バキューム処理時間の最小化
Amazon Redshift は、背景で自動的にデータをソートし、VACUUM DELETE を実行します。これにより、VACUUM コマンドを実行する必要が少なくなります。バキューム処理は時間がかかる可能性があります。データの特性に応じて、バキューム処理時間を最小化するために、以下のプラクティスをお勧めします。
インデックスを再生成するかどうかの決定
多くの場合、インターリーブソート方式を使用することで、クエリのパフォーマンスを大幅に向上させることができますが、時間の経過とともに、ソートキー列の値の分散が変わった場合、パフォーマンス低下につながることがあります。
最初に COPY または CREATE TABLE AS を使用して空のインターリーブテーブルをロードすると、Amazon Redshift は自動的にインターリーブインデックスを構築します。最初に INSERT を使用してインターリーブテーブルをロードする場合は、その後に VACUUM REINDEX を実行して、インターリーブインデックスを初期化する必要があります。
時間の経過と共に、新しいソートキー値を持つ行を追加するにつれて、ソートキー列の値の分布が変更されると、パフォーマンスが低下する可能性があります。新しい行が既存のソートキー値の範囲内に主に存在する場合、インデックスを再作成する必要はありません。VACUUM SORT ONLY あるいは VACUUM FULL を実行して、ソート順序を復元します。
クエリエンジンはソート順を使用して、クエリの処理用にスキャンする必要のあるデータブロックを効率的に選択できます。インターリーブソートの場合、Amazon Redshift はソートキー列の値を分析して、最適なソート順を決定します。行が追加されて、キー値の分散が変わった、つまりスキューが発生した場合、ソート方法は最適でなくなり、ソートのパフォーマンス低下につながります。ソートキーの分散を再分析するには、VACUUM REINDEX を実行できます。REINDEX オペレーションには時間がかかるため、テーブルに対してインデックスの再生成が有効かどうかを決定するには、SVV_INTERLEAVED_COLUMNS ビューのクエリを実行します。
例えば、以下のクエリを実行すると、インターリーブソートキーを使用するテーブルについて詳細が表示されます。
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
interleaved_skew の値はスキューの量を示す比率です。値が 1 の場合、スキューがないことを意味します。スキューが 1.4 よりも大きい場合、基とするセットからのスキューでなければ、VACUUM REINDEX により通常はパフォーマンスが向上します。
last_reindex で日付値を使用して、前回のインデックス再生成から経過した時間を調べることができます。
未ソートリージョンのサイズを管理する
