翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデル構築用のデータを準備する
注記
SageMaker Canvas で Data Wrangler を使用して高度なデータ準備を実行できるようになりました。これにより、自然言語インターフェイスと 300 を超える組み込み変換が提供されます。詳細については、「データ準備」を参照してください。
機械学習データセットでは、モデルを構築する前にデータの準備が必要な場合があります。欠損値や外れ値などの問題が含まれる可能性のあるデータをクリーンアップし、特徴量エンジニアリングを実行してモデルの精度を向上させます。Amazon SageMaker Canvas は、ML データ変換を提供し、モデル構築のためにデータをクリーンアップ、変換、準備できます。これらの変換は、コードなしでデータセットで使用できます。 SageMaker Canvas は、使用する変換をモデルレシピ に追加します。これは、モデルを構築する前にデータに対して実行されたデータ準備の記録です。使用するデータ変換は、モデル構築用の入力データのみを変更し、元のデータソースは変更しません。
データセットのプレビューには、データセットの最初の 100 行が表示されます。データセットが 20,000 行を超える場合、Canvas は 20,000 行のランダムサンプリングを行い、そのサンプルの最初の 100 行をプレビューに表示します。プレビューに表示された行に対してのみ検索と指定を行うことができ、フィルター機能はプレビューに表示された行のみに適用され、データセット全体には適用されません。
SageMaker Canvas では、構築用のデータを準備するために、次の変換を使用できます。
注記
高度な変換は、表形式のデータセットに基づいて構築されたモデルにのみ使用できます。マルチカテゴリテキスト予測モデルも対象外です。
列をドロップする
Canvas アプリケーションの Build SageMaker タブに列を削除することで、モデルビルドから列を除外できます。ドロップする列の選択を解除すると、その列はモデル構築時に含まれません。
注記
列を削除してモデルでバッチ予測を行う場合、 SageMaker Canvas は削除された列を利用可能な出力データセットに追加します。ただし、 SageMaker Canvas は、削除された列を時系列モデルに追加しません。
行をフィルタリングする
フィルター機能は、指定した条件に基づいてプレビューされた行 (データセットの最初の 100 行) をフィルタリングします。行をフィルタリングすると、データの一時的なプレビューが作成され、モデル構築には影響しません。フィルター機能を使用して、欠損値のある行、外れ値を含む行、または選択した列のカスタム条件を満たす行をプレビューできます。
欠損値で行をフィルタリングする
欠落値は、機械学習データセットで一般的に見られます。特定の列に null または空の値がある行がある場合は、それらの行をフィルタリングしてプレビューすることができます。
プレビューしたデータの欠損値をフィルターするには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行でフィルタリング () を選択します
 。
。 -
欠損値の有無を確認する [列] を選択します。
-
[操作] で [欠損] を選択します。
SageMaker 選択した列に欠損値を含む行の Canvas フィルター。フィルタリングされた行のプレビューを提供します。

外れ値で行をフィルタリングする
外れ値、またはデータの分布と範囲のまれな値は、モデルの精度に悪影響を及ぼし、構築時間が長くなる可能性があります。 SageMaker Canvas を使用すると、数値列に外れ値を含む行を検出してフィルタリングできます。外れ値は、標準偏差またはカスタム範囲のいずれかで定義できます。
データ内の外れ値をフィルタリングするには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行でフィルタリング () を選択します
。 -
外れ値の有無を確認する [列] を選択します。
-
[操作] で [外れ値] を選択します。
-
[外れ値の範囲] を [標準偏差] または [カスタム範囲] に設定します。
-
[標準偏差] を選択した場合は、1~3 の [SD] (標準偏差) 値を指定します。[カスタム範囲] を選択した場合は、[パーセント] または [数値] を選択して、[最小] と [最大] の値を指定します。
[標準偏差] オプションでは、平均値と標準偏差を使用して数値列の外れ値を検出してフィルタリングします。値を外れ値と見なすために必要な平均値からの変化として、標準偏差の値を指定します。例えば、[SD] で 3 を指定すると、外れ値と見なすためには、平均値から 3 標準偏差より低い値である必要があります。
[カスタム範囲] オプションでは、最小値と最大値を使用して数値列の外れ値を検出してフィルタリングします。外れ値を定義するしきい値がわかっている場合は、この方法を使用します。範囲の [タイプ] は、[パーセント] または [数値] に設定できます。[パーセント] を選択した場合、[最小] と [最大] には、許容するパーセント範囲 (0~100) の最小値と最大値を指定します。[数値] を選択した場合、[最小] と [最大] には、データでフィルタリングする最小値と最大値を指定します。

カスタム値で行をフィルタリングする
カスタム条件を満たす値を含む行をフィルタリングできます。例えば、価格が 100 を超える行を削除する前にプレビューする場合などです。この機能を使用すると、設定したしきい値を超える行をフィルタリングし、フィルタリングされたデータをプレビューできます。
