翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Elastic Disaster Recoveryで Oracle JD Edwards EnterpriseOne のディザスタリカバリをセットアップする
作成者: Thanigaivel Thirumalai (AWS)
概要
自然災害、アプリケーション障害、またはサービスの中断による災害は、収益に悪影響を及ぼし、企業アプリケーションのダウンタイムを引き起こします。JD Edwards EnterpriseOne Enterprise Resource Planning (ERP) システムやその他のミッションクリティカルかつビジネスクリティカルなソフトウェアを導入する企業にとって、このような事象の影響を軽減するためのディザスタリカバリ (DR) 計画が不可欠です。
このパターンは、企業が JD Edwards EnterpriseOne アプリケーションの DR オプションとして AWS Elastic Disaster Recovery を使用する方法を説明しています。また、Elastic Disaster Recovery のフェイルオーバーとフェイルバックを使用して、AWS クラウドの Amazon Elastic Compute Cloud (Amazon EC2) インスタンスでホストされているデータベースのクロスリージョン DR 戦略を構築する手順についても概説しています。
注記
このパターンでは、クロスリージョン DR 実装のプライマリリージョンとセカンダリリージョンを AWS でホストする必要があります。
Oracle JD Edwards EnterpriseOne
AWS Elastic Disaster Recovery は、手頃な価格のストレージ、最小限のコンピューティング、ポイントインタイムリカバリを使用して、オンプレミスおよびクラウドベースのアプリケーションを迅速かつ確実にリカバリすることで、ダウンタイムとデータ損失を最小限に抑えます。
AWS には 4 つのコアとなる DR アーキテクチャパターンがあります。このドキュメントでは、パイロットライト戦略を使用したセットアップ、構成、最適化に焦点を当てています。この戦略は、ソースデータベースからデータを複製するためのレプリケーションサーバーを最初にプロビジョニングし、DR ドリルとリカバリの開始時にのみ実際のデータベースサーバーをプロビジョニングする、低コストの DR 環境を構築するのに役立ちます。この戦略により、DR リージョンでデータベースサーバーを維持する費用が不要になります。代わりに、レプリケーションサーバーとして機能する小規模な EC2 インスタンスの料金のみが発生します。
前提条件と制限
前提条件
アクティブなAWS アカウント
Oracle Database または Microsoft SQL Server 上で実行されている JD Edwards EnterpriseOne アプリケーション。サポートされているデータベースは、マネージド EC2 インスタンスで実行中の状態になっている必要があります。このアプリケーションには、1 つの AWS リージョンにインストールされているすべての JD Edwards EnterpriseOne 基本コンポーネント (エンタープライズサーバー、HTML サーバー、データベースサーバー) が含まれている必要があります。
Elastic Disaster Recovery サービスをセットアップするための AWS Identity and Access Management (IAM) ロール。
必要な接続構成に従って構成されたElastic Disaster Recovery を実行するためのネットワーク。
制約事項
データベースが Amazon Relational Database Service (Amazon RDS) でホストされている場合を除き、このパターンを使用してすべての層を複製できます。その場合は、Amazon RDS のクロスリージョンコピー機能を使用することをお勧めします。
Elastic Disaster Recovery は CloudEndure Disaster Recovery と互換性がありませんが、CloudEndure Disaster Recovery からアップグレードできます。詳細については、「Elastic Disaster Recovery ドキュメント」の「よくある質問」を参照してください。
Amazon Elastic Block Store (Amazon EBS) では、スナップショットを作成できるレートに制限があります。Elastic Disaster Recovery を使用すると、1つのAWS アカウントに最大300台のサーバーを複製できます。より多くのサーバーを複製するには、複数の AWS アカウントまたは複数のターゲット AWS リージョンを使用できます。(Elastic Disaster Recovery はアカウントとリージョンごとに個別に設定する必要があります)。詳細については、「Elastic Disaster Recovery ドキュメント」の「ベストプラクティス」を参照してください。
ソースワークロード (JD Edwards EnterpriseOne アプリケーションとデータベース) は EC2 インスタンスでホストされている必要があります。このパターンは、オンプレミスや他のクラウド環境にあるワークロードをサポートしていません。