データがすでに含まれているテーブルに大量の新しいデータをロードするか、定期的な保守管理操作の一環としてテーブルのバキューム処理を実行しないとき、未ソートのリージョンが増えます。長時間のバキューム操作を避けるために、以下の手法を利用できます。
-
定期的なスケジュールでバキューム操作を実行します。
(テーブルの合計行数の少ないパーセンテージを表す毎日の更新など) 少ない増分でテーブルをロードする場合、VACUUM を定期的に実行すると、個別のバキューム操作が短時間で終了します。
-
最も大きなロードを最初に実行します。
複数の COPY 操作で新しいテーブルをロードする必要がある場合、最も大きなロードを最初に実行します。新しいテーブルまたはTRUNCATE されたテーブルに初回ロードを実行すると、すべてのデータがソート済みリージョンに直接ロードされます。そのため、バキュームは必要ありません。
-
すべての行を削除するのではなく、テーブルの全データを削除します (Truncate)。
テーブルから行を削除した場合、その行が占有していた領域はバキューム操作を実行するまで再利用されません。ただし、テーブルの全データを削除した(Truncate)場合、テーブルが空になり、ディスク領域が再利用されます。そのため、バキュームは必要ありません。または、テーブルを削除し (Drop)、再作成します。
-
テストテーブルの全データを削除するか、テーブル自体を削除します。
テスト目的で少ない数の行をテーブルにロードする場合、完了時に行を削除しないでください。代わりに、テーブルの全データを削除し、後続の本稼働のロード操作の一環としてこれらの行を再ロードします。
-
ディープコピーを実行します。
複合ソートキーテーブルを使用するテーブルにソートされていない大きなリージョンがある場合、ディープコピーがバキュームよりずっと高速です。ディープコピーでは、一括挿入を使用してテーブルが再作成され、再設定されます。これにより、テーブルが自動的に再ソートされます。テーブルにソートされていない大規模なリージョンがある場合、ディープコピーの方がバキューム処理より高速です。欠点としては、ディープコピー処理中は同時更新を実行できません。バキューム処理では実行できます。詳細については、「Amazon Redshift クエリの設計のベストプラクティス」を参照してください。
マージ済みの行のボリューム管理
バキューム操作で新しい行をテーブルのソート済みリージョンにマージする必要がある場合、バキュームに必要な時間はテーブルが大きくなるにつれて長くなります。マージが必要な行の数を少なくすると、バキュームのパフォーマンスが向上します。
バキューム処理前のテーブルは、最初にソート済みリージョン、その後ろに未ソートのリージョンで構成され、未ソート領域は行の追加または更新が行われると大きくなります。COPY 操作で行のセットが追加された場合、新しい行のセットは、テーブルの最後の未ソート領域に追加されたときにソートキーでソートされます。新しい行は、未ソートリージョン内ではなく固有のセット内で順序付けされます。
