Amazon Redshift は、パッチ 198 以降、新しい Python UDF の作成をサポートしなくなります。既存の Python UDF は、2026 年 6 月 30 日まで引き続き機能します。詳細については、ブログ記事
SVL_QUERY_SUMMARY ビューの使用
SVL_QUERY_SUMMARY を使用して、クエリの概要情報をストリームで分析するには、以下を実行します。
-
次のクエリを実行してクエリ ID を調べます。
select query, elapsed, substring from svl_qlog order by query desc limit 5;substringフィールドの切り捨てられたクエリテキストを調べ、どのquery値がクエリを表しているかを確認します。クエリを複数回実行した場合、query値が小さい行のelapsed値を使用します。これは、コンパイル済みバージョンの行です。多くのクエリを実行している場合、クエリが確実に含められるように、LIMIT 句により使用される値を大きくすることができます。 -
クエリの SVL_QUERY_SUMMARY から行を選択します。結果をストリーム、セグメント、ステップ順に並べ替えます。
select * from svl_query_summary where query = MyQueryID order by stm, seg, step;結果の例は次のとおりです。
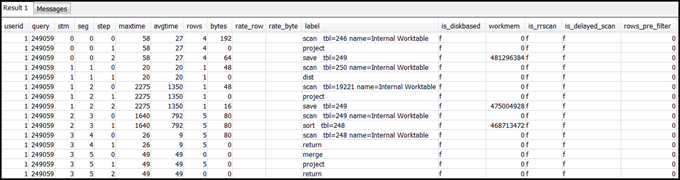
-
「クエリの概要へのクエリプランのマッピング」の情報を使用して、クエリプラン内の操作にステップをマッピングします。これらは、列およびバイト (クエリプランの行 x 幅) の値とほぼ同じになります。大きく異なる場合、「テーブル統計がないか古い」で推奨される解決策を参照してください。
-
is_diskbasedフィールドに、ステップのt値がある (true) かどうかを調べます。ハッシュ、集計、およびソートは、システムでクエリ処理に十分なメモリが割り当てられていない場合に、ディスクにデータを書き込む可能性が高い演算子です。is_diskbasedが true の場合、「クエリに割り当てられてメモリが不十分」で推奨される解決策を参照してください。 -
labelフィールドの値を確認し、ステップのいずれかの場所に AGG-DIST-AGG シーケンスがあるかどうかを調べます。ある場合、コストの高い 2 ステップの集約であることを示しています。これを修正するには、GROUP BY 句を変更して分散キー (複数ある場合は 1 番目のキー) を使用します。 -
各セグメントの
maxtime値を確認します (セグメントのすべてのステップ間で同じです)。maxtime値が最も大きいセグメントを特定し、このセグメント内のステップで次の演算子を確認します。注記
maxtime値が大きくても、セグメントに問題があるとは限りません。値が大きくても、セグメントの処理に時間がかからないことがあります。ストリーム内のすべてのセグメントは同時に開始します。ただし、ダウンストリームセグメントによっては、アップストリームセグメントからデータを取得するまで実行できません。そのセグメントのmaxtime値には待機時間と処理時間の両方が含まれるため、この効果により長時間かかるように見えることがあります。-
BCAST または DIST: これらの場合、
maxtime値が大きいと多数の行が再分散される可能性があります。推奨される解決策については、「十分最適でないデータ分散」を参照してください。 -
HJOIN (ハッシュ結合): 問題のステップの
rowsフィールド内の値が、クエリ内の最後の RETURN ステップのrows値と比較して非常に大きい場合、「ハッシュ結合」で推奨される解決策を参照してください。 -
SCAN/SORT: 結合ステップの直前にあるステップの SCAN、SORT、SCAN、MERGE シーケンスを探します。このパターンは、未ソートのデータがスキャン、ソートされた後、テーブルのソート済み領域とマージされます。
SCAN ステップの行の値が、クエリ内の最後の RETURN ステップにある行の値と比較して非常に大きいかどうかを確認します。このパターンは、後で破棄される行を実行エンジンがスキャンしていることを示します (非効率的です)。推奨される解決策については、「述語の制限が不十分」を参照してください。
SCAN ステップの
maxtime値が大きい場合、「十分最適でない WHERE 句」で推奨される解決策を参照します。SORT ステップの
rows値がゼロ以外の場合、「未ソート行または正しくソートされていない行」で推奨される解決策を参照してください。
-
-
最後の RETURN ステップの前にある 5~10 個のステップの
rows値とbytes値を確認し、クライアントに返されるデータの量を調べます。このプロセスには少し工夫が必要です。例えば、次のクエリの概要では、3 番目の PROJECT ステップにより
bytes値ではなくrows値が提供されています。先行するステップで同じrows値を持つステップを探すと、行とバイトの両方の情報を提供する SCAN ステップが見つかります。結果の例を次に示します。
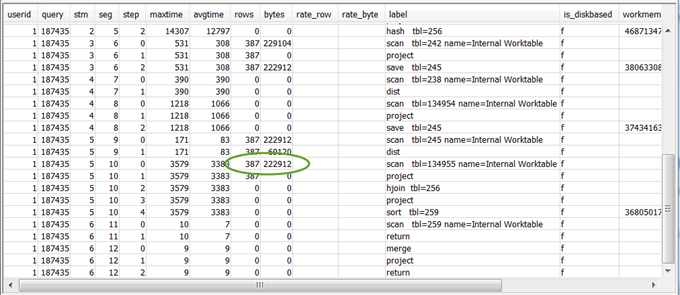
非常に大量のデータを返す場合、「非常に大きな結果セット」で推奨される解決策を参照してください。
-
他のステップと比較して、いずれかのステップの
bytes値がrows値より大きいかどうかを確認します。このパターンは、多くの列を選択していることを示す場合があります。推奨される解決策については、「大きい SELECT リスト」を参照してください。
