翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Autopilot データ探索レポート
Amazon SageMaker Autopilot はデータセットを自動的にクリーンアップして前処理します。高品質のデータにより、機械学習をより効率的に行い、より正確に予測を行うモデルを作成できます。
顧客が提供するデータセットには、ある程度のドメイン知識がないと自動的に修正できない問題があります。例えば、回帰問題に対するターゲット列の外れ値が大きいと、外れ値以外の値に対して最適さに欠ける予測が発生する可能性があります。モデリングの目的によっては、外れ値の削除が必要になることがあります。ターゲット列が誤って入力特徴の 1 つとして含まれている場合、最終モデルは適切に検証されますが、将来の予測にはほとんど価値がありません。
このような問題を顧客が検出できるように、Autopilot は、データの潜在的な問題に関するインサイトを含むデータ探索レポートを提供しています。レポートでは、問題の対処方法も提示されています。
レポートを含むデータ探索ノートブックは、すべての Autopilot ジョブに対して生成されます。レポートは Amazon S3 バケットに保存され、出力パスからアクセスできます。データ探索レポートのパスは通常、次のパターンに従います。
[s3 output path]/[name of the automl job]/sagemaker-automl-candidates/[name of processing job used for data analysis]/notebooks/SageMakerAutopilotDataExplorationNotebook.ipynb
データ探索ノートブックの場所は、 に保存されているDescribeAutoMLJobオペレーションレスポンスAPIを使用して Autopilot から取得できますDataExplorationNotebookLocation。
