翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
予測結果を入力レコードに関連付ける
大きなデータセットで予測を行う場合、予測に不要な属性を除外できます。予測を行った後で、除外した属性の一部をそれらの予測と関連付けたり、レポート内の他の入力データと関連付けたりすることができます。バッチ変換を使用してこれらのデータ処理ステップを実行することで、多くの場合、追加の前処理や後処理を排除できます。入力ファイルは JSON 形式と CSV 形式でのみ使用できます。
推論を入力レコードに関連付けるワークフロー
次の図は、推論を入力レコードに関連付けるワークフローを示しています。
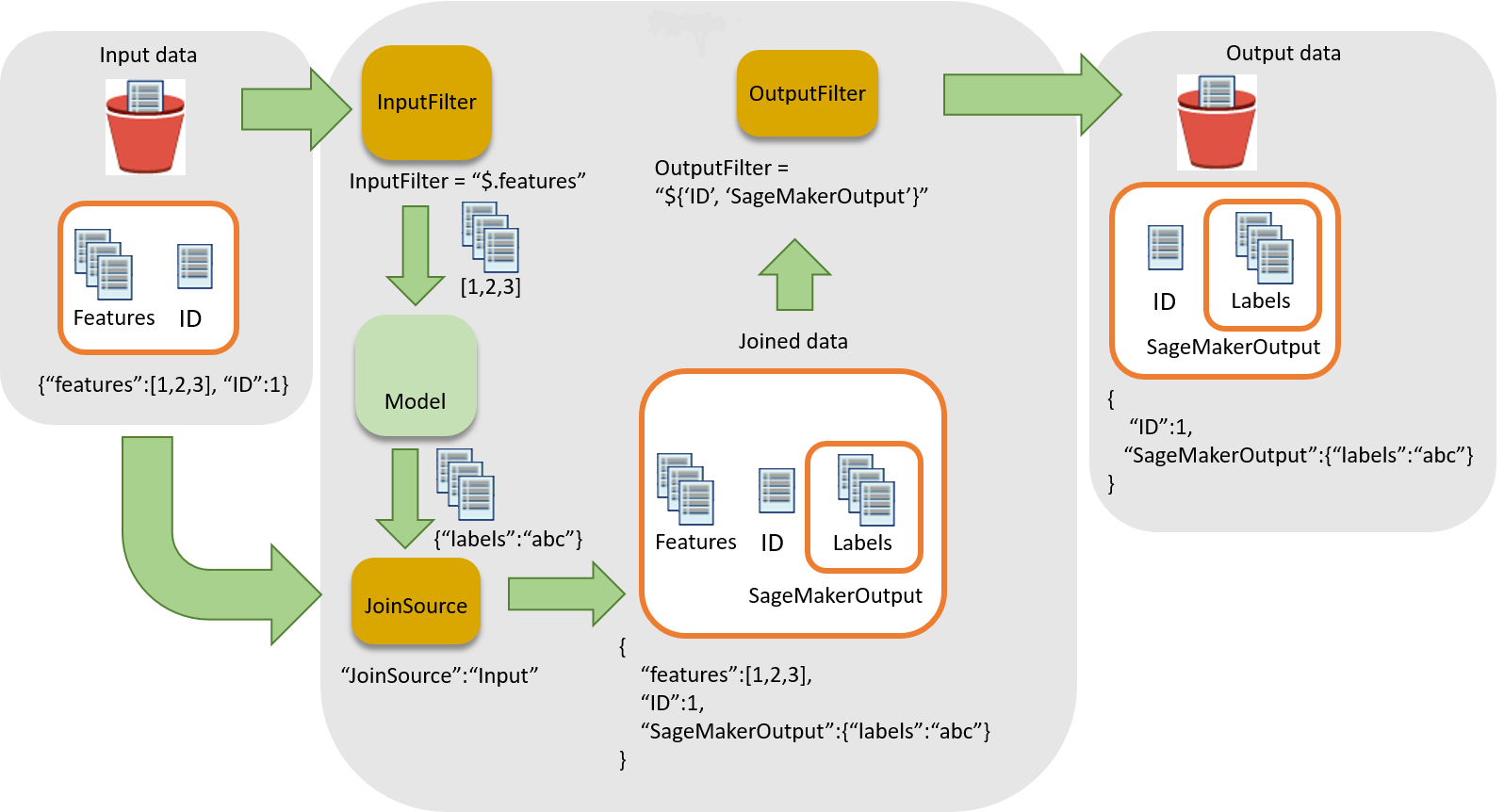
推論を入力データに関連付けるには、主に 3 つのステップがあります。
-
入力データをバッチ変換ジョブに渡す前に、推論に不要な入力データをフィルタリングします。
InputFilterパラメータを使用して、モデルの入力として使用する属性を決定します。 -
入力データを推論結果に関連付けます。
JoinSourceパラメータを使用して、入力データと推論を結合します。 -
結合したデータをフィルタリングして、レポート内の予測を解釈するためのコンテキストの提供に必要な入力を保持します。
OutputFilterを使用して、結合データセットの指定部分を出力ファイルに格納します。
バッチ変換ジョブでのデータ処理の使用
CreateTransformJob でバッチ変換ジョブを作成してデータを処理する場合:
-
DataProcessingデータ構造内のInputFilterパラメータを使用して、モデルに渡す入力部分を指定します。 -
JoinSourceパラメータを使用して、生の入力データを変換されたデータと結合します。 -
出力ファイルに含める結合入力部分と、バッチ変換ジョブからの変換済みデータを、
OutputFilterパラメータで指定します。 -
JSON または CSV 形式のファイルを選択して入力します。
-
JSON 形式または JSON Lines 形式の入力ファイルの場合、SageMaker AI は
SageMakerOutput属性を入力ファイルに追加するか、SageMakerInput属性とSageMakerOutput属性を使用して新しい JSON 出力ファイルを作成します。詳細については、「DataProcessing」を参照してください。 -
CSV 形式の入力ファイルの場合、結合された入力データの後に変換済みデータが続き、CSV ファイルとして出力されます。
-
DataProcessingDataProcessing 構造でアルゴリズムを使用する場合は、入力ファイルと出力ファイルの両方で、選択した形式がサポートされている必要があります。例えば、CreateTransformJob API の TransformOutput フィールドの ContentType パラメータと Accept パラメータの両方を text/csv、application/json、application/jsonlines のいずれかの値に設定する必要があります。CSV ファイルの列を指定する構文と JSON ファイルの属性を指定する構文は異なります。誤った構文を使用すると、エラーが発生します。詳細については、「バッチ変換の例」を参照してください。組み込みアルゴリズムの入力ファイルと出力ファイルの形式の詳細については、「Amazon SageMaker の組み込みアルゴリズムと事前トレーニング済みモデル」を参照してください。
入力と出力のレコード区切り文字も、選択したファイルの入力と一致している必要があります。SplitType パラメータは、入力データセットのレコードを分割する方法を示しています。AssembleWith パラメータは、出力用にレコードを再構成する方法を示します。入力および出力形式を text/csv に設定した場合は、SplitType および AssembleWith パラメータも line に設定する必要があります。入力形式および出力形式を application/jsonlines に設定した場合は、SplitType と AssembleWith の両方を line に設定できます。
