翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データとデータ品質に関するインサイトを取得する
データ品質とインサイトレポートを使用して、Data Wrangler にインポートしたデータを分析します。データセットをインポートした後にレポートを作成することをお勧めします。このレポートはデータのクリーニングと処理に役立ちます。欠損値の数や外れ値の数などの情報が提供されます。ターゲット漏洩や不均衡など、データに問題がある場合は、インサイトレポートでそれらの問題に注意を向けることができます。
以下の手順を使用して、データ品質とインサイトレポートを作成します。Data Wrangler フローにデータセットをインポート済みであることを前提としています。
データ品質とインサイトレポートを作成するには
-
Data Wrangler フロー内のノードの横にある [+] を選択します。
-
[データインサイトを取得する] を選択します。
-
[分析名] に、インサイトレポートの名前を指定します。
-
(オプション) [ターゲット列] に、ターゲット列を指定します。
-
[問題のタイプ] に、[回帰] または [分類] を指定します。
-
[データサイズ] に、次のいずれかを指定します。
-
[50 K] — インポートしたデータセットの最初の 50,000 行を使用してレポートを作成します。
-
[データセット全体] — インポートしたデータセット全体を使用してレポートを作成します。
注記
データセット全体で Data Quality and Insights レポートを作成すると、Amazon SageMaker 処理ジョブが使用されます。 SageMaker 処理ジョブは、すべてのデータのインサイトを取得するために必要な追加のコンピューティングリソースをプロビジョニングします。ジョブ SageMaker の処理の詳細については、「」を参照してください SageMaker 処理によるデータ変換ワークロード。
-
-
[Create] (作成) を選択します。
以下のトピックはレポートの各セクションを示しています。
レポートはダウンロードすることも、オンラインで表示することもできます。レポートをダウンロードするには、画面右上にあるダウンロードボタンを選択します。次の図は、ボタンを示しています。

[概要]
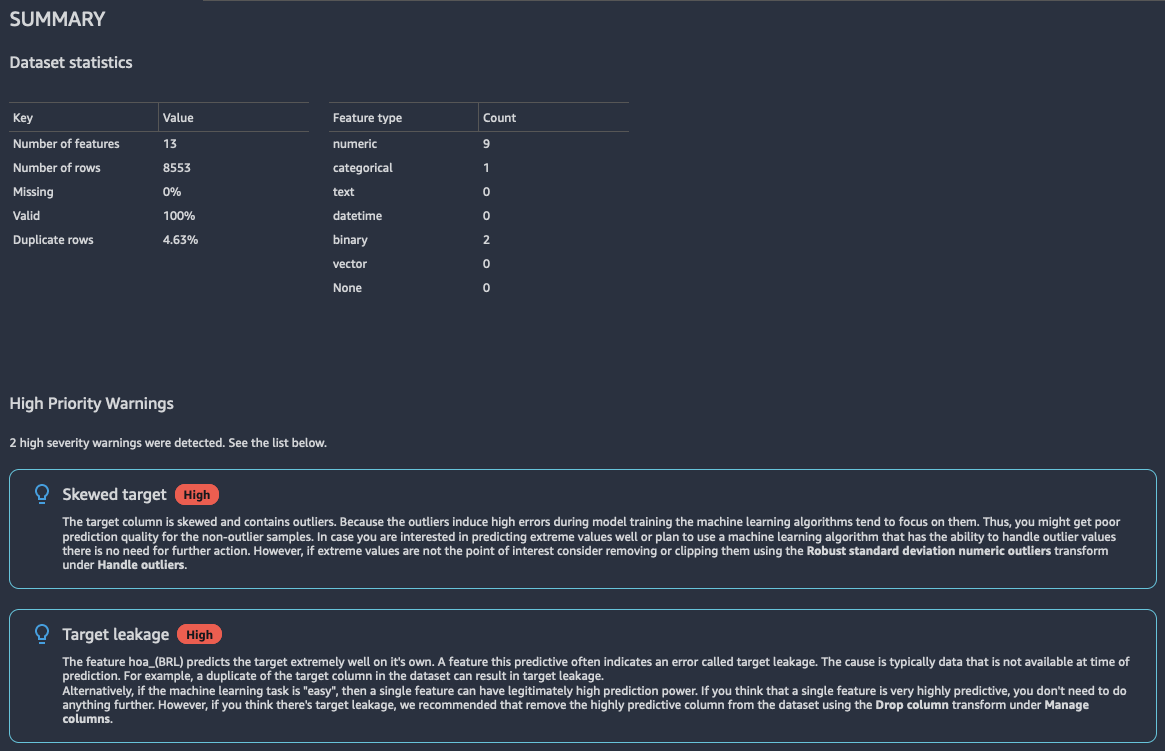