SageMaker Studio Classic から Autopilot を実行する場合、次のステップを使用してデータ探索レポートを開くことができます。
-
左側のナビゲーションペイン
 からホームアイコンを選択すると、最上位の Amazon SageMaker Studio Classic ナビゲーションメニューが表示されます。
からホームアイコンを選択すると、最上位の Amazon SageMaker Studio Classic ナビゲーションメニューが表示されます。 -
メインワークエリアから [AutoML] カードを選択します。これにより、新しい [Autopilot] タブが開きます。
-
[名前] セクションで、調べたいデータ探索ノートブックを含む Autopilot ジョブを選択します。これにより、新しい [Autopilot ジョブ] タブが開きます。
-
[Autopilot ジョブ] タブの右上のセクションから [データ探索ノートブックを開く] を選択します。
データ探索レポートは、トレーニングプロセスの開始前にデータから生成されます。これにより、意味のない結果につながる可能性のある Autopilot ジョブを停止できます。同様に、Autopilot を再実行する前にデータセットの問題や改善に対処できます。このように、より適切にキュレートされたデータセットでモデルをトレーニングする前に、ドメインの専門知識を活用してデータ品質を手動で改善できます。
データレポートには静的マークダウンのみが含まれており、どの Jupyter 環境でも開くことができます。レポートを含むノートブックは、 PDFや などの他の形式に変換できますHTML。変換の詳細については、「Using the nbconvert script to convert Jupyter notebooks to other formats
データセットの概要
