翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
コード例: SDK for Python
このセクションでは、SageMaker Clarify オンライン説明可能性を使用するエンドポイントを作成および呼び出すためのサンプルコードを提供します。これらのコード例では AWS SDK for Python
表形式のデータ
次の例では、表形式データと という SageMaker AI モデルを使用していますmodel_name。この例では、モデルコンテナは CSV 形式のデータを受け入れ、各レコードには 4 つの数値特徴量があります。この最小限の設定では、デモンストレーションのみを目的として、SHAP ベースラインデータは 0 に設定されています。ShapBaseline により適切な値を選択する方法については、「説明可能性のための SHAP ベースライン」を参照してください。
エンドポイントを次のように設定します。
endpoint_config_name = 'tabular_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '0,0,0,0', }, }, }, }, )
エンドポイント設定を使用して、次のようにエンドポイントを作成します。
endpoint_name = 'tabular_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
DescribeEndpoint API を使用して、次のようにエンドポイント作成の進行状況を確認します。
response = sagemaker_client.describe_endpoint( EndpointName=endpoint_name, ) response['EndpointStatus']
エンドポイントのステータスが「InService」になったら、次のようにテストレコードを使用してエンドポイントを呼び出します。
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', )
注記
前述のコード例では、マルチモデルエンドポイントの場合、リクエストに追加の TargetModel パラメータを渡して、エンドポイントでターゲットとするモデルを指定します。
レスポンスのステータスコードが 200 (エラーなし) であると仮定し、次のようにレスポンスの本文をロードします。
import codecs import json json.load(codecs.getreader('utf-8')(response['Body']))
エンドポイントのデフォルトのアクションは、レコードの説明です。以下は、返される JSON オブジェクトの出力例です。
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.0006380207487381" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [-0.00433456] } ] }, { "attributions": [ { "attribution": [-0.005369821] } ] }, { "attributions": [ { "attribution": [0.007917749] } ] }, { "attributions": [ { "attribution": [-0.00261214] } ] } ] ] } }
EnableExplanations パラメータを使用して、以下のようにオンデマンドの説明を有効にします。
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='1,2,3,4', EnableExplanations='[0]>`0.8`', )
注記
前述のコード例では、マルチモデルエンドポイントの場合、リクエストに追加の TargetModel パラメータを渡して、エンドポイントでターゲットとするモデルを指定します。
この例では、予測値がしきい値 0.8 を下回っているため、レコードは説明されません。
{ "version": "1.0", "predictions": { "content_type": "text/csv; charset=utf-8", "data": "0.6380207487381995" }, "explanations": {} }
視覚化ツールを使用すると、返される説明を解釈するのに役立ちます。以下の図は、各特徴が予測にどのように寄与するかを理解するために SHAP プロットを使用する方法を示しています。この図上のベース値は、予想値とも呼ばれ、トレーニングデータセットの平均予測値です。予想値を高くする特徴は赤、予想値を下げる特徴は青です。追加情報については、「SHAP アディティブフォースレイアウト
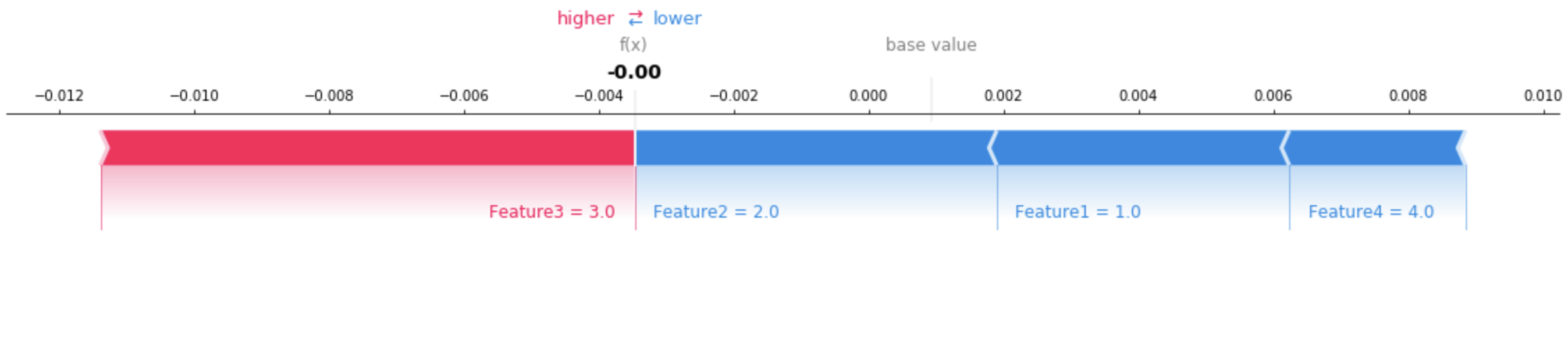
「表形式データの完全なサンプルノートブック
テキストデータ
このセクションでは、テキストデータのオンライン説明可能性エンドポイントを作成して呼び出すコード例を紹介します。コード例では SDK for Python を使用しています。
