.Updates.20180305.42)」を参照してください)
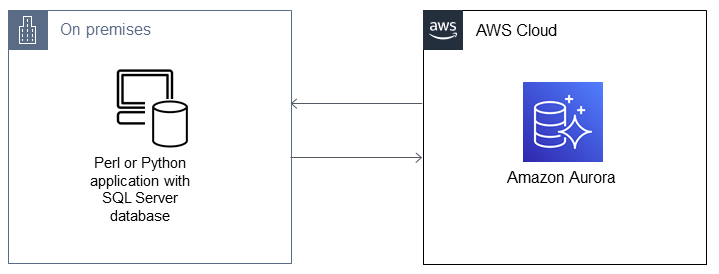
## アーキテクチャ
**ソーステクノロジースタック**
+ スクリプト作成 (アプリケーションプログラミング) 言語: Python 2.7 以降または Perl 5.8
+ データベース: Microsoft SQL Server バージョン 13
+ オペレーティングシステム: Red Hat Enterprise Linux (RHEL) 7
**ターゲットテクノロジースタック**
+ スクリプト作成 (アプリケーションプログラミング) 言語:Python 3.6 以降または Perl 5.8 以降
+ データベース: Aurora PostgreSQL 互換 4.2
+ オペレーティングシステム: RHEL 7
**移行アーキテクチャ**
## ツール
**AWS のサービスとツール**
+ [Aurora PostgreSQL 互換エディション](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraPostgreSQL.html)は、フルマネージド型で PostgreSQL 互換の、ACID 準拠のリレーショナルデータベースエンジンです。ハイエンドの商用データベースのスピードと信頼性を、オープンソースデータベースのコスト効率でご利用いただけます。PostgreSQL を Aurora PostgreSQL に差し替えることで、新規および既存の PostgreSQL のデプロイを簡単に、コスト効率よく設定、操作、スケーリングできるようになります。
+ [AWS コマンドラインインターフェイス (AWS CLI)](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html) はオープンソースのツールであり、コマンドラインシェルのコマンドを使用して AWS サービスとやり取りすることができます。
**その他のツール**
+ [psycopg2](https://pypi.org/project/psycopg2/) や [SQLAlchemy](https://www.sqlalchemy.org/) などの [Python](https://www.python.org/) および PostgresSQL データベース接続ライブラリ
+ [Perl](https://www.perl.org/) とその [DBI モジュール](https://metacpan.org/pod/DBD::Pg)
+ [PostgreSQL インタラクティブターミナル](https://www.postgresql.org/docs/13/app-psql.html) (psql)
## エピック
### アプリケーションリポジトリを PostgreSQL に移行する — 大まかな手順
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| 以下のコード変換手順に従って、アプリケーションを PostgreSQL に移行してください。 | [See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html)以下のエピックでは、Python および Perl アプリケーションの変換タスクの一部について詳しく説明します。 | アプリ開発者 |
| 移行の各ステップでチェックリストを使用します。 | アプリケーション移行の各手順 (最終ステップを含む) のチェックリストに以下の項目を追加してください。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html) | アプリ開発者 |
### アプリケーションの分析と更新 — Python コードベース
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| 既存の Python コードベースを分析します。 | アプリケーションの移行プロセスを円滑に進めるため、以下の項目を分析に含める必要があります。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html) | アプリ開発者 |
| PostgreSQL をサポートするようにデータベース接続を変換します。 | ほとんどの Python アプリケーションは、次のように **pyodbcx **ライブラリを使用して SQL Server データベースに接続します。import pyodbc
....
try:
conn_string = "Driver=ODBC Driver 17 for SQL
Server;UID={};PWD={};Server={};Database={}".format (conn_user, conn_password,
conn_server, conn_database)
conn = pyodbc.connect(conn_string)
cur = conn.cursor()
result = cur.execute(query_string)
for row in result:
print (row)
except Exception as e:
print(str(e))
PostgreSQL をサポートするようにデータベース接続を変換します。 import pyodbc
import psycopg2
....