この[データセットの概要] では、行数、列数、重複行の割合、および欠落している目標値を含め、データセットを特徴付ける主要な統計情報を提供します。これは、Amazon SageMaker Autopilot が検出したデータセットに問題があり、介入が必要になる可能性がある場合に、クイックアラートを提供することを目的としています。インサイトは、重要度が「高」または「低」に分類される警告として示されます。分類は、問題がモデルのパフォーマンスに悪影響を与えることを示す信頼度に依存します。
重要度が高と低のインサイトは概要にポップアップ表示されます。ほとんどのインサイトの場合、データセットに注意を要する問題があることを確認する方法についてレコメンデーションが提供されます。また、これらの問題の解決方法に関する提案も提供されます。
Autopilot は、データセット内の欠落したターゲット値や無効なターゲット値に関する追加の統計を提供し、重要度の高いインサイトではキャプチャされないような他の問題を検出できるようにします。特定タイプの列が予期しない数である場合は、使用する列の一部がデータセットから欠落している可能性があります。また、データを準備または保存する方法に問題があったことを示している可能性もあります。Autopilot によって知らされるこれらのデータの問題を修正することにより、データでトレーニングされた機械学習モデルのパフォーマンスを向上させることができます。
重要度の高いインサイトは、レポートの概要セクションと、他の関連するセクションに表示されます。通常、データレポートのセクションに応じて、重要度の高い/低いインサイトの例が示されます。
ターゲット分析
このセクションには、ターゲット列の値の分布に関連して、重要度が高い/低いさまざまなインサイトが表示されます。ターゲット列に正しい値が含まれていることを確認してください。ターゲット列の値が間違っていると、機械学習モデルが意図したビジネス目的に役立たない可能性があります。このセクションには、重要度が高い/低いデータインサイトがいくつかあります。次にいくつかの例を示します。