次の図は、2 つの連続する COPY 操作後の未ソートのリージョンを示しています。ソートキーは CUSTID です。分かりやすいように、この例では複合ソートキーを示していますが、インターリーブテーブルにより未ソートリージョンの影響が大きくならなければ、同じ原則はインターリーブソートキーにも当てはまります。
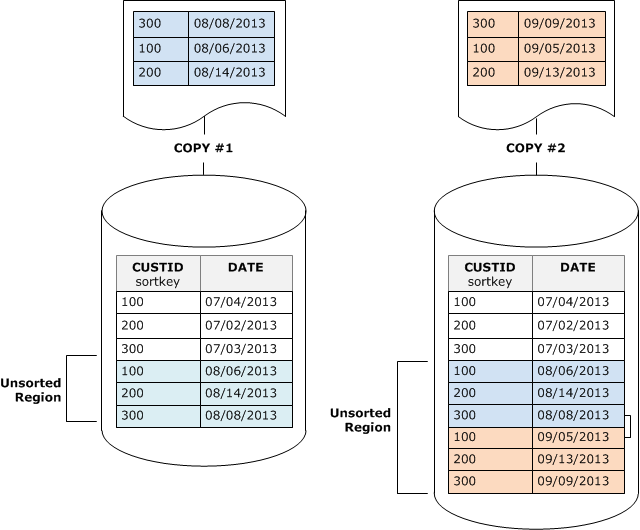
バキュームにより、2 つのステージでテーブルのソート順が元に戻ります。
-
未ソートのリージョンを新しくソートされたリージョンにソートします。
最初のステージでは未ソートのリージョンのみが書き換えられるため、比較的低コストです。新しくソートされたリージョンのソートキーの値の範囲が既存の範囲を超えた場合、新しい行のみを書き換える必要があり、バキュームは完了します。例えば、ソート済みリージョンに 1~500 の ID 値が含まれ、それ以降のコピーオペレーションで追加されたキーの値が 500 を超えた場合は、未ソートのリージョンのみを書き換える必要があります。
-
新しくソートされたリージョンと前にソートされたリージョンをマージします。
新しくソートされたリージョンのキーとソート済みリージョンのキーが重複する場合は、VACUUM で行をマージする必要があります。新しくソートされたリージョンの先頭から開始すると (最も低いソートキーで)、バキュームにより、前にソートされたリージョンおよび新しくソートされたリージョンからマージされた行が新しいブロックのセットに書き込まれます。
新しいソートキーの範囲と既存のソートキーが重複する範囲により、再度書き込む必要のあるソート済みリージョンの範囲が決まります。未ソートのキーが既存のソート範囲全体に分散する場合は、バキュームにより、テーブルの既存部分を再度書き込む必要があります。
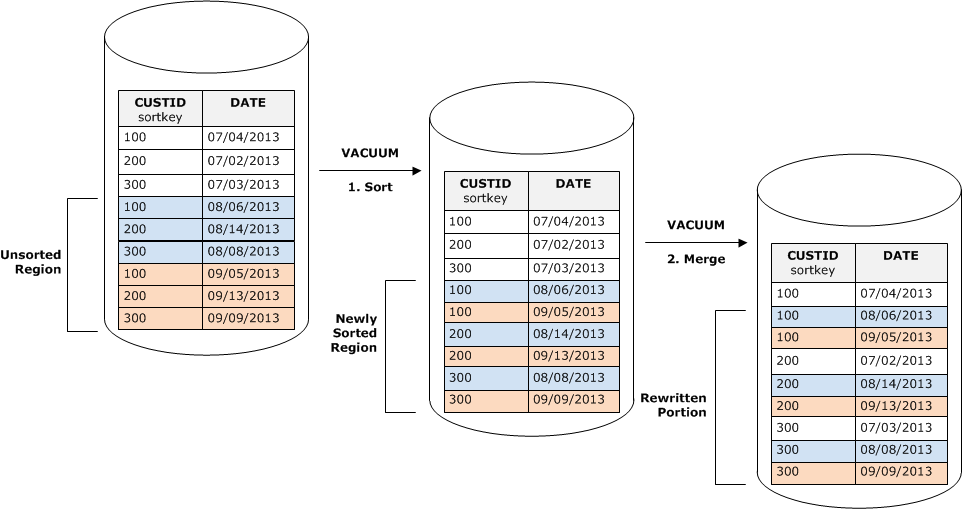
次の図は、テーブルに追加された行をバキュームによってソートおよびマージする方法を示しています。CUSTID はソートキーです。各コピー操作により、既存のキーと重複するキー値を持つ新しい行セットが追加されるため、テーブルのほぼ全体を再度書き込む必要があります。図に示されているのは単一のソートとマージですが、実際には、大規模なバキュームは一連の差分ソートおよびマージステップから成ります。
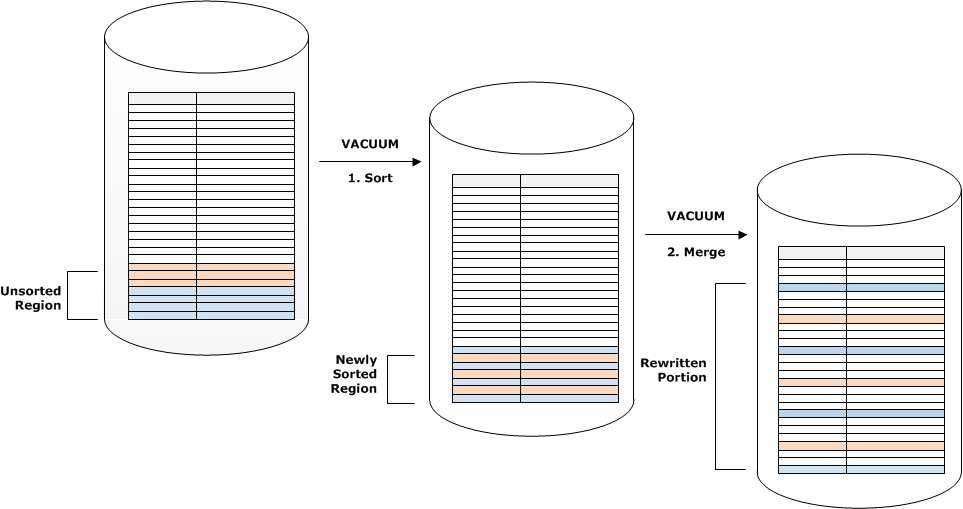
新しい行のセットのソートキーの範囲が既存のキーの範囲と重複する場合、マージステージのコストは、テーブルが大きくなると、テーブルサイズに比例して大きくなります。一方、ソートステージのコストは、未ソートリージョンのサイズに比例したままとなります。このような場合、次の図に示すように、マージステージのコストはソートステージのコストを上回ります。
テーブルのどれだけの部分が再マージされたかを特定するには、バキューム操作が完了した後で SVV_VACUUM_SUMMARY のクエリを行います。次のクエリは、CUSTSALES が時間の経過と共に大きくなったときに、6 回連続でバキュームを実行した場合の効果を示します。