カスタムフィルター機能を使用するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行でフィルタリング () を選択します
。 -
確認する [列] を選択します。
-
使用する [操作] タイプを選択して、選択した条件の値を指定します。
[操作] では、以下のオプションのいずれかを選択できます。使用できる操作は、選択する列のデータ型に応じて異なる場合があります。例えば、テキスト値を含む列には is greater than 操作は作成できません。
| 操作 | サポートされているデータ型 | サポート対象の特徴量タイプ | 機能 |
|---|---|---|---|
|
と等しい |
数値、テキスト |
バイナリ、カテゴリ |
[列] の値が指定した値と等しい行をフィルタリングします。 |
|
と等しくない |
数値、テキスト |
バイナリ、カテゴリ |
[列] の値が指定した値と等しくない行をフィルタリングします。 |
|
未満 |
数値 |
該当なし |
[列] の値が指定した値未満の行をフィルタリングします。 |
|
未満または等しい |
数値 |
該当なし |
[列] の値が指定した値未満または等しい行をフィルタリングします。 |
|
以上 |
数値 |
該当なし |
[列] の値が指定した値以上の行をフィルタリングします。 |
|
以上または等しい |
数値 |
該当なし |
[列] の値が指定した値以上または等しい行をフィルタリングします。 |
|
の間 |
数値 |
該当なし |
[列] の値が指定した 2 つの値の間または等しい行をフィルタリングします。 |
|
を含む |
テキスト |
カテゴリ |
[列] の値が指定した値を含む行をフィルタリングします。 |
|
で始まる |
テキスト |
カテゴリ |
[列] の値が指定した値で始まる行をフィルタリングします。 |
|
で終わる |
カテゴリ |
カテゴリ |
[列] の値が指定した値で終わる行をフィルタリングします。 |
フィルターオペレーションを設定した後、 SageMaker Canvas はデータセットのプレビューを更新して、フィルタリングされたデータを表示します。

関数と演算子
関数と演算子を使用して、データを探索したり配布したりできます。 SageMaker Canvas でサポートされている関数を使用するか、既存のデータで独自の式を作成し、式の結果で新しい列を作成できます。例えば、2 つの列の対応する値を追加し、その結果を新しい列に保存できます。
ステートメントをネストして、より複雑な関数を作成できます。以下は、使用できるネストされた関数の例です。
-
を計算するにはBMI、関数 を使用できます
weight / (height ^ 2)。 -
Case(age < 18, 'child', age < 65, 'adult', 'senior'): 年齢を分類するには、この関数を使用できます。
関数の指定は、モデルを構築する前のデータ準備段階で行えます。関数を使用するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、すべて表示を選択し、カスタム式を選択してカスタム式パネルを開きます。
-
[カスタム数式] パネルでは、[モデルレシピ] に追加する [数式] を選択できます。各数式は、指定した列のすべての値に適用されます。2 つ以上の列を引数として受け入れる式の場合は、一致するデータ型を持つ列を使用します。そうでない場合は、新しい列にエラーまたは
null値が表示されます。 -
式 を指定したら、新しい列名フィールドに列名を追加します。 SageMaker Canvas は、作成された新しい列にこの名前を使用します。
(オプション) [プレビュー] を選択して変換をプレビューします。
-
関数を [モデルレシピ] に追加するには、[追加] を選択します。
SageMaker Canvas は、新しい列名 で指定した名前を使用して、関数の結果を新しい列に保存します。[モデルレシピ] パネルでは、関数の表示や削除を行えます。
SageMaker Canvas は、関数に対して次の演算子をサポートしています。テキスト形式またはインライン形式のいずれかを使用して関数を指定できます。
| 演算子 | 説明 | サポートされているデータ型 | テキスト形式 | インライン形式 |
|---|---|---|---|---|
|
Add |
値の合計を返します |
数値 |
Add(sales1, sales2) |
sales1 + sales2 |
|
Subtract |
値の間の差を返します |
数値 |
Subtract(sales1, sales2) |
sales1 ‐ sales2 |
|
Multiply |
値の乗算値を返します |
数値 |
Multiply(sales1, sales2) |
sales1 * sales2 |
|
Divide |
値の除算値を返します |
数値 |
Divide(sales1, sales2) |
sales1 / sales2 |
|
Mod |
モジュロ演算の結果 (2 つの値を割った余り) を返します |
数値 |
Mod(sales1, sales2) |
sales1 % sales2 |
|
Abs |
値の絶対値を返します |
数値 |
Abs(sales1) |
該当なし |
|
Negate |
値の負の数値を返します |
数値 |
Negate(c1) |
‐c1 |
|
Exp |
e (オイラー数) を底とする数値のべき乗値を返します |
数値 |
Exp(sales1) |
該当なし |
|
Log |
10 を底とする対数を返します |