try:
conn_string = ‘postgresql+psycopg2://’+
conn_user+’:’+conn_password+’@’+conn_server+’/’+conn_database
conn = pyodbc.connect(conn_string, connect_args={‘options’:’-csearch_path=dbo’})
cur = conn.cursor()
result = cur.execute(query_string)
for row in result:
print (row)
except Exception as e:
print(str(e))
| アプリ開発者 |
| インライン SQL クエリを PostgreSQL に変更します。 | インライン SQL クエリを PostgreSQL 互換の形式に変換します。たとえば、次の SQL Server クエリはテーブルから文字列を取得します。 dtype = "type1"
stm = ‘"SELECT TOP 1 searchcode FROM TypesTable (NOLOCK)
WHERE code="’ + "’" + str(dtype) + "’"
# For Microsoft SQL Server Database Connection
engine = create_engine(‘mssql+pyodbc:///?odbc_connect=%s’ % urllib.parse.quote_plus(conn_string), connect_args={‘connect_timeout’:login_timeout})
conn = engine_connect()
rs = conn.execute(stm)
for row in rs:
print(row)
変換後、PostgreSQL 互換のインライン SQL クエリは以下のようになります。 dtype = "type1"
stm = ‘"SELECT searchcode FROM TypesTable
WHERE code="’ + "’" + str(dtype) + "’ LIMIT 1"
# For PostgreSQL Database Connection
engine = create_engine(‘postgres+psycopg2://%s’ %conn_string, connect_args={‘connect_timeout’:login_timeout})
conn = engine.connect()
rs = conn.execute(stm)
for row in rs:
print(row)
| アプリ開発者 |
| 動的 SQL クエリの処理。 | 動的 SQL は、1 つのスクリプトに存在することも、複数の Python スクリプトに含めることもできます。 先ほどの例では、Python の文字列置換関数を使用して動的 SQL クエリを構築するために変数を挿入する方法を説明しました。別の方法として、該当する箇所に変数を使用してクエリ文字列を追加することもできます。
次の例では、関数から返された値に基づいてクエリ文字列が作成されます。query = ‘"SELECT id from equity e join issues i on e.permId=i.permId where e.id’"
query += get_id_filter(ids) + " e.id is NOT NULL
このような動的クエリは、アプリケーションの移行中によく使用されます。以下のステップに従って、動的クエリの処理を行います。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html) | アプリ開発者 |
| 結果セット、変数、データフレームを処理します。 | Microsoft SQL Server では、`fetchone()` または `fetchall()` などの Python メソッドを使用してデータベースから結果セットを取得します。`fetchmany(size)` を使用して、結果セットから返されるレコードの数を指定することもできます。これを実行するには、次の例に示すように、**pyodbc **接続オブジェクトを使用します。
**pyodbc (Microsoft SQL Server)**import pyodbc
server = 'tcp:myserver.database.windows.net'
database = 'exampledb'
username = 'exampleusername'
password = 'examplepassword'
conn = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server};SERVER='+server+';DATABASE='+database+';UID='+username+';PWD='+ password)
cursor = conn.cursor()
cursor.execute("SELECT * FROM ITEMS")
row = cursor.fetchone()
while row:
print(row[0])
row = cursor.fetchone()
Aurora では、PostgreSQL への接続や結果セットの取得などの同様のタスクを実行するには、**psycopg2 **または **SQLAlchemy** のどちらかを使用します。これらの Python ライブラリは、次の例に示すように、PostgreSQL データベースレコードを走査するための接続モジュールとカーソルオブジェクトを提供します。
**psycopg2 (Aurora PostgreSQL 互換)**import psycopg2
query = "SELECT * FROM ITEMS;"
//Initialize variables
host=dbname=user=password=port=sslmode=connect_timeout=""
connstring = "host='{host}' dbname='{dbname}' user='{user}' \
password='{password}'port='{port}'".format(host=host,dbname=dbname,\