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
merge_increments 列は、バキューム操作ごとにマージされたデータの量を示します。連続バキュームを超えるマージインクリメントの数がテーブルサイズの増加と比例して増えた場合は、既存のソート済みリージョンと新たにソートされるリージョンが重複するため、バキューム操作ごとにテーブル内の行数が増加して再マージされていることを示します。
ソートキー順序でデータをロードする
COPY コマンドを使用してソートキー順序でデータをロードする場合、バキューム処理の必要性が減少するか、なくなることもあります。
COPY では、以下のすべてが該当する場合に、テーブルのソート済みリージョンに自動的に新しい行が追加されます。
-
テーブルでは、1 つのソート列のみで複合ソートキーが使用されます。
-
ソート列は NOT NULL です。
-
テーブルは 100% ソート済みであるか空です。
-
すべての新しい行は、既存の行 (削除対象としてマークされた行も含む) よりソート順が高くなっています。この場合、Amazon Redshift では、ソートキーの最初の 8 バイトを使用してソート順が決定されます。
例えば、顧客 ID と時刻を使用して顧客イベントを記録するテーブルがあるとします。顧客 ID でソートする場合は、前の例に示すとおり、差分ロードによって新たに追加された行のソートキー範囲が既存の範囲と重複し、コストの高いバキューム操作につながる可能性があります。
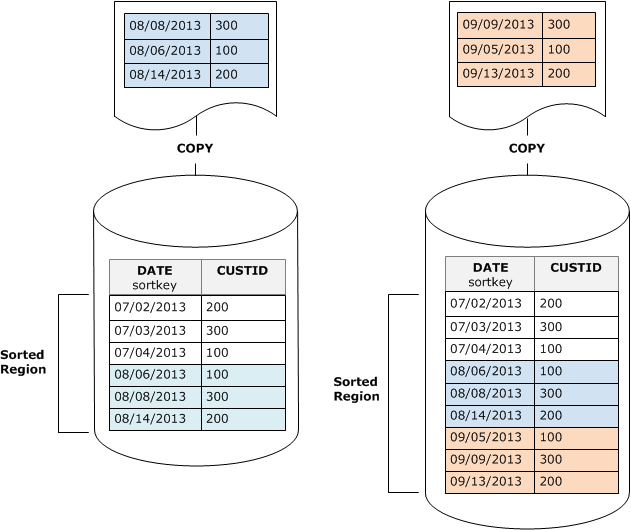
タイムスタンプ列にソートキーを設定する場合、新しい行は、次の図に示すとおり、テーブルの末尾にソート順で追加されるため、バキュームの必要が減少するか、なくなります。
時系列テーブルを使用して保存データを削減する
ローリング期間のデータを保持する場合は、次の図に示すとおり、一連のテーブルを使用します。

データセットを追加するたびに新しいテーブルを作成して、シリーズの最も古いテーブルを削除します。次のような二重の利点があります。
-
DROP TABLE 操作は大量の DELETE よりもはるかに効率的であるため、行を削除する余分なコストを避けることができます。
-
テーブルがタイムスタンプでソートされる場合は、バキュームは必要ではありません。各テーブルに 1 か月のデータが含まれる場合、テーブルがタイムスタンプでソートされていない場合でも、バキュームで最大でも 1 か月分のデータを再書き込みする必要があります。
レポーティングクエリで使用するために、UNION ALL ビューを作成し、データが複数のテーブルに保存されているという事実を隠すことができます。クエリがソートキーでフィルタリングされる場合は、クエリプランナーは使用されないすべてのテーブルを効率的にスキップできます。その他の種類のクエリでは UNION ALL の効率が下がる可能性があるため、テーブルを使用するすべてのクエリのコンテキストでクエリパフォーマンスを評価してください。