数値 |
Log(sales1) |
該当なし |
|
Ln |
e を底とする自然対数を返します |
数値 |
Ln(sales1) |
該当なし |
|
Pow |
累乗に引き上げられた数値を返します |
数値 |
Pow(sales1, 2) |
sales1 ^ 2 |
|
If |
指定した条件に基づいて true または false のラベルを返します |
ブール値、数値、テキスト |
If(sales1>7000, 'truelabel, 'falselabel') |
該当なし |
|
Or |
指定された値または条件のいずれかが true かどうかのブール値を返します |
ブール値 |
Or(fullprice, discount) |
fullprice || discount |
|
And |
指定された 2 つの値または条件が true かどうかのブール値を返します |
ブール値 |
And(sales1,sales2) |
sales1 && sales2 |
|
Not |
指定された値または条件の逆のブール値を返します |
ブール値 |
Not(sales1) |
!sales1 |
|
Case |
条件ステートメントに基づいてブール値を返します (cond1 が true の場合は c1 を返し、cond2 が true の場合は c2 を返し、それ以外の場合は c3 を返します)。 |
ブール値、数値、テキスト |
Case(cond1, c1, cond2, c2, c3) |
該当なし |
|
Equal |
2 つの値が等しいかどうかのブール値を返します |
ブール値、数値、テキスト |
該当なし |
c1 = c2 c1 == c2 |
|
Not equal |
2 つの値が等しくないかどうかのブール値を返します |
ブール値、数値、テキスト |
該当なし |
c1 != c2 |
|
Less than |
c1 が c2 より小さいかどうかのブール値を返します |
ブール値、数値、テキスト |
該当なし |
c1 < c2 |
|
Greater than |
c1 が c2 より大きいかどうかのブール値を返します |
ブール値、数値、テキスト |
該当なし |
c1 > c2 |
|
Less than or equal |
c1 が c2 以下かどうかのブール値を返します |
ブール値、数値、テキスト |
該当なし |
c1 <= c2 |
|
Greater than or equal |
c1 が c2 以上かどうかのブール値を返します |
ブール値、数値、テキスト |
該当なし |
c1 >= c2 |
SageMaker Canvas は集計演算子もサポートしており、すべての値の合計の計算や列内の最小値の検出などの操作を実行できます。関数では集約演算子と標準演算子を組み合わせて使用できます。例えば、平均値から値の差を計算するには、 関数を使用できますAbs(height – avg(height))。 SageMaker Canvas は次の集計演算子をサポートしています。
| 集約演算子 | 説明 | [形式] | 例 |
|---|---|---|---|
|
sum |
列のすべての値の合計を返します |
sum |
sum(c1) |
|
minimum |
列の最小値を返します。 |
min |
min(c2) |
|
maximum |
列の最大値を返します。 |
max |
max(c3) |
|
average |
列の平均値を返します。 |
avg |
avg(c4) |
|
std |
列のサンプル標準偏差を返します | std |
std(c1) |
|
stddev |
列の標準偏差値を返します | stddev |
stddev(c1) |
|
分散 |
列の値の不偏分散を返します |
分散 |
variance(c1) |
|
approx_count_distinct |
列内の固有のアイテムの概数を返します | approx_count_distinct |
approx_count_distinct(c1) |
|
count |
列内のアイテムの数を返します | count |
count(c1) |
|
first |
列の最初の値を返します |
first |
first(c1) |
|
last |
列の最後の値を返します |
last |
last(c1) |
|
stddev_pop |
列の母集団標準偏差を返します | stddev_pop |
stddev_pop(c1) |
|
variance_pop |
列の値の母分散を返します |
variance_pop |
variance_pop(c1) |
行を管理する
行の管理変換では、ソート、ランダムシャッフル、データセットからのデータ行の削除を行うことができます。
行のソート
データセット内の行を特定の列でソートするには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行の管理 を選択し、行のソート を選択します。
-
[ソート列] で、ソートの基準にする列を選択します。
-
[ソート順] で、[昇順] または [降順] を選択します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
行のシャッフル
データセット内の行をランダムにシャッフルするには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行の管理 を選択し、行のシャッフル を選択します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
重複した行のドロップ