-
外れターゲット値 - 裾の重いターゲットなど、回帰に対する歪んだまたは異常なターゲット分布。
-
高いまたは低いターゲット基数 - 分類のクラスラベルの頻度が小さいか、一意のクラス数が非常に大きい。
回帰および分類の両方の問題タイプで、数値の無限、NaN、ターゲット列の空白などの無効な値が表示されます。問題タイプに応じて異なるデータセット統計が表示されます。回帰問題に対するターゲット列の値の分布により、分布が期待どおりであるかどうかを簡単に検証できます。
次のスクリーンショットは、データセット内の外れ値の平均、中央値、最小値、最大値、パーセンテージなどの統計を含む Autopilot データレポートを示しています。スクリーンショットには、ターゲット列のラベルの分布を示すヒストグラムも含まれています。ヒストグラムでは、横軸にターゲット列の値、縦軸に個数が表示されます。スクリーンショットの外れ値の割合セクションがボックスで強調表示され、この統計が表示されている場所を示しています。
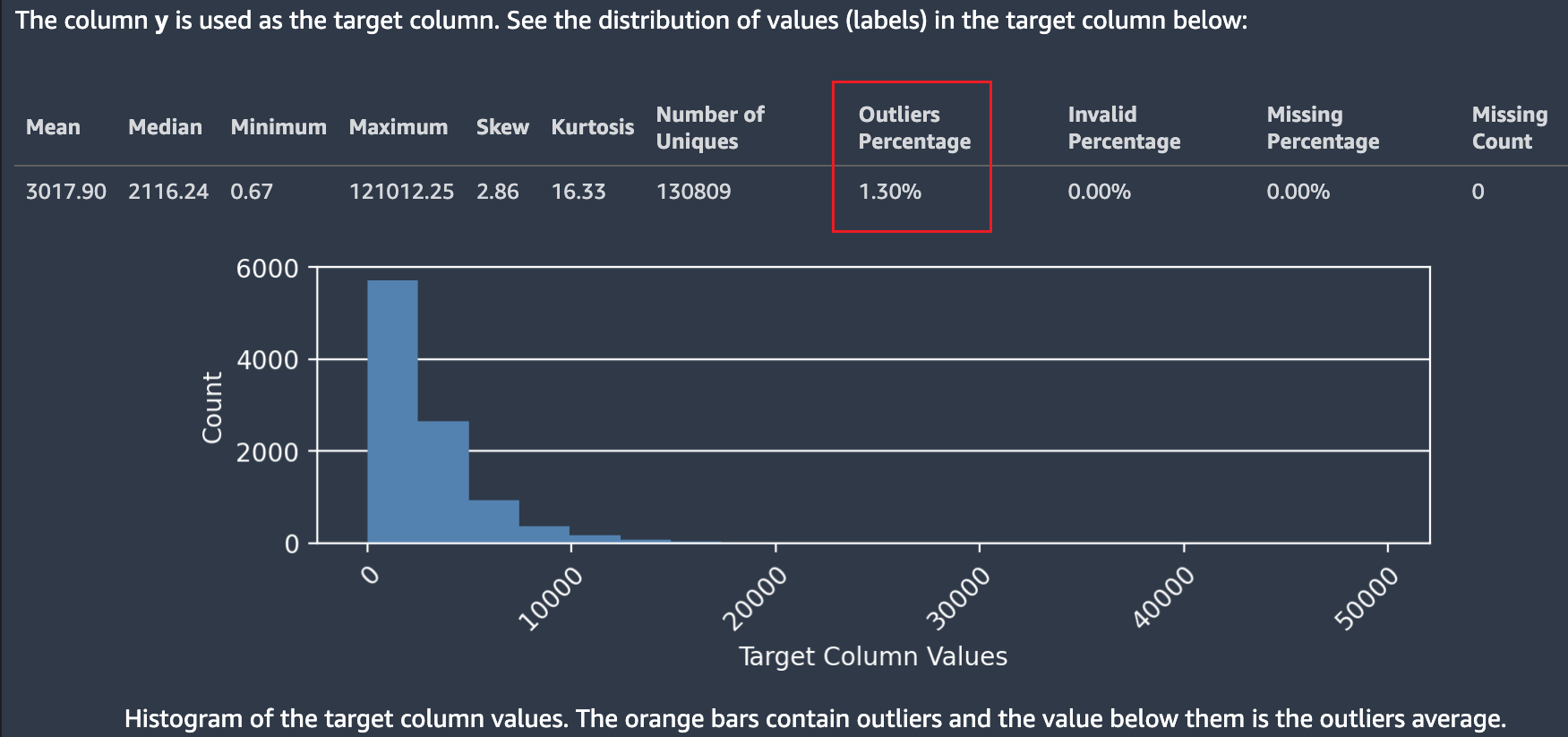
ターゲット値とその分布に関する複数の統計が表示されます。外れ値、無効な値、または欠落している値の割合のいずれかがゼロより大きい場合、その値が表示され、使用できないターゲット値がデータに含まれている理由を調査できます。一部の使用できないターゲット値は、重要度が低いインサイト警告として強調表示されます。
次のスクリーンショットでは、「`」記号が誤ってターゲット列に追加されたため、ターゲットの数値が解析されなくなっています。重要度が低いインサイト: 「無効なターゲット値」という警告が表示されています。この例の警告は次のとおりです: 「ターゲット列のラベルの 0.14% は数値に変換できませんでした。