このパターンは JD Edwards EnterpriseOne コンポーネントに焦点を当てています。完全な DR と事業継続計画 (BCP) には、次のような他のコアサービスも含める必要があります。
ネットワーク (仮想化プライベートクラウド、サブネット、セキュリティグループ)
アクティブディレクトリ
Amazon WorkSpaces
エラスティックロードバランシング
Amazon Relational Database Service (Amazon RDS) などのマネージド型データベースサービス
前提条件、構成、制限に関する追加情報については、「ElasticDisaster Recoveryドキュメント 」を参照してください。
製品バージョン
Oracle JD Edwards EnterpriseOne (Oracleの最小技術要件に基づく、Oracle と SQL Server がサポートするバージョン)
アーキテクチャ
ターゲットテクノロジースタック
本番用と非本番用の単一リージョンの単一仮想プライベートクラウド (VPC)、およびDR用の2つ目のリージョン
サーバー間のレイテンシーを低く抑えるための単一のアベイラビリティーゾーン
ネットワークトラフィックを分散して、複数のアベイラビリティーゾーンにわたるアプリケーションのスケーラビリティと可用性を向上させる Application Load Balancer
ドメインネームシステム (DNS) 構成を提供する Amazon Route 53
Amazon WorkSpaces は、ユーザーにクラウドによるデスクトップエクスペリエンスを提供します
バックアップ、ファイル、オブジェクトを保存するための Amazon Simple Storage Service (Amazon S3)
Amazon CloudWatch を使用したアプリケーションのロギング、モニタリング、およびアラーム
ディザスタリカバリのための Amazon Elastic Disaster Recovery
ターゲットアーキテクチャ
次の図は、Elastic Disaster Recoveryを使用した JD Edwards EnterpriseOne のクロスリージョンディザスタリカバリアーキテクチャを示しています。
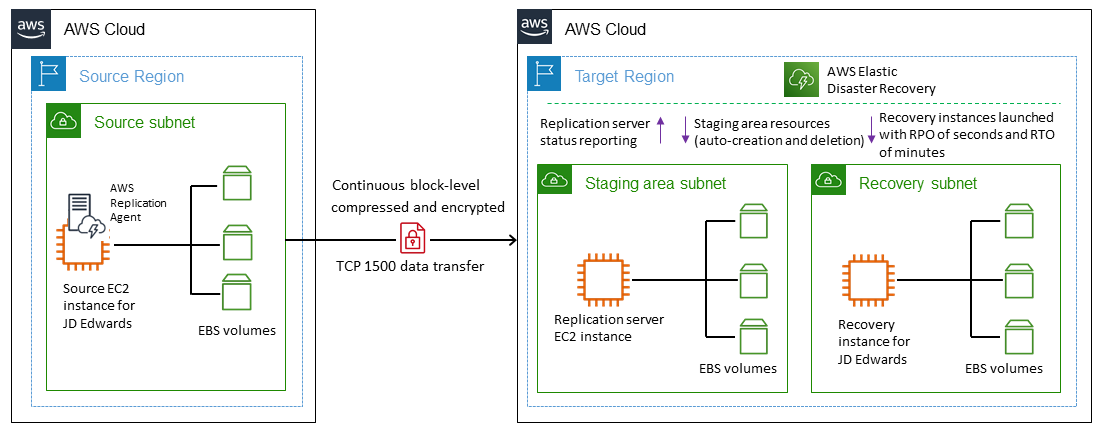
手順
ここでは、プロセスの概要を示します。詳細については、エピックセクションを参照ください。
Elastic Disaster Recovery のレプリケーションは、初回同期から開始します。初回同期中に、AWS Replication Agent はソースディスクのすべてのデータをステージングエリアサブネット内の適切なリソースに複製します。
連続レプリケーションは、初回同期が完了した後も無期限に継続されます。
エージェントをインストールしてレプリケーションを開始したら、サービス固有の構成と Amazon EC2 起動テンプレートを含む起動パラメータを確認します。ソースサーバーがリカバリ準備完了と表示されたら、インスタンスを起動できます。
Elastic Disaster Recovery が起動操作を開始するために一連の API 呼び出しを発行すると、リカバリインスタンスが起動設定に従ってすぐに AWS で起動されます。このサービスはスタートアップ時に自動的に変換サーバーをスピンアップします。
変換が完了して使用できる状態になると、新しいインスタンスが AWS でスピンアップされます。起動時のソースサーバーの状態は、起動したインスタンスに関連付けられたボリュームによって表されます。変換プロセスでは、インスタンスが AWS でネイティブに起動するように、ドライバ、ネットワーク、オペレーティングシステムのライセンスを変更します。
起動後、新しく作成されたボリュームはソースサーバーと同期されなくなります。AWS Replication Agent は、引き続きソースサーバーへの変更をステージングエリアボリュームに定期的に複製しますが、起動されたインスタンスにはそれらの変更は反映されません。
新しいドリルインスタンスまたはリカバリインスタンスを開始すると、データは常にソースサーバーからステージングエリアのサブネットに複製された最新の状態に反映されます。
ソースサーバーがリカバリ準備完了と表示されたら、インスタンスを起動できます。
注記
このプロセスは、プライマリ AWS リージョンから DR リージョンへのフェイルオーバーと、復旧時にプライマリサイトにフェイルバックするという両方の方法で機能します。完全にオーケストレーションされた方法で、ターゲットマシンからソースマシンへのデータレプリケーションの方向を逆転させることで、フェイルバックに備えることができます。
このパターンで説明されているプロセスの利点には次のようなものがあります。
柔軟性: レプリケーションサーバーは、データセットとレプリケーション時間に基づいてスケールアウトとスケールインを行うため、ソースワークロードやレプリケーションを中断することなく DR テストを実行できます。
信頼性: レプリケーションは堅牢で、無停止で、継続的です。
自動化: このソリューションでは、テスト、リカバリ、フェイルバックのための統一された自動化プロセスを実現します。