次の例では、テキストデータと という SageMaker AI モデルを使用していますmodel_name。この例では、モデルコンテナは CSV 形式のデータを受け入れ、各レコードは 1 つの文字列です。
endpoint_config_name = 'text_explainer_endpoint_config' response = sagemaker_client.create_endpoint_config( EndpointConfigName=endpoint_config_name, ProductionVariants=[{ 'VariantName': 'AllTraffic', 'ModelName': model_name, 'InitialInstanceCount': 1, 'InstanceType': 'ml.m5.xlarge', }], ExplainerConfig={ 'ClarifyExplainerConfig': { 'InferenceConfig': { 'FeatureTypes': ['text'], 'MaxRecordCount': 100, }, 'ShapConfig': { 'ShapBaselineConfig': { 'ShapBaseline': '"<MASK>"', }, 'TextConfig': { 'Granularity': 'token', 'Language': 'en', }, 'NumberOfSamples': 100, }, }, }, )
-
ShapBaseline: 自然言語処理 (NLP) 処理用に予約された特別なトークンです。 -
FeatureTypes: 特徴量をテキストとして識別します。このパラメータが指定されていない場合、説明機能は特徴量タイプを推測しようとします。 -
TextConfig: テキストの特徴量を分析するための粒度と言語の単位を指定します。この例では、言語は英語で、粒度tokenは英語テキストの単語を指します。 -
NumberOfSamples: 合成データセットのサイズの上限を設定する制限。 -
MaxRecordCount: モデルコンテナが処理できるリクエスト内の最大レコード数。このパラメータはパフォーマンスを安定させるために設定されています。
エンドポイント設定を使用して、次のようにエンドポイントを作成します。
endpoint_name = 'text_explainer_endpoint' response = sagemaker_client.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name, )
エンドポイントのステータスが InService になったら、エンドポイントを呼び出します。次のコードサンプルでは、テストレコードを次のように使用しています。
response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType='text/csv', Accept='text/csv', Body='"This is a good product"', )
リクエストが正常に完了すると、レスポンスの本文は次のような有効な JSON オブジェクトを返します。
{ "version": "1.0", "predictions": { "content_type": "text/csv", "data": "0.9766594\n" }, "explanations": { "kernel_shap": [ [ { "attributions": [ { "attribution": [ -0.007270948666666712 ], "description": { "partial_text": "This", "start_idx": 0 } }, { "attribution": [ -0.018199033666666628 ], "description": { "partial_text": "is", "start_idx": 5 } }, { "attribution": [ 0.01970993241666666 ], "description": { "partial_text": "a", "start_idx": 8 } }, { "attribution": [ 0.1253469515833334 ], "description": { "partial_text": "good", "start_idx": 10 } }, { "attribution": [ 0.03291143366666657 ], "description": { "partial_text": "product", "start_idx": 15 } } ], "feature_type": "text" } ] ] } }
視覚化ツールを使用すると、返されるテキスト属性を解釈するのに役立ちます。次の画像は、各単語が予測にどれほど寄与しているかを理解するために、captum 可視化ユーティリティを使用する方法を示しています。彩度が高いほど、その単語の重要度も高くなります。この例では、彩度の高い明るい赤色は、マイナスの影響が強いことを示しています。彩度の高い緑色はプラスの影響が強いことを示しています。白色はその単語の寄与が中立であることを示します。属性の解析とレンダリングに関する追加情報については、「captum

「テキストデータの完全なノートブックのサンプル