user=user,password=password,port=port)
conn = psycopg2.connect(connstring)
cursor = conn.cursor()
cursor.execute(query)
column_names = [column[0] for column in cursor.description]
print("Column Names: ", column_names)
print("Column values: "
for row in cursor:
print("itemid :", row[0])
print("itemdescrption :", row[1])
print("itemprice :", row[3]))
**SQL Alchemy (Aurora PostgreSQL 互換)**from sqlalchemy import create_engine
from pandas import DataFrame
conn_string = 'postgresql://core:database@localhost:5432/exampledatabase'
engine = create_engine(conn_string)
conn = engine.connect()
dataid = 1001
result = conn.execute("SELECT * FROM ITEMS")
df = DataFrame(result.fetchall())
df.columns = result.keys()
df = pd.DataFrame()
engine.connect()
df = pd.read_sql_query(sql_query, engine, coerce_float=False)
print("df=", df)
| アプリ開発者 |
| 移行中や移行後にアプリケーションをテストします。 | 移行後の Python アプリケーションのテストは継続的なプロセスです。移行には接続オブジェクトの変更 (**psycopg2 **または **SQLAlchemy**)、エラー処理、新機能 (データフレーム)、インライン SQL の変更、大容量レプリケーション機能 (`COPY` ではなく `bcp`)、および同様の変更が含まれるため、アプリケーションの移行中および移行後に慎重にテストする必要があります。以下の項目を確認してください。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html) | アプリ開発者 |
### アプリケーションの分析と更新 — Perl コードベース
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| 既存の Perl コードベースを分析します。 | アプリケーションの移行プロセスを円滑に進めるため、以下の項目を分析に含める必要があります。以下の項目を特定する必要があります。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html) | アプリ開発者 |
| Perl アプリケーションと DBI モジュールからの接続を PostgreSQL をサポートするように変換します。 | Perl ベースのアプリケーションは通常、Perl プログラミング言語の標準データベースアクセスモジュールである Perl DBI モジュールを使用します。 同じ DBI モジュールを SQL Server 用と PostgreSQL 用の異なるドライバーで使用できます。
必要な Perl モジュール、インストール、およびその他の手順の詳細については、[DBD::Pg のドキュメント](https://metacpan.org/pod/DBD::Pg)を参照してください。次の例は、`exampletest-aurorapg-database.cluster-sampleclusture.us-east.-rds.amazonaws.com` で Aurora PostgreSQL 互換に接続しています。#!/usr/bin/perl
use DBI;
use strict;
my $driver = "Pg";
my $hostname = "exampletest-aurorapg-database-sampleclusture.us-east.rds.amazonaws.com"
my $dsn = "DBI:$driver: dbname = $hostname;host = 127.0.0.1;port = 5432";
my $username = "postgres";
my $password = "pass123";
$dbh = DBI->connect("dbi:Pg:dbname=$hostname;host=$host;port=$port;options=$options",
$username,
$password,
{AutoCommit => 0, RaiseError => 1, PrintError => 0}
);
| アプリ開発者 |
| インライン SQL クエリを PostgreSQL に変更します。 | アプリケーションには、`SELECT`、`DELETE`、`UPDATE` など、PostgreSQL でサポートされていないクエリ句を含むインライン SQL クエリが含まれている場合があります。たとえば、`TOP` や `NOLOCK` などのクエリキーワードは PostgreSQL ではサポートされていません。次の例では、`TOP`、`NOLOCK`、およびブール型変数の処理方法を示しています。
In SQL Server:$sqlStr = $sqlStr
. "WHERE a.student_id in (SELECT TOP $numofRecords c_student_id \
FROM active_student_record b WITH (NOLOCK) \
INNER JOIN student_contributor c WITH (NOLOCK) on c.contributor_id = b.c_st)
PostgreSQL の場合は、次のように変換してください。$sqlStr = $sqlStr