コストの最適化: 必要なボリュームだけを複製して料金を支払い、DR サイトのコンピュートリソースの料金が発生するのは、それらのリソースが有効化された場合のみです。コスト最適化レプリケーションインスタンス (コンピューティング最適化インスタンスタイプの使用を推奨) は、複数のソース、または大きな EBS ボリュームを持つ単一のソースに使用できます。
自動化とスケール
大規模にディザスタリカバリを実行すると、JD Edwards EnterpriseOne サーバは環境内の他のサーバに依存することになります。以下に例を示します。
起動時に JD Edwards EnterpriseOne がサポートするデータベースに接続する JD Edwards EnterpriseOne アプリケーションサーバーは、そのデータベースに依存しています。
認証が必要で、起動時にドメインコントローラーに接続してサービスを開始する必要がある JD Edwards EnterpriseOne サーバーは、ドメインコントローラーに依存しています。
この理由から、フェイルオーバータスクを自動化することをお勧めします。たとえば、AWS Lambda または AWS Step Functions を使用して JD Edwards EnterpriseOne のスタートアップスクリプトとロードバランサーの変更を自動化することで、エンドツーエンドのフェイルオーバープロセスを自動化できます。詳細については、ブログ記事「 Elastic Disaster Recovery によるスケーラブルなディザスタリカバリ計画の作成
ツール
サービス
Amazon Elastic Block Store (Amazon EBS) は、EC2 インスタンスで使用するためのブロックレベルのストレージボリュームを提供します。
「Amazon Elastic Compute Cloud (Amazon EC2)
」は、AWS クラウドでスケーラブルなコンピューティング容量を提供します。必要な数の仮想サーバーを起動することができ、迅速にスケールアップまたはスケールダウンができます。 Elastic Disaster Recovery
は、手頃な価格のストレージ、最小限のコンピューティング、ポイントインタイムリカバリを使用して、オンプレミスおよびクラウドベースのアプリケーションを迅速かつ確実にリカバリすることで、ダウンタイムとデータ損失を最小限に抑えます。 Amazon Virtual Private Cloud (Amazon VPC)
では、リソースの配置、接続、セキュリティなど、仮想化ネットワーク環境を完全に制御できます。
ベストプラクティス
一般的なベストプラクティス
実際にリカバリイベントが発生した場合にどうするかについて、書面による計画を立ててください。
Elastic Disaster Recoveryを正しく構成した後、必要に応じてオンデマンドで構成を作成できる AWS CloudFormation テンプレートを作成します。サーバーとアプリケーションを起動する順序を決定し、リカバリ計画に記録します。
定期的にドリルを実施してください (Amazon EC2 の標準料金が適用されます)。
Elastic Disaster Recovery コンソールまたはプログラムを使用して、進行中のレプリケーションの状態をモニタリングします。
インスタンスを終了する前に、ポイントインタイムスナップショットを保護して確認してください。
AWS Replication Agent をインストールするための IAM ロールを作成します。
実際の DR シナリオでリカバリインスタンスの終了保護を有効にします。
実際にリカバリイベントが発生した場合でも、リカバリインスタンスを起動したサーバーに対して Elastic Disaster Recovery コンソールの [ との接続解除] アクションを使用しないでください。接続解除を実行すると、ポイントインタイム (PIT) リカバリポイントを含む、これらのソースサーバーに関連するすべてのレプリケーションリソースが終了します。
PIT ポリシーを変更して、スナップショットの保存日数を変更します。
Elastic Disaster Recovery 起動設定の起動テンプレートを編集して、ターゲットサーバーの正しいサブネット、セキュリティグループ、インスタンスタイプを設定します。
Lambda または Step 関数を使用して JD Edwards EnterpriseOne のスタートアップスクリプトとロードバランサーの変更を自動化することで、エンドツーエンドのフェイルオーバープロセスを自動化します。
JD Edwards EnterpriseOne の最適化と考慮事項
PrintQueue をデータベースに移動します。
MediaObjects をデータベースに移動します。
ログと temp フォルダーをバッチサーバーとロジックサーバーから除外します。
Oracle WebLogic から temp フォルダを除外します。
フェイルオーバー後のスタートアップスクリプトを作成します。
SQL Server 用の tempdb を除外します。
Oracle 用の temp ファイルを除外します。
エピック
| タスク | 説明 | 必要なスキル |
|---|---|---|