データセット内の重複行を削除するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行の管理 を選択し、重複行の削除 を選択します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
欠損値による行の削除
欠落値は機械学習データセットで一般的に見られ、モデルの精度に影響を与えます。特定の列の null または空の値を含む行をドロップする場合、この変換を使用します。
指定した列にある欠損値を含む行を削除するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行の管理 を選択します。
[欠損値がある行をドロップ] を選択します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
SageMaker Canvas は、選択した列に欠損値を含む行を削除します。データセットから行を削除した後、 SageMaker Canvas はモデルレシピセクションに変換を追加します。[モデルレシピ] セクションから変換を削除すると、削除された行はデータセットに戻ります。

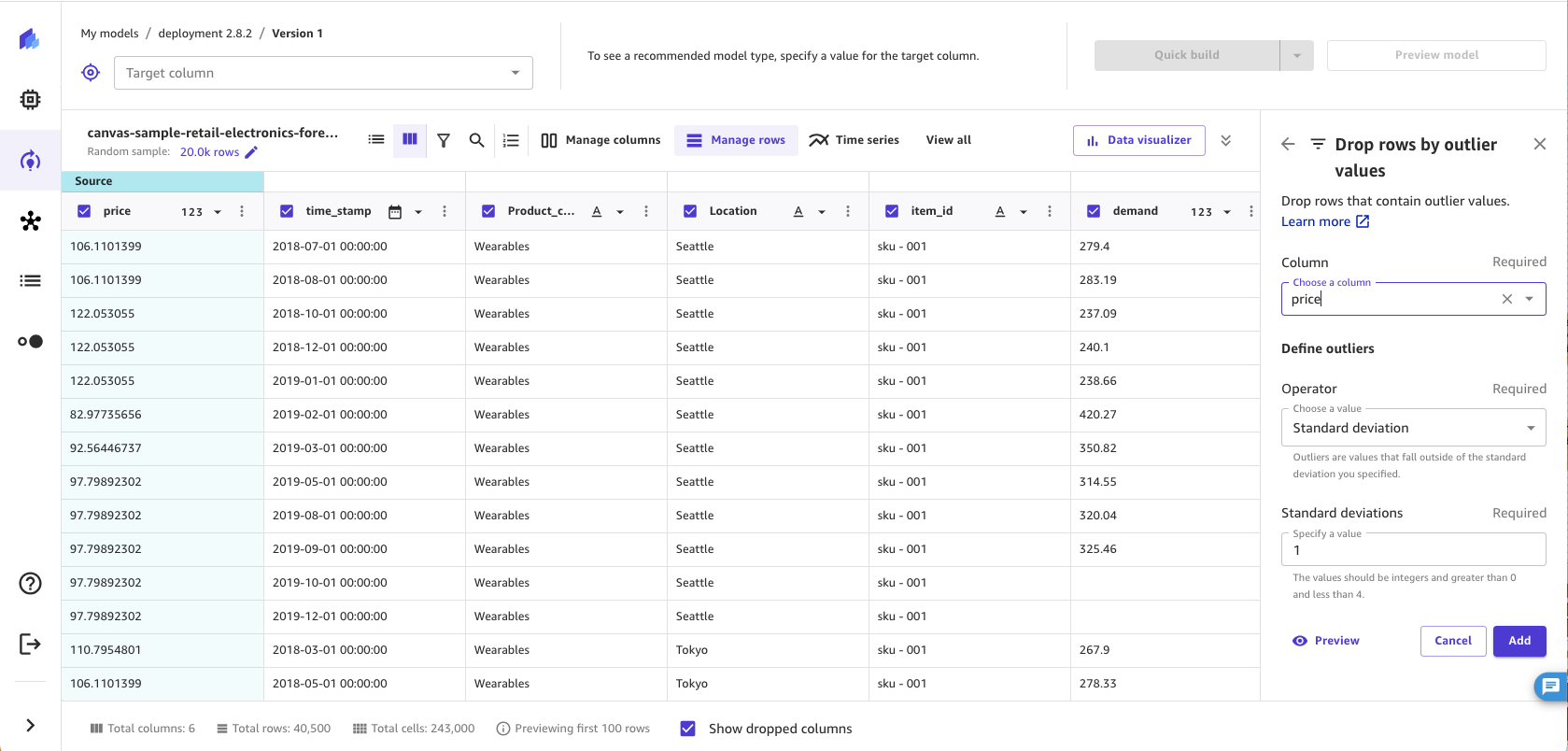
外れ値による行の削除
外れ値 (データの分布や範囲内にまれな値) は、モデルの精度を低下させ、モデルの構築時間が長くなる可能性があります。 SageMaker Canvas を使用すると、数値列に外れ値を含む行を検出および削除できます。外れ値は、標準偏差またはカスタム範囲のいずれかで定義できます。
データから外れ値を削除するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行の管理 を選択します。
[外れ値がある行をドロップ] を選択します。
-
外れ値の有無を確認する [列] を選択します。
-
[演算子] を [標準偏差]、[カスタム数値範囲]、または [カスタム分位数範囲] に設定します。
-
[標準偏差] を選択した場合は、1~3 の [標準偏差] 値を指定します。[カスタム数値範囲] または [カスタム分位数範囲] を選択した場合は、[最小値] と [最大値] (数値範囲の場合は数値、分位範囲の場合は 0~100% のパーセント) を指定します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
[標準偏差] オプションでは、平均値と標準偏差を使用して数値列の外れ値を検出して削除します。値を外れ値と見なすために必要な平均値からの変化として、標準偏差の値を指定します。例えば、[標準偏差] に 3 を指定すると、外れ値と見なすためには、平均値から 3 標準偏差より低い値である必要があります。
[カスタム数値範囲] オプションと [カスタム分位数範囲] オプションでは、最小値と最大値を使用して数値列の外れ値を検出し削除します。外れ値を定義するしきい値がわかっている場合は、この方法を使用します。[数値範囲] を選択した場合、[最小] と [最大] には、データで許容する最小値と最大値を指定します。[分位数範囲] を選択した場合、[最小] と [最大] には、許容するパーセント範囲 (0~100) の最小値と最大値を指定します。
データセットから行を削除した後、 SageMaker Canvas はモデルレシピセクションに変換を追加します。[モデルレシピ] セクションから変換を削除すると、削除された行はデータセットに戻ります。
カスタム値による行の削除
カスタム条件を満たす値を含む行を削除できます。例えば、モデルを作成する際、価格値が 100 を超える行をすべて除外する場合です。この変換を使用すると、設定したしきい値を超える行をすべて削除するルールを作成できます。
カスタム削除変換を使用するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、行の管理 を選択します。
[数式で行をドロップ] を選択します。
-
確認する [列] を選択します。
-
使用する [操作] タイプを選択して、選択した条件の値を指定します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
[操作] では、以下のオプションのいずれかを選択できます。使用できる操作は、選択する列のデータ型に応じて異なる場合があります。例えば、テキスト値を含む列には is greater than 操作は作成できません。
| 操作 | サポートされているデータ型 | サポート対象の特徴量タイプ | 機能 |
|---|---|---|---|
|
と等しい |
数値、テキスト |
バイナリ、カテゴリ |
[列] の値が指定した値と等しい行を削除します。 |
|
と等しくない |
数値、テキスト |
バイナリ、カテゴリ |
[列] の値が指定した値と等しくない行を削除します。 |
|
未満 |
数値 |
該当なし |
[列] の値が指定した値未満の行を削除します。 |
|
未満または等しい |
数値 |
該当なし |
[列] の値が指定した値未満または等しい行を削除します。 |
|
以上 |
数値 |
該当なし |
[列] の値が指定した値以上の行を削除します。 |
|
以上または等しい |
数値 |
該当なし |
[列] の値が指定した値以上または等しい行を削除します。 |
|
の間 |
数値 |
該当なし |
[列] の値が指定した 2 つの値の間または等しい行を削除します。 |
|
を含む |
テキスト |
カテゴリ |
[列] の値が指定した値を含む行を削除します。 |
|
で始まる |
テキスト |
カテゴリ |
[列] の値が指定した値で始まる行を削除します。 |
|
で終わる |