CSV ファイルの場合、埋め込まれた改行文字は使用できません。JSON ファイルの場合、属性名 SageMakerOutput は出力用に予約されています。JSON 入力ファイルにこの名前の属性を含めることはできません。含めた場合、入力ファイルのデータは上書きされる可能性があります。
サポートされる JSONPath 演算子
入力データと推論をフィルタリングして結合するには、JSONPath 部分式を使用します。SageMaker AI は定義された JSONPath 演算子のサブセットのみをサポートします。次の表に、サポートされる JSONPath 演算子を示します。CSV データの場合、各行は JSON 配列と見なされるため、インデックスベースの JSONPath のみを適用できます (例: $[0]、$[1:])。CSV データも RFC 形式
| JSONPath 演算子 | 説明 | 例 |
|---|---|---|
$ |
クエリするルート要素。この演算子は、すべてのパス式の先頭に必要です。 |
$ |
. |
ドット表記の子要素。 |
|
* |
ワイルドカード。属性名または数値の代わりに使用します。 |
|
[' |
大括弧で表記された要素または複数の子要素。 |
|
[ |
インデックスまたはインデックスの配列。負のインデックス値もサポートされています。 |
|
[ |
配列のスライス演算子。array slice () メソッドは、配列のセクションを抽出し、新しい配列を返します。 |
|
角かっこ表記を使用して特定のフィールドの複数の子要素を指定する場合、かっこ内に子のネストを追加することはサポートされていません。たとえば、$.field1.['child1','child2'] はサポートされますが、$.field1.['child1','child2.grandchild'] はサポートされません。
JSONPath 演算子の詳細については、GitHub の「JsonPath
バッチ変換の例
次の例は、入力データと予測結果を結合するための一般的な方法を示しています。
トピック
例 : 推論のみを出力する
デフォルトでは、DataProcessing パラメータは推論結果を入力と結合しません。推論結果のみが出力されます。
結果を入力と結合しないように明示的に指定する場合、Amazon SageMaker Python SDK
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
AWS SDK for Python を使用して推論を出力するには、CreateTransformJob リクエストに次のコードを追加します。以下のコードは、デフォルトの動作を模倣しています。
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
例: 入力データと結合した推論を出力する
Amazon SageMaker Python SDKassemble_with パラメータと accept パラメータを指定します。変換呼び出しを使用するときは、join_source パラメータに Input を指定し、split_type パラメータおよび content_type パラメータも指定します。split_type パラメータは assemble_with と同じ値、content_type パラメータは accept と同じ値である必要があります。パラメータと許容値の詳細については、Amazon SageMaker AI Python SDK の「Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
AWS SDK for Python (Boto 3) を使用している場合は、次のコードをCreateTransformJobリクエストに追加して、すべての入力データを推論に結合します。Accept と ContentType の値は一致する必要があり、AssembleWith と SplitType の値も一致する必要があります。
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
JSON または JSON Lines の入力ファイルの場合、結果は入力 JSON ファイルの SageMakerOutput キーにあります。たとえば、入力がキーと値のペア {"key":1} を含む JSON ファイルである場合、データ変換の結果は {"label":1} です。