レプリケーションネットワークをセットアップする。 | JD Edwards EnterpriseOne システムをプライマリ AWS リージョンに実装し、DR 用の AWS リージョンを特定します。「Elastic Disaster Recovery ドキュメント」の「レプリケーションネットワーク要件」セクションの手順に従って、レプリケーションと DR ネットワークの計画と設定を行います。 | AWS 管理者 |
RPO と RTO を決定します。 | アプリケーションサーバーとデータベースの目標復旧時間 (RTO) と目標復旧時点 (RPO) を特定します。 | クラウドアーキテクト、DR アーキテクト |
Amazon EFS のレプリケーションを有効にします。 | 該当する場合は、AWS DataSync、rsync、またはその他の適切なツールを使用して、Amazon Elastic File System (Amazon EFS) などの共有ファイルシステムの AWS プライマリから DR リージョンへのレプリケーションを有効にします。 | クラウド管理者 |
DR が発生した場合は DNS を管理する。 | DRドリルまたは実際のDR中にドメインネームシステム (DNS) を更新するプロセスを特定します。 | クラウド管理者 |
設定用の IAM ロールを作成します。 | 「Elastic Disaster Recovery ドキュメント」の「Elastic Disaster Recovery の初期化と権限」セクションの指示に従って、AWS サービスを初期化および管理するための IAM ロールを作成します。 | クラウド管理者 |
VPC ピアリングのセットアップ | ソース VPC とターゲット VPC がピアリングされ、相互にアクセス可能であることを確認します。構成手順については、Amazon VPC のドキュメントを参照してください。 | AWS 管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
Elastic Disaster Recovery を初期化します。 | Elastic Disaster Recovery コンソール | AWS 管理者 |
レプリケーションサーバーをセットアップします。 |
| AWS 管理者 |
ボリュームとセキュリティグループを構成します。 |
| AWS 管理者 |
その他のブローカーを構成する |
| AWS 管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
IAM ロールを作成します。 |
| AWS 管理者 |
要件を確認します。 | 「Elastic Disaster Recovery ドキュメント」に記載されている、AWS Replication Agent をインストールするための前提条件を確認して完了してください。 | AWS 管理者 |
AWS レプリケーションエージェントをインストールします。 | オペレーティングシステムのインストール手順に従い、AWS Replication Agent をインストールします。
残りのサーバーについても同様のステップを繰り返します。 | AWS 管理者 |
レプリケーションをモニタリングします。 | Elastic Disaster Recovery のソースサーバーペインに戻り、レプリケーションの状態をモニタリングします。データ転送のサイズによっては、初回同期に時間がかかります。 ソースサーバーが完全に同期されると、サーバーの状態は [準備完了] に更新されます。つまり、ステージングエリアにレプリケーションサーバーが作成され、EBS ボリュームがソースサーバーからステージングエリアにレプリケートされたことを意味します。 | AWS 管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
起動設定を編集します。 | ドリルインスタンスとリカバリインスタンスの起動設定を更新するには、Elastic Disaster Recovery コンソール | AWS 管理者 |
一般起動構成を行います。 | 要件に応じて、一般起動設定を修正します。
詳細については、「Elastic Disaster Recovery ドキュメント」の「一般起動設定」を参照してください。 | AWS 管理者 |
Amazon EC2 起動テンプレートを構成します。 | Elastic Disaster Recovery は、Amazon EC2 起動テンプレートを使用して、各ソースサーバーのドリルインスタンスとリカバリインスタンスを起動します。起動テンプレートは、AWS Replication Agent のインストール後、Elastic Disaster Recovery に追加するソースサーバーごとに自動的に作成されます。 Elastic Disaster Recovery で使用する場合は、Amazon EC2 起動テンプレートをデフォルトの起動テンプレートとして設定する必要があります。 詳細については、「Elastic Disaster Recovery ドキュメント」の「EC2 起動テンプレート」を参照してください。 | AWS 管理者 |
| タスク | 説明 | 必要なスキル |
|---|---|---|
ドリルを開始する |
詳細については、「Elastic Disaster Recovery ドキュメント」の「フェイルオーバーの準備」を参照してください。 | AWS 管理者 |