. "WHERE a.student_id in (SELECT TOP $numofRecords c_student_id \
FROM active_student_record b INNER JOIN student_contributor c \
on c.contributor_id = b.c_student_contr_id WHERE b_current_1 is true \
LIMIT $numofRecords)"
| アプリ開発者 |
| 動的 SQL クエリと Perl 変数を処理します。 | 動的 SQL クエリは、アプリケーションのランタイム時に作成される SQL ステートメントです。これらのクエリは、アプリケーションのランタイムに特定の条件に応じて動的に構築されるため、特定の条件に依存するので、クエリの全文は実行時に把握できません。例としては、毎日上位 10 銘柄を分析する財務分析アプリケーションがあります。これらの株式は毎日変動します。SQL テーブルはトップパフォーマーに基づいて作成され、その値はランタイムになるまでわかりません。
この例のインライン SQL クエリは、変数に設定された結果を取得するためにラッパー関数に渡され、変数は条件を使用してテーブルが存在するかどうかを判断します。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html)
次に、変数処理の例を示します。次に、このユースケースの SQL Server クエリと PostgreSQL クエリを示します。my $tableexists = db_read( arg 1, $sql_qry, undef, 'writer');
my $table_already_exists = $tableexists->[0]{table_exists};
if ($table_already_exists){
# do some thing
}
else {
# do something else
}
SQL Server:my $sql_qry = "SELECT OBJECT_ID('$backendTable', 'U') table_exists", undef, 'writer')";
PostgreSQL:my $sql_qry = "SELECT TO_REGCLASS('$backendTable', 'U') table_exists", undef, 'writer')";
次の例では、インライン SQL の** **Perl 変数を使用して、`SELECT` と一緒に `JOIN` ステートメントを実行し、テーブルのプライマリキーとキーカラムの位置を取得します。
SQL Server:my $sql_qry = "SELECT column_name', character_maxi mum_length \
FROM INFORMATION_SCHEMA.COLUMNS \
WHERE TABLE_SCHEMA='$example_schemaInfo' \
AND TABLE_NAME='$example_table' \
AND DATA_TYPE IN ('varchar','nvarchar');";
PostgreSQL:my $sql_qry = "SELECT c1.column_name, c1.ordinal_position \
FROM information_schema.key_column_usage AS c LEFT \
JOIN information_schema.table_constraints AS t1 \
ON t1.constraint_name = c1.constraint_name \
WHERE t1.table_name = $example_schemaInfo'.'$example_table’ \
AND t1.constraint_type = 'PRIMARY KEY' ;";
| アプリ開発者 |
### PostgreSQL をサポートするために、Perl ベースまたは Python ベースのアプリケーションに追加の変更を加えます。
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| 他の SQL Server コンストラクトを PostgreSQL に変換します。 | 次の変更は、プログラミング言語にかかわらず、すべてのアプリケーションに適用されます。[See the AWS documentation website for more details](http://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/patterns/change-python-and-perl-applications-to-support-database-migration-from-microsoft-sql-server-to-amazon-aurora-postgresql-compatible-edition.html) | アプリ開発者 |
### パフォーマンスを向上する
| タスク | 説明 | 必要なスキル |
| --- | --- | --- |
| AWS のサービスを活用してパフォーマンスを向上させましょう。 | AWS クラウドに移行すると、アプリケーションとデータベースのデザインを改良して AWS のサービスを活用できます。たとえば、Aurora PostgreSQL 互換データベースサーバーに接続されている Python アプリケーションからのクエリが、元の Microsoft SQL Server クエリよりも時間がかかる場合は、Aurora サーバーから Amazon Simple Storage Service (Amazon S3) バケットに履歴データのフィードを直接作成し、Amazon Athena ベースの SQL クエリを使用してユーザーダッシュボード用のレポートと分析データクエリを生成することを検討できます。 | アプリ開発者、クラウドアーキテクト |
## 関連リソース
+ [Perl](https://www.perl.org/)
+ [Perl DBI モジュール](https://metacpan.org/pod/DBI)
