翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ユーザー定義関数の最適化
のユーザー定義関数 (UDFs) と RDD.map では、パフォーマンスが大幅に低下することが PySpark よくあります。これは、Spark の基盤となる Scala 実装で Python コードを正確に表すために必要なオーバーヘッドが原因です。
次の図は、 PySpark ジョブのアーキテクチャを示しています。を使用する場合 PySpark、Spark ドライバーは Py4j ライブラリを使用して Python から Java メソッドを呼び出します。Spark SQLまたは DataFrame 組み込み関数を呼び出す場合、Python と Scala のパフォーマンスの違いはほとんどありません。関数は、最適化された実行プランJVMを使用して各エグゼキュターの で実行されるためです。
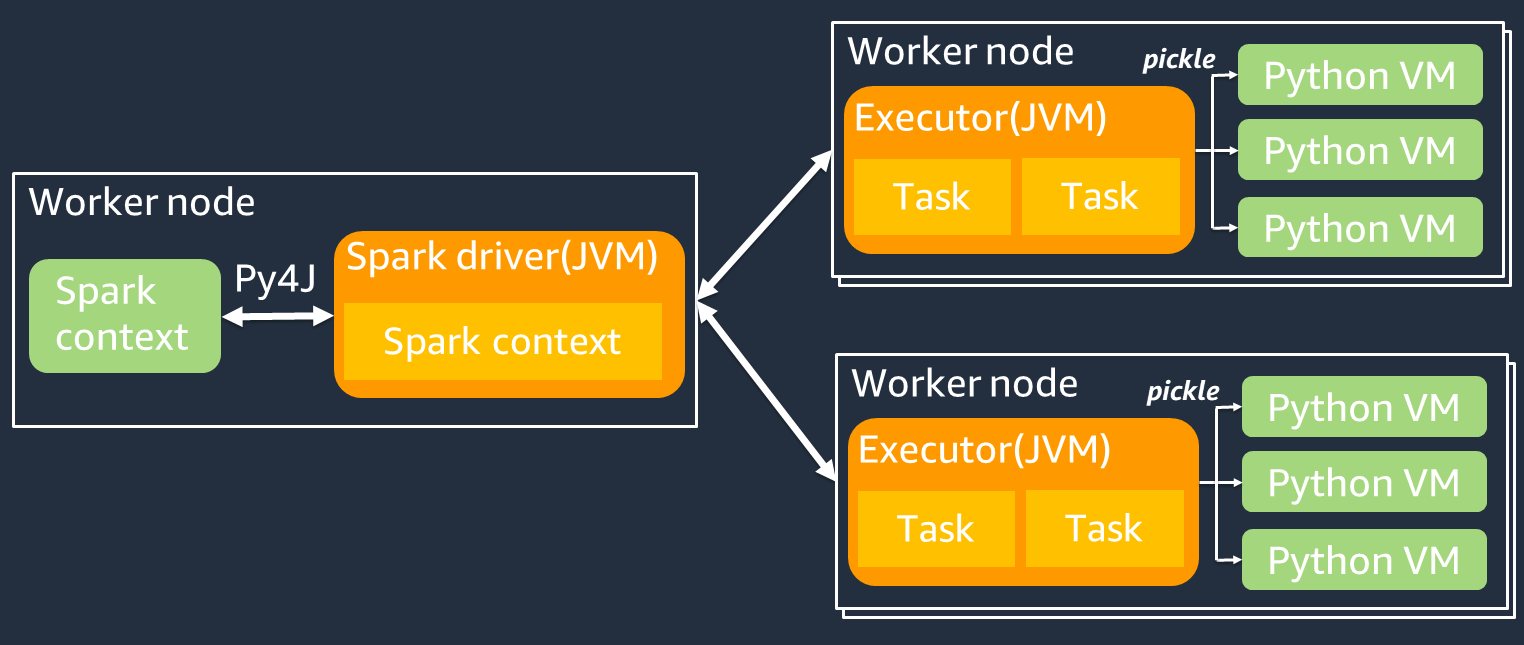
の使用など、独自の Python ロジックを使用する場合map/ mapPartitions/ udf、タスクは Python ランタイム環境で実行されます。2 つの環境を管理すると、オーバーヘッドコストが発生します。さらに、JVMランタイム環境の組み込み関数で使用するには、メモリ内のデータを変換する必要があります。Pickle は、デフォルトで JVMと Python ランタイム間の交換に使用されるシリアル化形式です。ただし、このシリアル化と逆シリアル化のコストは非常に高くなるため、Java または Scala でUDFs記述される方が Python よりも高速ですUDFs。
のシリアル化と逆シリアル化のオーバーヘッドを回避するには PySpark、次の点を考慮してください。
-
組み込みの Spark SQL関数を使用する — 独自の UDFまたはマップ関数を Spark SQLまたは DataFrame組み込み関数に置き換えることを検討してください。Spark SQLまたは DataFrame 組み込み関数を実行する場合、タスクは各エグゼキュターの で処理されるため、Python と Scala のパフォーマンスの違いはほとんどありませんJVM。
-
Scala または Java UDFsで実装する — Java または Scala で記述UDFされた を使用することを検討してください。これらは で実行されるためですJVM。
-
ベクトル化されたワークロードUDFsに Apache Arrow ベースを使用する – Arrow ベースの の使用を検討してくださいUDFs。この機能はベクトル化 UDF (Pandas ) とも呼ばれますUDF。Apache Arrow
は言語に依存しないインメモリデータ形式であり、 を使用して JVMと Python プロセス間でデータを効率的に転送 AWS Glue できます。これは現在、Pandas または NumPyデータを操作する Python ユーザーにとって最も有益です。 矢印は列指向 (ベクトル化) 形式です。その使用は自動ではなく、設定やコードにわずかな変更を加えることで、互換性を最大限に引き出すことができます。詳細と制限については、「」の「Apache Arrow PySpark
」を参照してください。 次の例では、UDF標準の Python、ベクトル化された 、UDFSpark の基本的な増分を比較しますSQL。
標準 Python UDF
時間の例は 3.20 (秒) です。
コードの例
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
実行計画
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
ベクトル化 UDF
時間の例は 0.59 (秒) です。
ベクトル化された UDFは、前のUDF例の 5 倍高速です。を確認するとPhysical Plan、 が表示されます。これはArrowEvalPython、このアプリケーションが Apache Arrow によってベクトル化されていることを示しています。ベクトル化された を有効にするにはUDF、コードspark.sql.execution.arrow.pyspark.enabled = trueで を指定する必要があります。
コードの例
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
実行計画
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Spark SQL
時間の例は 0.087 (秒) です。
タスクSQLは Python ランタイム JVMなしで各エグゼキュターの で実行されるためUDF、Spark はベクトル化された よりもはるかに高速です。UDF を組み込み関数に置き換えることができる場合は、置き換えることをお勧めします。
コードの例
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
ビッグデータに pandas を使用する
すでに pandas