テキスト |
カテゴリ |
[列] の値が指定した値で終わる行を削除します。 |
データセットから行を削除した後、 SageMaker Canvas はモデルレシピセクションに変換を追加します。[モデルレシピ] セクションから変換を削除すると、削除された行はデータセットに戻ります。

列の名前変更
列の名変更変換では、データ内の列の名前を変更できます。列の名前を変更すると、 SageMaker Canvas はモデル入力の列名を変更します。
SageMaker Canvas アプリケーションのビルドタブで列名をダブルクリックし、新しい名前を入力することで、データセット内の列の名前を変更できます。Enter キーを押すと変更が送信され、入力以外の場所をクリックすると変更がキャンセルされます。リストビューの行の最後、またはグリッドビューのヘッダーセルの最後にある [その他のオプション] アイコン (
![]() ) をクリックし、[名前の変更] を選択して列の名前を変更することもできます。
) をクリックし、[名前の変更] を選択して列の名前を変更することもできます。
列名は 32 文字以内で、連続したアンダースコア (__) は使用できません。また、列の名前を別の列と同じ名前に変更することもできません。ドロップした列の名前を変更することもできません。
次のスクリーンショットは、列名をダブルクリックして列の名前を変更する方法を示しています。

列の名前を変更すると、 SageMaker Canvas はモデルレシピセクションに変換を追加します。[モデルレシピ] セクションから変換を削除すると、列は元の名前に戻ります。
列の管理
次の変換では、列のデータ型を変更し、特定の列の欠損値または外れ値を置き換えることができます。 SageMaker Canvas はモデルを構築するときに更新されたデータ型または値を使用しますが、元のデータセットは変更されません。列をドロップする 変換を使用してデータセットから列をドロップした場合、その列の値を置換することはできないことに注意してください。
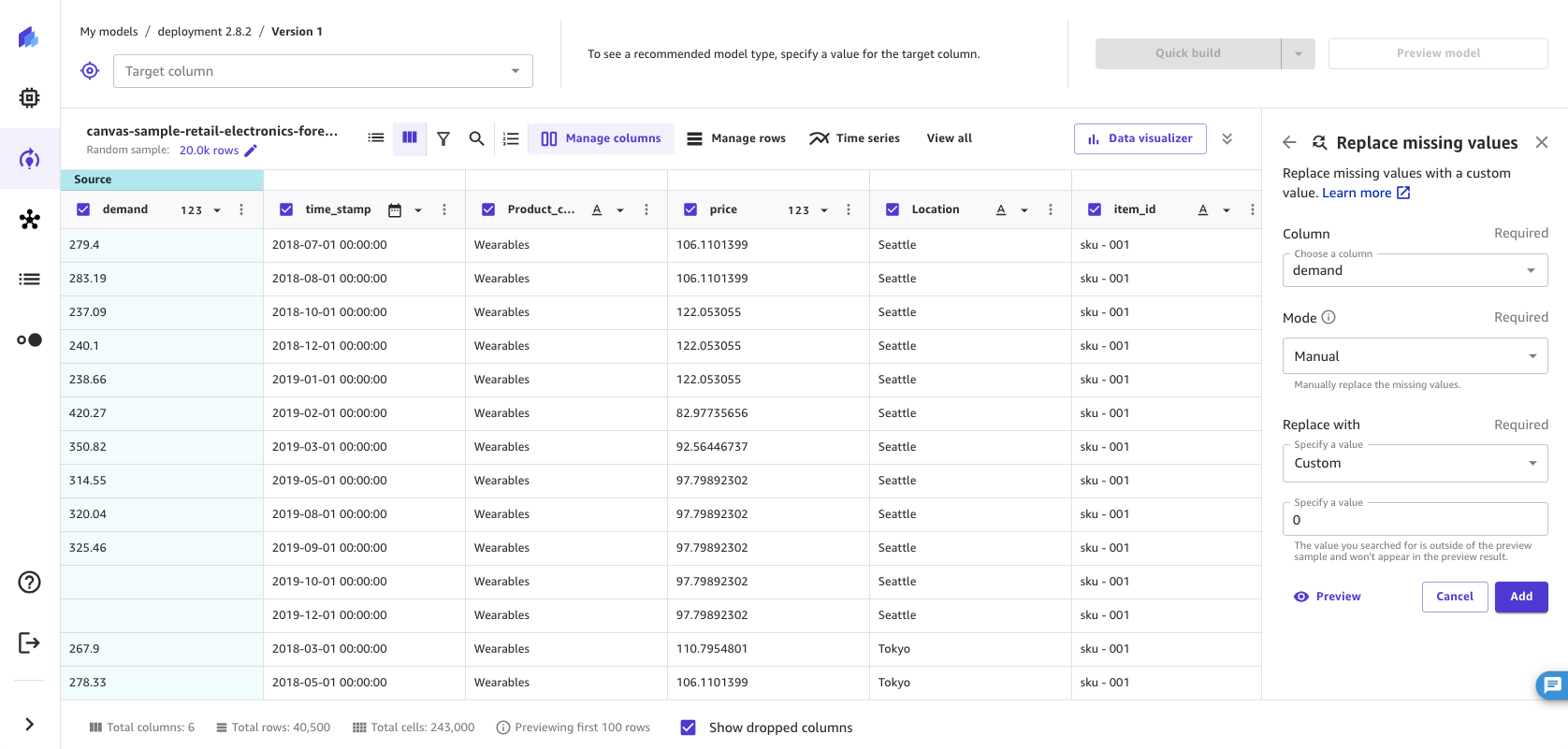
欠損値の置換
欠落値は機械学習データセットで一般的に見られ、モデルの精度に影響を与えます。欠損値のある行をドロップすることもできますが、欠損値を置換する方がモデルの精度は高くなります。この変換では、数値列の欠損値を列内のデータの平均または中央値で置換できます。また、欠損値を置換するカスタム値を指定することもできます。数値以外の列では、欠損値を列のモード (最も一般的な値) またはカスタム値で置換できます。
特定の列の null または空の値を含む行を置換する場合、この変換を使用します。指定した列にある欠損値を含む行を置換するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、列の管理 を選択します。
[欠損値の置換] を選択します。
-
欠損値を置換する [列] を選択します。
-
[モード] を [手動] に設定して、欠損値を指定した値で置換します。自動 (デフォルト) 設定では、 SageMaker Canvas は欠落している値をデータに最適な補完値に置き換えます。[手動] モードに設定しない限り、この置換はモデル構築のたびに自動的に実行されます。
-
[この値で置換] の値を設定します。
-
列が数値の場合は、[平均]、[中央値]、または [カスタム] を選択します。[平均] は欠損値を列の平均値で置換し、[中央値] は欠損値を列の中央値で置換します。[カスタム] を選択した場合は、欠損値の置換に使用するカスタム値を指定する必要があります。
-
列が数値以外の場合は、[モード] または [カスタム] を選択します。[モード] は、欠損値をモード、つまり列の最も一般的な値で置換します。[カスタム] では、欠損値の置換に使用するカスタム値を指定します。
-
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
データセット内の欠損値を置き換えた後、 SageMaker Canvas はモデルレシピセクションに変換を追加します。[モデルレシピ] セクションから変換を削除すると、欠損値はデータセットに戻ります。
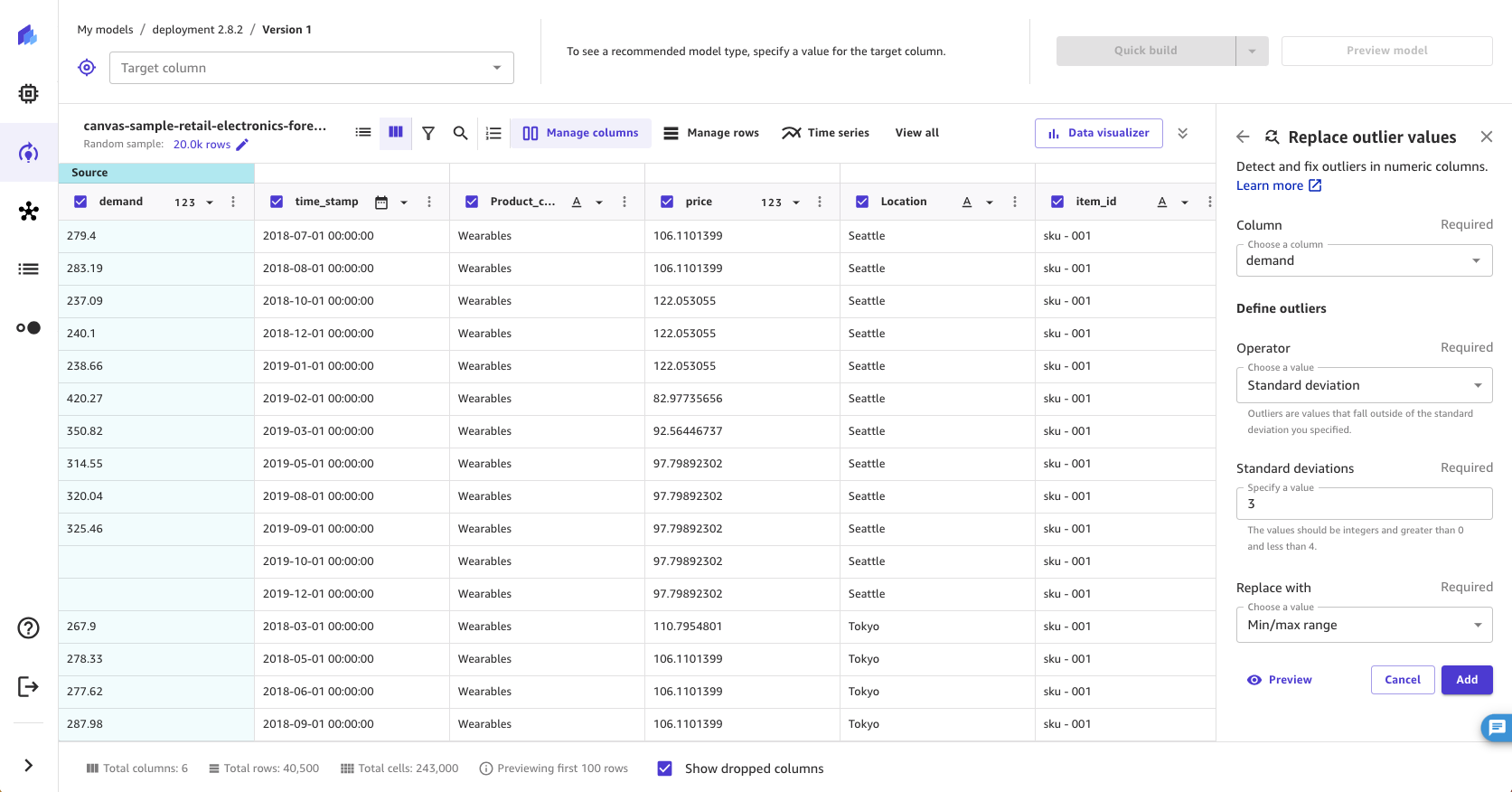
外れ値の置換
外れ値、またはデータの分布と範囲のまれな値は、モデルの精度に悪影響を及ぼし、構築時間が長くなる可能性があります。 SageMaker Canvas を使用すると、数値列の外れ値を検出し、外れ値をデータ内の許容される範囲内の値に置き換えることができます。外れ値は標準偏差またはカスタム範囲のいずれかで定義でき、外れ値は許容範囲内の最小値と最大値で置換することができます。
データで外れ値を置換するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、列の管理 を選択します。
[外れ値の置換] を選択します。
-
外れ値を置換する [列] を選択します。
-
[外れ値の定義] で、[標準偏差]、[カスタム数値範囲]、または [カスタム分位数範囲] を選択します。
-
[標準偏差] を選択した場合は、1~3 の [標準偏差] 値を指定します。[カスタム数値範囲] または [カスタム分位数範囲] を選択した場合は、[最小値] と [最大値] (数値範囲の場合は数値、分位範囲の場合は 0~100% のパーセント) を指定します。
-
[この値で置換] で、[最小/最大範囲] を選択します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