最も一般的な数値以外の値には、["-3.8e-05","-9-05","-4.7e-05","-1.4999999999999999e-05","-4.3e-05"] があります。これは通常、データの収集または処理に問題があることを示しています。Amazon SageMaker Autopilot は、無効なターゲットラベルを持つすべての観測を無視します。」

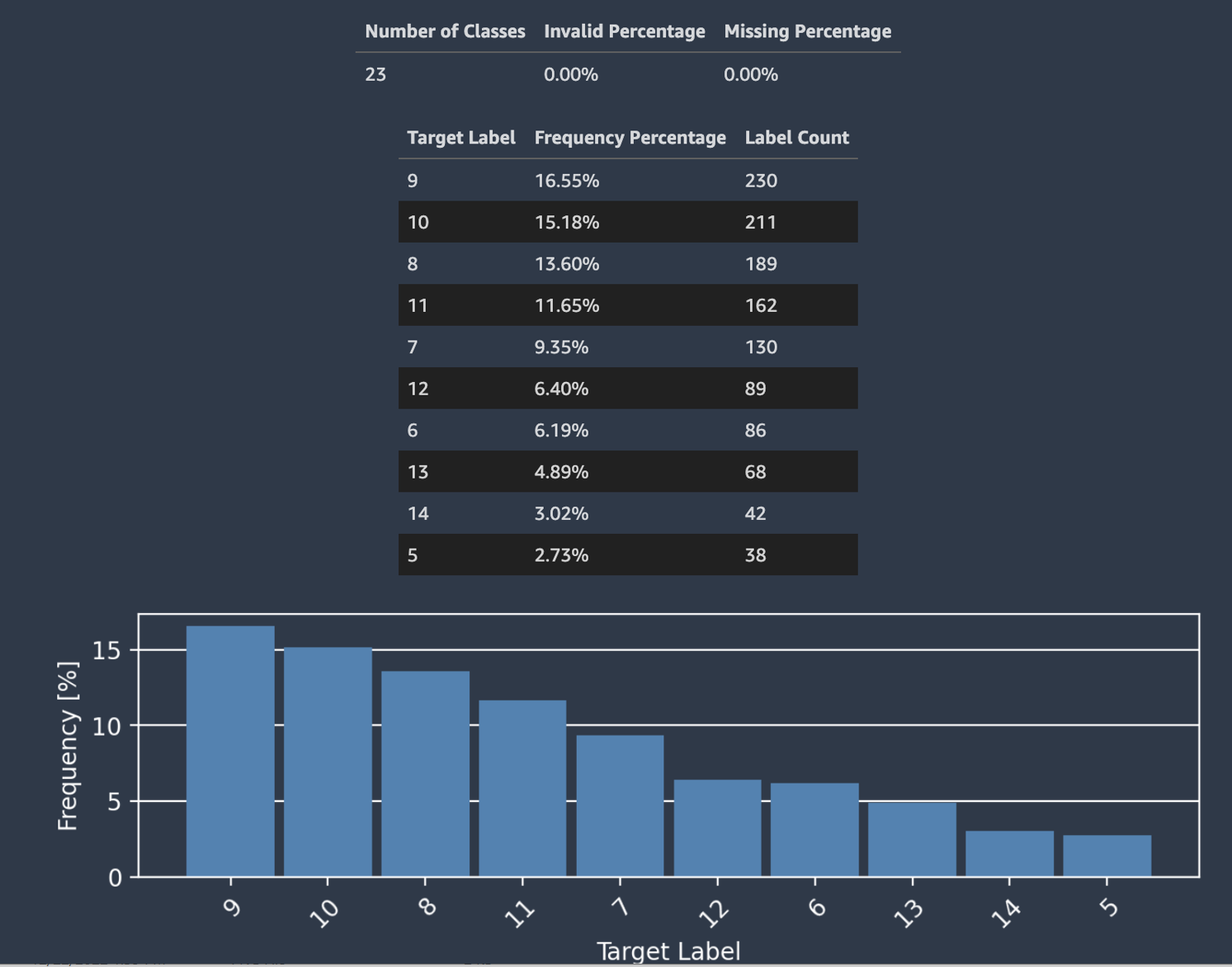
Autopilot では、分類のラベルの分布を示すヒストグラムも提供されます。
次のスクリーンショットは、クラス数、欠落している値、または無効な値など、ターゲット列に与えられた統計の例を示しています。横軸がターゲットラベル、縦軸が頻度のヒストグラムで、各ラベルカテゴリの分布を示しています。
注記
このセクションおよびその他のセクションに記載されているすべての用語の定義は、レポートノートブックの下部にある [Definitions] (定義) セクションで確認できます。
データサンプル
Autopilot は、データセットの問題の特定に役立つ実際のデータのサンプルを提示します。サンプルテーブルは水平方向にスクロールします。サンプルデータを調べて、必要な列すべてがデータセットに存在することを確認してください。
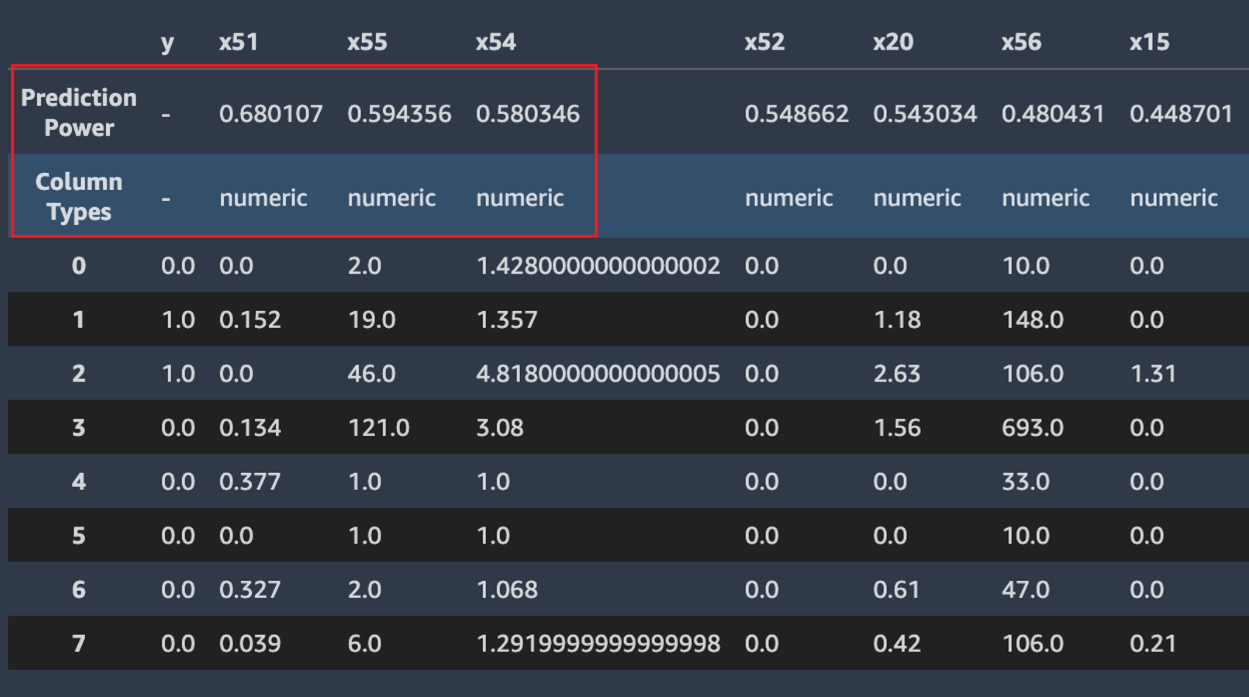
Autopilot では予測能力のメジャーも計算されるため、特徴量とターゲット変数の間の線形または非線形の関係を識別できます。値が 0 の場合、その特徴量にはターゲット変数の予測において予測値がないことを示します。値が 1 の場合は、ターゲット変数の予測能力が最も高いことを示しています。予測能力の詳細については、[定義] セクションを参照してください。
注記
特徴量の重要度の代わりに予測能力を使用することはお勧めしません。予測能力がユースケースに適切なメジャーであることがはっきりしている場合にのみ使用してください。