SageMaker AI は、両方を SageMakerInput キーの入力ファイル内に保存します。
{ "key":1, "SageMakerOutput":{"label":1} }
注記
JSON の結合結果は、キーと値のペアのオブジェクトである必要があります。入力がキーと値のペアのオブジェクトではない場合、SageMaker AI は新しい JSON ファイルを作成します。新しい JSON ファイルで、入力データは SageMakerInput キー内に保存され、結果は SageMakerOutput 値として保存されます。
たとえば、CSV ファイルで、レコードが [1,2,3] で、ラベルの結果が [1] の場合、出力ファイルには [1,2,3,1] が含まれます。
例: 入力データと結合された推論を出力し、ID 列を入力から除外する (CSV)
Amazon SageMaker Python SDKinput_filter に前の例と同じパラメータと JSONPath サブエクスプレッションを指定します。例えば、入力データに 5 つの列があり、最初の 1 つが ID 列である場合、次の変換リクエストを使用して、ID 列を除 くすべての列を特徴として選択します。トランスフォーマーは引き続き、推論と結合されたすべての入力列を出力します。パラメータと許容値の詳細については、Amazon SageMaker AI Python SDK の「Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
AWS SDK for Python (Boto 3) を使用している場合は、 CreateTransformJobリクエストに次のコードを追加します。
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
SageMaker AI の列を指定するには、配列要素のインデックスを使用します。最初の列はインデックス 0、2 番目の列はインデックス 1、6 番目の列はインデックス 5 です。
入力から最初の列を除外するには、InputFilter を "$[1:]" に設定します。コロン (:) は、2 つの値の間のすべての要素を含めるように SageMaker AI に指示します。たとえば、$[1:4] は 2 番目から 5 番目の列を指定します。
コロンの後の数字を省略すると ([5:] など)、サブセットには 6 番目の列から最後の列までのすべての列が含まれます。コロンの前の数字、たとえば [:5] を省略すると、サブセットには最初の列 (インデックス 0) から 6 番目の列までのすべての列が含まれます。
例: ID 列と結合された推論を出力し、入力から ID 列を除外する (CSV)
Amazon SageMaker Python SDKoutput_filter を指定することで、特定の入力列 (ID 列など) のみを推論と結合するように出力を指定できます。output_filter は JSONPath サブ式を使用して、入力データを推論結果と結合した後に出力として返す列を指定します。次のリクエストは、ID 列を除外して予測を行い、ID 列を推論と結合する方法を示しています。次の例では、出力の最後の列 (-1) に推論が含まれていることに注意してください。JSON ファイルを使用している場合、SageMaker AI は推論結果を属性 SageMakerOutput に保存します。パラメータと許容値の詳細については、Amazon SageMaker AI Python SDK の「Transformer
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
AWS SDK for Python (Boto 3) を使用している場合は、次のコードをCreateTransformJobリクエストに追加して、ID 列のみを推論と結合します。
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
警告
JSON 形式の入力ファイルを使用している場合、ファイルに属性名 SageMakerOutput を含めることはできません。この属性名は出力ファイルの推論用に予約されています。この名前の属性が JSON 形式の入力ファイルに含まれていると、入力ファイルの値が推論で上書きされる場合があります。