ドリルを検証します。 | 前のステップでは、DR リージョンで新しいターゲットインスタンスを起動しました。ターゲットインスタンスは、起動を開始したときに作成されたスナップショットに基づくソースサーバーのレプリカです。 この手順では、Amazon EC2 ターゲットマシンに接続して、想定どおりに動作していることを確認します。
| |
フェイルオーバーを開始します。 | フェイルオーバーとは、プライマリシステムからセカンダリシステムにトラフィックをリダイレクトすることです。Elastic Disaster Recovery は、AWS でリカバリインスタンスを起動することでフェイルオーバーを実行するのに役立ちます。リカバリインスタンスが起動したら、プライマリシステムからのトラフィックをこれらのインスタンスにリダイレクトします。
詳細については、「Elastic Disaster Recovery ドキュメント」の「フェイルオーバーの実行」を参照してください。 | AWS 管理者 |
フェイルバックを開始します。 | フェイルバックを開始するプロセスは、フェイルオーバーを開始するプロセスと似ています。
詳細については、「Elastic Disaster Recovery ドキュメント」の「フェイルバックの実行」を参照してください。 | AWS 管理者 |
JD Edwards EnterpriseOne コンポーネントを起動する。 |
JD Edwards EnterpriseOne リンクが機能するためには、Route 53 とApplication Load Balancer の変更を組み込む必要があります。 これらのステップは、Lambda、Step Functions、およびSystems Manager (Run Command) を使用して自動化できます。 注記Elastic Disaster Recovery は、オペレーティングシステムとファイルシステムをホストするソース EC2 インスタンス EBS ボリュームのブロックレベルのレプリケーションを実行します。Amazon EFS を使用して作成された共有ファイルシステムは、このレプリケーションには含まれません。最初のエピックで説明したように、AWS DataSync を使用して共有ファイルシステムを DR リージョンに複製し、その複製されたファイルシステムを DR システムにマウントできます。 | JD Edwards EnterpriseOne CNC |
トラブルシューティング
| 問題 | ソリューション |
|---|---|
ソースサーバーのデータレプリケーションステータスが [停止] で、複製が遅延している。詳細を確認すると、データレプリケーションステータスには[エージェントが見つかりません] と表示される。 | 停止したソースサーバーが稼働中であることを確認してください。 注記ソースサーバーがダウンすると、レプリケーションサーバーは自動的に終了します。 遅延の問題については、「Elastic Disaster Recovery ドキュメント」の「レプリケーション遅延の問題」を参照してください。 |
RHEL 8.2 でソース EC2 インスタンスに AWS Replication Agent をインストールしようとしたら、ディスクのスキャン後に失敗した。 | RHEL 8、CentOS 8、または Oracle Linux 8 に AWS Replication Agent をインストールする前に、以下を実行してください。
詳細については、「Elastic Disaster Recovery ドキュメント」の「Linux のインストール要件」を参照してください。 |
Elastic Disaster Recovery コンソールで、ソースサーバーが [準備完了] となって遅延し、データレプリケーションのステータスが [停止中] と表示される。 AWS Replication Agent が使用できない時間によっては、ステータスに大きな遅延と表示される場合があるが、問題は変わらない。 | オペレーティングシステムコマンドを使用して、AWS Replication Agent がソース EC2 インスタンスで実行されていること、またはインスタンスが実行中であることを確認します。 問題を修正すると、Elastic Disaster Recovery はスキャンを再開します。すべてのデータが同期され、レプリケーションステータスが [正常] になるまで待ってから DR ドリルを開始してください。 |
初回のレプリケーションで大きい遅延が発生する。Elastic Disaster Recovery コンソールを見ると、ソースサーバーの初回同期ステータスが非常に遅い。 | 「Elastic Disaster Recovery ドキュメント」の「レプリケーション遅延の問題」セクションに記載されているレプリケーション遅延の問題を確認してください。 レプリケーションサーバーは、組み込み関数が原因で負荷を処理できない場合があります。その場合は、AWS テクニカルサポートチーム |
関連リソース
Elastic Disaster Recovery によるスケーラブルなディザスタリカバリ計画の作成
(AWS ブログ記事) Elastic Disaster Recovery - 技術入門
(AWS スキルビルダーコース、ログインが必要)