次のスクリーンショットは、データサンプルの例を示しています。一番上の行にはデータセットの各列の予測能力が含まれています。2 行目には列のデータ型が含まれています。以降の行にはラベルが含まれます。列にはターゲット列、各特徴量列が続きます。各特徴量列には関連付けられた予測能力があり、このスクリーンショットではボックスで強調表示されています。この例では、特徴量 x51 を含む列にはターゲット変数 y に対して 0.68 の予測能力があります。特徴量 x55 は、0.59 の予測能力より予測がわずかに小さくなります。
重複行
データセットに重複する行が存在する場合、Amazon SageMaker Autopilot はそれらのサンプルを表示します。
注記
Autopilot に提供する前に、アップサンプリングによってデータセットをバランスさせることは推奨されません。これを行うと、Autopilot によってトレーニングされたモデルの検証スコアが正しくなくなり、生成されたモデルが使用できなくなる可能性があります。
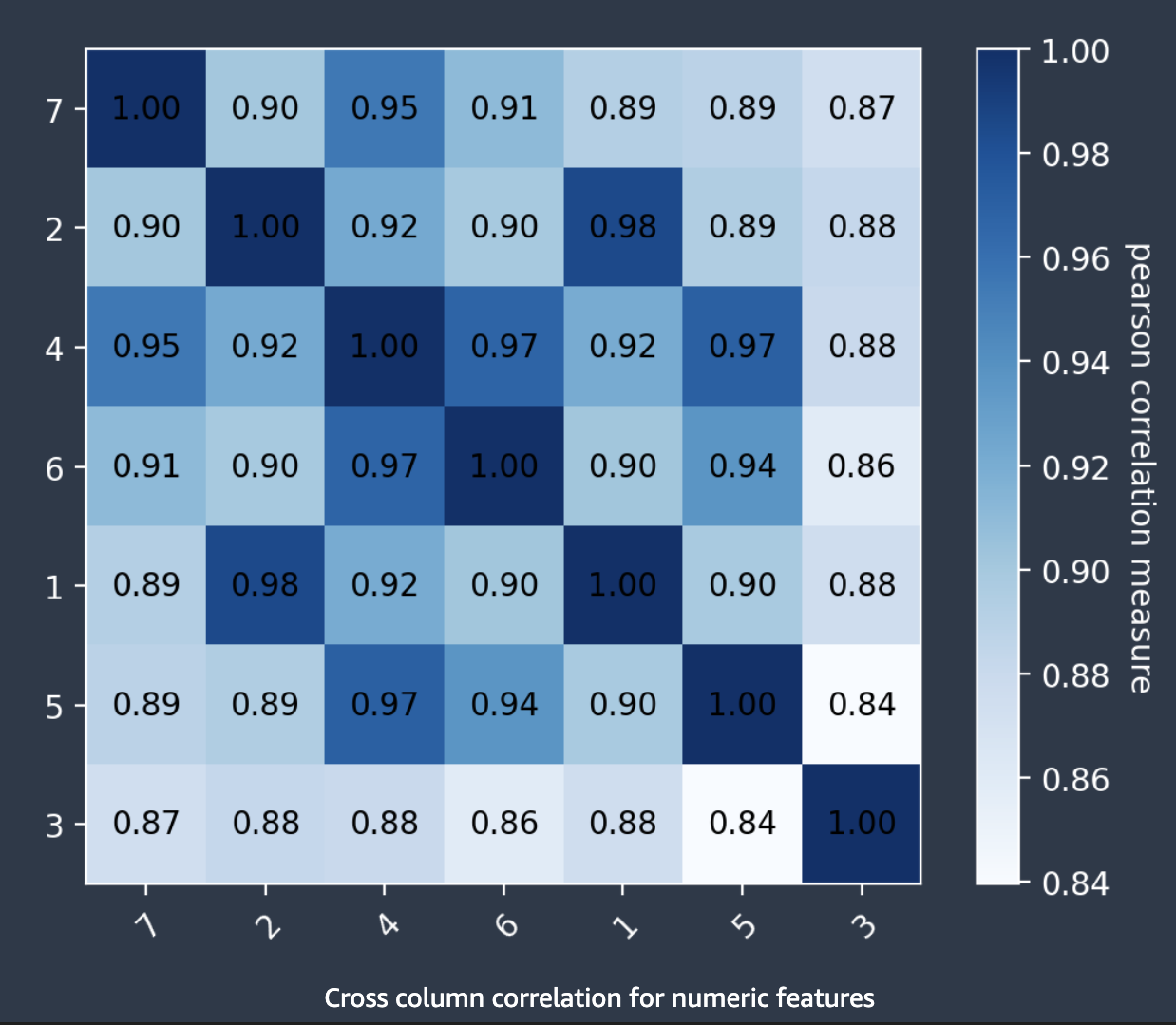
相互相関列
Autopilot は、2 つの特徴量間の線形相関の尺度であるピアソンの相関係数を使用して相関行列を作成します。相関行列では、数値の特徴量が横軸と縦軸の両方にプロットされ、ピアソンの相関係数はそれらの交点にプロットされます。2 つの特徴量間の相関が高ければ係数も大きくなり、最大値は |1| です。
-
値が
-1の場合、特徴量には完全に負の相関があることを示します。 -
値が
1の場合、特徴量がそれ自体と相関関係にあり、完全に正の相関があることを示します。
相関行列の情報を使用して、高い相関関係にある特徴量を削除できます。特徴の数が少ないほど、モデルの過剰適合の可能性が少なくなり、2 つの方法で運用コストを削減できます。これにより、必要な Autopilot ランタイムが少なくなり、アプリケーションによってはデータ収集手順をより安価に実行できます。