[標準偏差] オプションでは、平均値と標準偏差を使用して数値列の外れ値を検出します。値を外れ値と見なすために必要な平均値からの変化として、標準偏差の値を指定します。例えば、標準偏差 に 3 を指定した場合、外れ値と見なされるには、平均値から 3 つ以上の標準偏差を下回っている必要があります。 SageMaker Canvas は外れ値を許容範囲内の最小値または最大値に置き換えます。例えば、標準偏差に 200~300 の値のみを含めるように設定した場合、 SageMaker Canvas は 198 の値を 200 (最小値) に変更します。
[カスタム数値範囲] オプションと [カスタム分位数範囲] オプションでは、最小値と最大値を使用して数値列の外れ値を検出します。外れ値を定義するしきい値がわかっている場合は、この方法を使用します。数値範囲を選択した場合、最小値と最大値は、許可する最小値と最大値である必要があります。 SageMaker Canvas は、最小値と最大値の範囲外の値を最小値と最大値に置き換えます。例えば、範囲が 1~100 の値のみを許可する場合、Canvas SageMaker は 102 の値を 100 (最大値) に変更します。[分位数範囲] を選択した場合、[最小] と [最大] には、許容するパーセント範囲 (0~100) の最小値と最大値を指定します。
データセット内の値を置き換えた後、 SageMaker Canvas はモデルレシピセクションに変換を追加します。[モデルレシピ] セクションから変換を削除すると、外れ値はデータセットに戻ります。
データ型の変更
SageMaker Canvas では、列のデータ型を数値、テキスト、および日時の間で変更できるほか、そのデータ型に関連付けられた特徴量タイプも表示できます。データ型はデータの形式と保存方法を指し、特徴型は機械学習アルゴリズムで使用されるデータの特性 (バイナリやカテゴリなど) を指します。これにより、特徴量に基づいて列内のデータ型を手動で柔軟に変更できます。適切なデータ型を選択できるため、モデルを構築する前にデータの整合性と正確性が確保されます。これらのデータ型はモデルを構築する際に使用されます。
注記
現在、特徴量タイプの変更 (バイナリからカテゴリへの変更など) はサポートされていません。
次の表に、サポートされているすべてのデータ型を示します。
| データ型 | 説明 | 例 |
|---|---|---|
数値 |
数値データは数値を表します |
1、2、3 1.1、1.2。1.3 |
テキスト |
テキストデータは、名前や説明などの一連の文字を表します |
A、B、C、D りんご、バナナ、オレンジ 1A!、2A!、3A! |
Datetime |
Datetime データは、日付と時刻をタイムスタンプ形式で表します。 |
2019-07-01 01:00:00, 2019-07-01 02:00:00, 2019-07-01 03:00:00 |
次の表に、サポートされているすべての特徴量を示します。
| 特徴量タイプ | 説明 | 例 |
|---|---|---|
バイナリ |
バイナリ特徴量は可能な 2 つの値を表します |
0、1、0、1、0 (2 つの異なる値) 真、偽、真 (2 つの異なる値) |
カテゴリ |
カテゴリ特徴量は異なるカテゴリまたはグループを表します |
りんご、バナナ、オレンジ、リンゴ (3 つの異なる値) A、B、C、D、E、A、D、C (5 つの異なる値) |
データセットの列のデータ型を変更するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、列ビューまたはグリッドビューに移動し、特定の列のデータ型ドロップダウンを選択します。
-
[データ型] ドロップダウンで、変換先のデータ型を選択します。次のスクリーンショットは、ドロップダウンメニューを示しています。

-
[列] で、データ型を変更する列を選択するか確認します。
-
[新しいデータ型] で、変換する新しいデータ型を選択または確認します。
-
[新しいデータ型] が
DatetimeまたはNumericの場合は、[無効な値の処理] で以下のいずれかのオプションを選択します。[空の値で置換] — 無効な値を空の値で置換します
[行を削除] — 値が無効な行をデータセットから削除します
[カスタム値で置換] — 無効な値を指定した [カスタム値] で置換します。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
これで、列のデータ型が更新されます。
時系列データの準備
以下の機能を使用して、時系列予測モデルを構築するための時系列データを準備します。
時系列データを再サンプリングする
時系列データを再サンプリングすると、時系列データセット内の観測値の一定間隔を設定できます。これは、不規則な間隔の観測値を含む時系列データを扱う場合に特に便利です。例えば、再サンプリングを使用して、1 時間、2 時間、3 時間ごとに記録された観測値を含むデータセットを、観測間の通常の 1 時間間隔に変換できます。予測アルゴリズムでは、観測値を一定の間隔で取得する必要があります。
時系列データを再サンプリングするには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブで、時系列 を選択します。
-
[Resample] (再サンプリング) を選択します。
-
[タイムスタンプ列] では、変換を適用する列を選択します。選択できるのは Datetime タイプの列だけです。
-
[頻度設定] セクションで、[頻度] と [レート] を選択します。[頻度] は頻度の単位、[レート] は列に適用される頻度単位の間隔です。例えば、[頻度値] に
