翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
テキストデータの予測を行う
テキストデータセットの単一予測とバッチ予測の両方を行う方法を以下に示します。各 Ready-to-useモデルは、データセットの単一予測とバッチ予測の両方をサポートします。単一予測では、単一の予測を行います。例えば、テキストを抽出する画像が 1 つだけの場合や、主要言語を検出するテキストの段落が 1 つだけの場合です。バッチ予測では、データセット全体の予測を行います。例えば、顧客の感情を分析したい顧客レビューのCSVファイルがある場合や、オブジェクトを検出したいイメージファイルがある場合などです。
これらの手順は、感情分析、エンティティ抽出、言語検出、個人情報検出のモデルタイプに使用できます Ready-to-use。
注記
現在、センチメント分析ができるのは英語のテキストだけです。
単一予測
テキストデータを受け入れるモデルに対して Ready-to-use単一の予測を行うには、次の操作を行います。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデルを選択します。
-
Ready-to-use モデルページで、ユースケースのモデルを選択します Ready-to-use。テキストデータの場合、センチメント分析、エンティティ抽出、言語検出、または個人情報検出のいずれかである必要があります。
-
選択した Ready-to-useモデルの予測を実行するページで、単一予測を選択します。
-
[テキストフィールド] に、予測を取得するテキストを入力します。
-
[予測結果を生成] を選択して予測を生成します。
右側のペインの [予測結果] には、各結果またはラベルの [信頼度] スコアに加えて、テキストの分析結果が表示されます。例えば、言語検出を選択して、フランス語のテキストの一部を入力した場合、信頼度スコアはフランス語が 95%、英語など他の言語が 5% になることがあります。
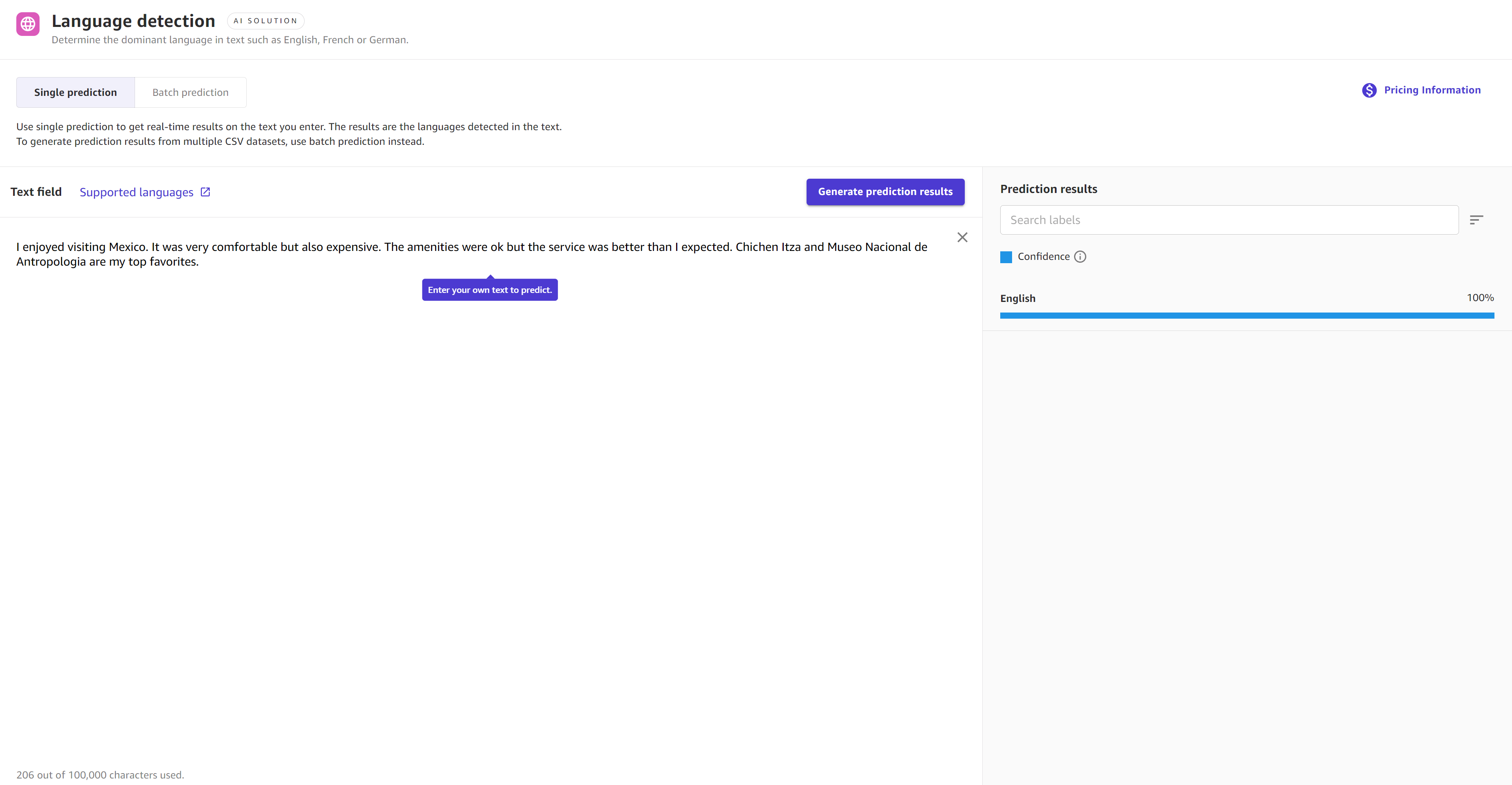
次のスクリーンショットは、その文章が英語であることのモデルの信頼度が 100% の場合の、言語検出を使用した単一予測の結果を示しています。
バッチ予測
テキストデータを受け入れるモデルのバッチ予測 Ready-to-useを行うには、次の手順を実行します。
-
Canvas アプリケーションの左側のナビゲーションペインで、Ready-to-use モデルを選択します。
-
Ready-to-use モデルページで、ユースケースのモデルを選択します Ready-to-use。テキストデータの場合、センチメント分析、エンティティ抽出、言語検出、または個人情報検出のいずれかである必要があります。
-
選択した Ready-to-useモデルの予測を実行するページで、バッチ予測を選択します。
-
データセットを既にインポートしている場合は、[データセットを選択] を選択します。それ以外の場合は、[新しいデータセットをインポート] を選択すると、データのインポートワークフローが表示されます。
-
使用可能なデータセットのリストからデータセットを選択し、[予測を生成] を選択して予測を生成します。
予測ジョブの実行が完了すると、[予測を実行] ページの [予測] の下に出力データセットが表示されます。このデータセットには結果が格納されており、[その他のオプション] アイコン (
![]() ) を選択すると、出力データをプレビューできます。次に、[ダウンロード] を選択して結果をダウンロードします。
) を選択すると、出力データをプレビューできます。次に、[ダウンロード] を選択して結果をダウンロードします。