次のスクリーンショットは、7 つの特徴量間の相関行列の例を示しています。各特徴量は、横軸と縦軸の両方に行列として表示されています。ピアソンの相関係数は 2 つの特徴量が交差する場所に表示されています。各特徴量が交差する場所には、関連付けられた色調が表示されています。相関が高いほど色調は濃くなります。最も濃い色調は行列の対角線上にあり、各特徴量はそれ自体と相関関係にあり、完全な相関があることを示しています。
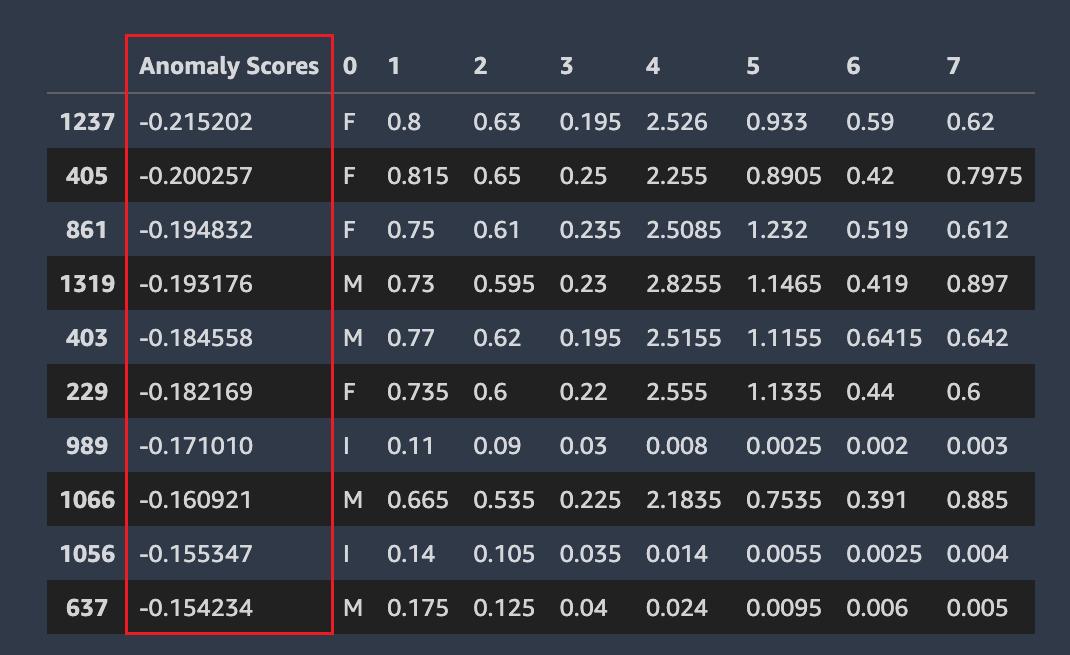
異常な行
Amazon SageMaker Autopilot は、データセット内のどの行が異常であるかを検出します。次に、各行に異常スコアを割り当てます。負の異常スコアがある行は、異常とみなされます。
次のスクリーンショットは、異常を含む行に関する Autopilot 分析からの出力を示しています。各行のデータセット列の横に、異常なスコアを含む列が表示されています。
欠損値、濃度、記述統計
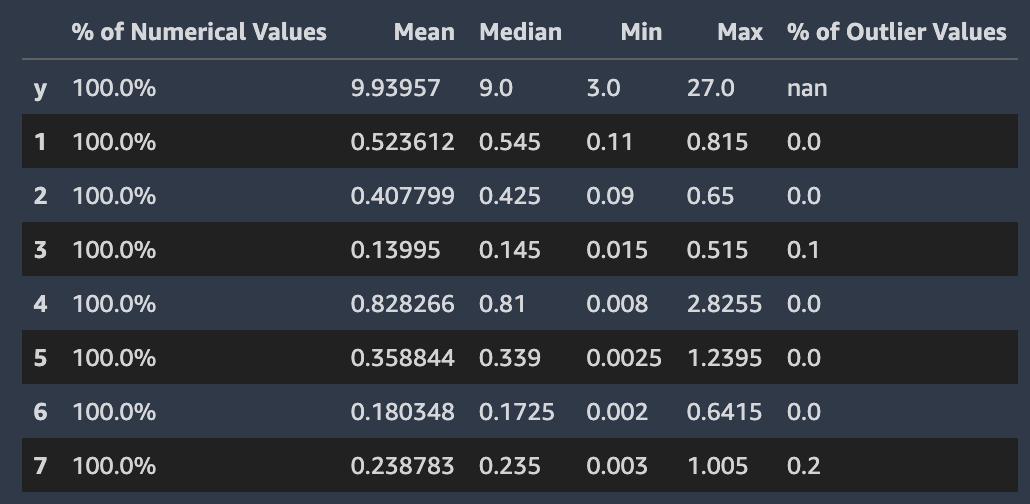
Amazon SageMaker Autopilot は、データセットの個々の列のプロパティを調べてレポートします。この分析を示すデータレポートの各セクションでは、コンテンツが順番に並べられています。これは、最も「疑わしい」値を最初にチェックできるようにするためです。この統計を使用することで、個々の列のコンテンツを改善し、Autopilot が生成するモデルの品質を向上させることができます。
Autopilot は、これらが含まれる列のカテゴリ値に関するいくつかの統計を計算します。これには、ユニークなエントリの数とユニークな単語の数 (テキストの場合) が含まれます。
Autopilot は、これらが含まれる列の数値に関するいくつかの標準統計を計算します。次の図は、平均値、中央値、最小値と最大値、数値タイプおよび外れ値の割合を含む統計を示しています。