+ [Python](https://www.python.org/)
+ [psycopg2](https://pypi.org/project/psycopg2/)
+ [SQLAlchemy](https://www.sqlalchemy.org/)
+ [一括コピー - PostgreSQL](https://www.postgresql.org/docs/9.2/sql-copy.html)
+ [一括コピー - Microsoft SQL サーバー](https://docs.microsoft.com/en-us/sql/tools/bcp-utility?view=sql-server-ver15)
+ [PostgreSQL](https://www.postgresql.org/)
+ [Amazon Aurora PostgreSQL の操作](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraPostgreSQL.html)
## 追加情報
Microsoft SQL Server と Aurora PostgreSQL 互換はいずれも ANSI SQL に準拠しています。ただし、Python または Perl アプリケーションを SQL Server から PostgreSQL に移行する場合は、構文、列データ型、ネイティブデータベース固有の関数、一括挿入、および大文字と小文字の区別に互換性がないことに注意する必要があります。
次のセクションでは、考えられる不一致について詳しく説明します。
**データ型の比較**
データタイプを SQL Server から PostgreSQL に変更すると、アプリケーションが操作する結果データに大きな違いが生じる可能性があります。データ型の比較については、[Sqlines ウェブサイト](https://www.sqlines.com/sql-server-to-postgresql)の表を参照してください。
**ネイティブの SQL 関数またはビルトイン SQL 関数**
一部の関数の動作は、SQL Server データベースと PostgreSQL データベースで異なります。次の表に例を示しています。
|
|
| Microsoft SQL Server | 説明 | [PostgreSQL] |
| --- |--- |--- |
| `CAST` | 値を 1 つのデータ型から別のデータ型へ変換します。 | PostgreSQL `type :: operator` |
| `GETDATE()` | 現在のデータベースシステムの日付と時刻を `YYYY-MM-DD hh:mm:ss.mmm` 形式で返します。 | `CLOCK_TIMESTAMP` |
| `DATEADD` | 日付に時刻/日付の間隔を追加します。 | `INTERVAL` expression |
| `CONVERT` | 値を特定のデータ形式に変換します。 | `TO_CHAR` |
| `DATEDIFF` | 2 つの日付間の日数の差を返します。 | `DATE_PART` |
| `TOP` | `SELECT` 結果セットの行数を制限します。 | `LIMIT/FETCH` |
** 匿名ブロック**
構造化 SQL クエリは、宣言、実行可能ファイル、例外処理などのセクションに分かれています。次の表は、シンプルな匿名ブロックの Microsoft SQL Server バージョンと PostgreSQL バージョンを比較したものです。複雑な匿名ブロックの場合は、アプリケーション内でカスタムデータベース関数を呼び出すことをお勧めします。
|
|
| Microsoft SQL Server | [PostgreSQL] |
| --- |--- |
| my $sql_qry1=
my $sql_qry2 =
my $sqlqry = "BEGIN TRAN
$sql_qry1 $sql_qry2
if @\@error !=0 ROLLBACK
TRAN
else COMIT TRAN";
| my $sql_qry1=
my $sql_qry2 =
my $sql_qry = " DO \$\$
BEGIN
$header_sql $content_sql
END
\$\$";
|
**他の違い**
+ **行の一括挿入:** [Microsoft SQL Server の bcp ユーティリティ](https://docs.microsoft.com/en-us/sql/tools/bcp-utility?view=sql-server-ver15) に相当する PostgreSQL は [COPY](https://www.postgresql.org/docs/9.2/sql-copy.html) です。
+ **大文字と小文字の区別:** PostgreSQL では列名の大文字と小文字が区別されるため、SQL Server の列名を小文字または大文字に変換する必要があります。これは、データを抽出または比較したり、結果セットや変数に列名を入力するときの要因になります。次の例では、値を大文字または小文字で保存できる列を表示しています。
```
my $sql_qry = "SELECT $record_id FROM $exampleTable WHERE LOWER($record_name) = \'failed transaction\'";
```
+ **連結: **SQL Server は文字列連結の演算子として `+` を使用し、PostgreSQL は `||` を使用します。
+ **検証: **PostgreSQL のアプリケーションコードで使用する前に、インライン SQL クエリと関数をテストして検証する必要があります。
+ **ORM ライブラリの追加:`**既存のデータベース接続ライブラリを [SQLAlchemy](https://www.sqlalchemy.org/) や [PynoMoDB](https://pynamodb.readthedocs.io/en/latest/quickstart.html) などの Python ORM ライブラリに含めたり、置き換えたりすることもできます。これにより、オブジェクト指向のパラダイムを使用して、データベースからデータを簡単にクエリして操作できるようになります。