Calendar Dayを、[レート] に1を設定すると、2023-03-26 00:00:00、2023-03-27 00:00:00、2023-03-28 00:00:00などのように間隔が 1 カレンダー日になります。[頻度値] の完全なリストについては、この手順の後の表を参照してください。 -
[追加] を選択して、[モデルレシピ] に変換を追加します。
次の表に、時系列データを再サンプリングする際に選択できるすべての [頻度] タイプを示します。
| 頻度 | 説明 | 値の例 (レートが 1 の場合) |
|---|---|---|
|
営業日 |
datetime 列の観測値を週 5 営業日 (月曜日、火曜日、水曜日、木曜日、金曜日) に再サンプリングします。 |
2023-03-24 00:00:00 2023-03-27 00:00:00 2023-03-28 00:00:00 2023-03-29 00:00:00 2023-03-30 00:00:00 2023-03-31 00:00:00 2023-04-03 00:00:00 |
|
曜日 |
datetime 列の観測値を週の 7 曜日 (月曜日、火曜日、水曜日、木曜日、金曜日、土曜日、日曜日) に再サンプリングします。 |
2023-03-26 00:00:00 2023-03-27 00:00:00 2023-03-28 00:00:00 2023-03-29 00:00:00 2023-03-30 00:00:00 2023-03-31 00:00:00 2023-04-01 00:00:00 |
|
週 |
datetime 列の観測値を各週の最初の日に再サンプリングします。 |
2023-03-13 00:00:00 2023-03-20 00:00:00 2023-03-27 00:00:00 2023-04-03 00:00:00 |
|
月 |
datetime 列の観測値を各月の最初の日に再サンプリングします。 |
2023-03-01 00:00:00 2023-04-01 00:00:00 2023-05-01 00:00:00 2023-06-01 00:00:00 |
|
年次四半期 |
datetime 列の観測値を各四半期の最後の日に再サンプリングします。 |
2023-03-31 00:00:00 2023-06-30 00:00:00 2023-09-30 00:00:00 2023-12-31 00:00:00 |
|
年 |
datetime 列の観測値を各年の最後の日に再サンプリングします。 |
2022-12-31 0:00:00 2023-12-31 00:00:00 2024-12-31 00:00:00 |
|
時 |
datetime 列の観測値を各日の各時に再サンプリングします。 |
2023-03-24 00:00:00 2023-03-24 01:00:00 2023-03-24 02:00:00 2023-03-24 03:00:00 |
|
分 |
datetime 列の観測値を各時の各分に再サンプリングします。 |
2023-03-24 00:00:00 2023-03-24 00:01:00 2023-03-24 00:02:00 2023-03-24 00:03:00 |
|
秒 |
datetime 列の観測値を各分の各秒に再サンプリングします。 |
2023-03-24 00:00:00 2023-03-24 00:00:01 2023-03-24 00:00:02 2023-03-24 00:00:03 |
再サンプリング変換を適用する場合、[詳細] オプションを使用して、データセット内の残りの列 (タイムスタンプ列以外) の結果値をどのように変更するかを指定できます。これは、再サンプリング方法を指定することで実現できます。リサンプリング方法では、数値列と非数値列の両方をダウンサンプリングまたはアップサンプリングできます。
ダウンサンプリングは、データセットの観測値の間隔を大きくします。例えば、1 時間ごとまたは 2 時間ごとに取得される観測値をダウンサンプリングすると、データセット内の各観測値は 2 時間ごとに取得されます。時間単位の観測値の他の列の値は、組み合わせ方法を使用して単一の値に集約されます。次の表は、平均値を組み合わせ方法として使用し、時系列データをダウンサンプリングする例を示しています。データは 2 時間ごとから 1 時間ごとにダウンサンプリングされます。
次の表は、ダウンサンプリングを行う前の 1 日の 1 時間ごとの温度測定値を示しています。
| タイムスタンプ | 温度 (摂氏) |
|---|---|
12:00 pm |
30 |
1:00 am |
32 |
2:00 am |
35 |
3:00 am |
32 |
4:00 am |
30 |
次の表は、2 時間ごとでダウンサンプリングした後の温度測定値を示しています。
| タイムスタンプ | 温度 (摂氏) |
|---|---|
12:00 pm |
30 |
2:00 am |
33.5 |
2:00 am |
35 |
4:00 am |
32.5 |
時系列データをダウンサンプリングするには、次の手順に従います。
-
[再サンプリング] 変換の [詳細] セクションを展開します。
-
非数値列の組み合わせ方法を指定するには、[非数値の組み合わせ] を選択します。組み合わせ方法のリストについては、以下の表を参照してください。
-
数値列の組み合わせ方法を指定するには、[数値の組み合わせ] を選択します。組み合わせ方法のリストについては、以下の表を参照してください。
組み合わせ方法を指定しない場合、デフォルト値は [非数値の組み合わせ] では Most Common に、[数値の組み合わせ] では Mean になります。次の表は、数値と非数値の組み合わせの方法を示しています。
| ダウンサンプリング法 | 組み合わせ法 | 説明 |
|---|---|---|
非数値組み合わせ |
最も一般的 |
数値以外の列の値を最も頻繁に出現する値で集計します |
非数値組み合わせ |
最後 |
数値以外の列の値を列の最後の値で集計します |
非数値組み合わせ |
最初 |
数値以外の列の値を列の最初の値で集計します |
非数値組み合わせ |
平均 |
数値列のすべての値の平均値をとることで数値列の値を集計します |
非数値組み合わせ |
中央値 |
数値列のすべての値の中央値をとることで数値列の値を集計します |
非数値組み合わせ |
最小 |
数値列のすべての値の最小値をとることで数値列の値を集計します |
非数値組み合わせ |
最大 |
数値列のすべての値の最大値をとることで数値列の値を集計します |
非数値組み合わせ |
合計 |
数値列のすべての値を合計することで数値列の値を集計します |
非数値組み合わせ |
分位数 |
数値列のすべての値の分位数値をとることで数値列の値を集計します |
アップサンプリングは、データセットの観測値の間隔を小さくします。例えば、2 時間ごとに取得される観測値を 1 時間ごとに取得される観測値にアップサンプリングする場合、補間法を使用して 2 時間ごとに取得された観測値から 1 時間ごとに取得される観測値を推測できます。
時系列データをアップサンプリングするには、次の手順に従います。
-
[再サンプリング] 変換の [詳細] セクションを展開します。
-
[非数値の推定] を選択して、非数値列の推定方法を指定します。推定方法の完全なリストについては、この手順の後の表を参照してください。
-
[数値の推定] を選択して、数値列の推定方法を指定します。推定方法の完全なリストについては、次の表を参照してください。
-
(オプション) ID 列を選択して、時系列IDsの観測値の を持つ列を指定します。データセットに 2 つの時系列がある場合は、このオプションを指定します。時系列を表す列が 1 つだけの場合は、このフィールドに値を指定しないでください。例えば、
id列とpurchase列を含むデータセットを使用する場合があります。id列には[1, 2, 2, 1]の値があり、purchase列には[$2, $3, $4, $1]の値があります。したがって、このデータセットには 2 つの時系列があります。1 つの時系列は1: [$2, $1]で、もう 1 つの時系列は2: [$3, $4]です。
推定方法を指定しない場合、デフォルト値は [非数値の推定] では Forward Fill に、[数値の推定] では Linear になります。次の表に推定方法の一覧を示します。
| アップサンプリング法 | 推定方法 | 説明 |
|---|---|---|
非数値の推定 |
フォワードフィル |
列のすべての値の後に連続する値をとって、非数値列の値を補間します |
非数値の推定 |
バックワードフィル |
列のすべての値の前に連続する値をとって、非数値列の値を補間します |
非数値の推定 |
欠損値の維持 |
空の値を表示して、非数値列の値を補間します |
数値の推定 |
線形、時間、インデックス、ゼロ、S-線形、近似、2 次、キュービック、重心、多項式、クロー、区分的多項式、スプライン、Pチップ、アキマ、キュービックスプライン、微分推定 |
指定した補間方法で、数値列の値を補間します 補間方法の詳細については、pandas ドキュメントの「pandasDataFrame..interpolate |
次のスクリーンショットは、ダウンサンプリングとアップサンプリングのフィールドが入力された[詳細] 設定を示しています。

datetime 抽出の使用
datetime 抽出変換を使用すると、datetime 列から別の列に値を抽出できます。例えば、購入日を含む列がある場合、月の値を別の列に抽出し、その新しい列を使用してモデルを作成できます。また、1 回の変換で複数の値を抽出して別々の列にすることもできます。
datetime 列には、サポートされているタイムスタンプ形式を使用する必要があります。 SageMaker Canvas がサポートする形式のリストについては、「」を参照してくださいAmazon SageMaker Canvas の時系列予測。データセットでサポートされている形式のいずれかが使用されていない場合は、サポートされているタイムスタンプ形式を使用するようにデータセットを更新し、モデルを構築する前に Amazon SageMaker Canvas に再インポートします。
datetime 抽出を実行するには、次の手順に従います。
-
SageMaker Canvas アプリケーションのビルドタブの変換バーで、すべての を表示する を選択します。
[Extract features] (特徴を抽出) を選択します。
-
値を抽出する [タイムスタンプ] 列を選択します。
-
[値] で、列から抽出する値を 1 つ以上選択します。タイムスタンプ列から抽出できる値は、[年]、[月]、[日]、[時間]、[週]、[曜日]、[四半期] です。
(オプション) [プレビュー] を選択して変換結果をプレビューします。
-
[追加] を選択して、[モデルレシピ] に変換を追加します。
SageMaker Canvas は、抽出する各値のデータセットに新しい列を作成します。年の値を除き、 SageMaker Canvas は抽出された値に 0 ベースのエンコーディングを使用します。例えば、[月] の値を抽出すると、1 月は 0 として抽出され、2 月は 1 として抽出されます。

変換は [モデルレシピ] セクションに一覧表示されます。[モデルレシピ] セクションから変換を削除すると、新しい列はデータセットにから削除されます。