インサイトレポートには、欠損値、無効な値、特徴型、外れ値の数などの一般的な情報を含むデータの簡単な概要が表示されます。また、データに問題がある可能性を示す、重要度の高い警告を含めることもできます。警告を調査することをお勧めします。
レポートの要約の例を次に示します。
ターゲット列
データ品質とインサイトレポートを作成すると、Data Wrangler ではターゲット列を選択するオプションが表示されます。ターゲット列とは、予測しようとしている列のことです。ターゲット列を選択すると、Data Wrangler はターゲット列分析を自動的に作成します。また、予測能力の順に特徴をランク付けします。ターゲット列を選択するときは、解決しようとしているのが回帰問題なのか分類問題なのかを指定する必要があります。
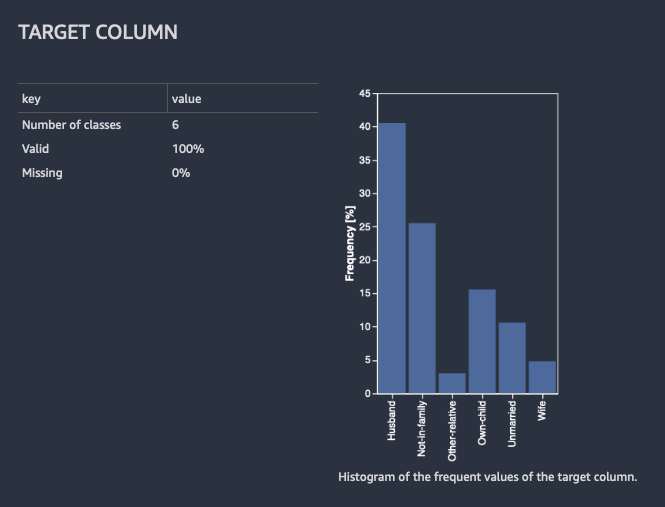
分類の場合、Data Wrangler は最も一般的なクラスの表とヒストグラムを表示します。クラスはカテゴリです。また、ターゲット値が欠落しているか無効である観測値または行も表示されます。
次の図は、分類問題のターゲット列分析の例を示しています。
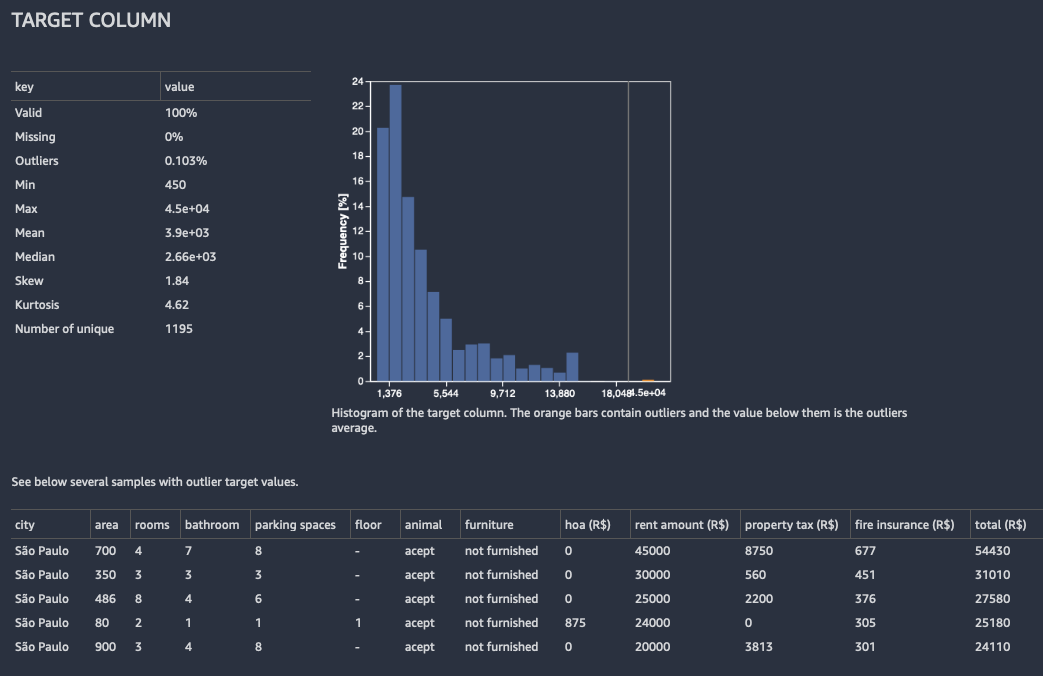
回帰の場合、Data Wrangler はターゲット列のすべての値のヒストグラムを表示します。また、ターゲット値が欠落している、無効である、または外れ値になっている観測値または行も表示されます。
次の図は、回帰問題のターゲット列分析の例を示しています。
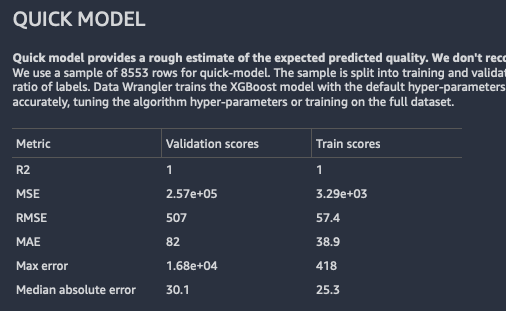
クイックモデル
クイックモデルでは、データを使ってトレーニングしたモデルの想定される予測品質を推定できます。
Data Wrangler はデータをトレーニングフォールドと検証フォールドに分割します。サンプルの 80% をトレーニングに、値の 20% を検証に使用します。分類の場合、サンプルは層化分割されます。層化分割では、各データパーティションのラベルの比率は同じです。分類問題では、トレーニングフォールドと分類フォールドのラベルの比率を同じにすることが重要です。Data Wrangler は、デフォルトのハイパーパラメータを使用してXGBoostモデルをトレーニングします。検証データに早期停止を適用し、特徴の前処理は最小限に抑えます。
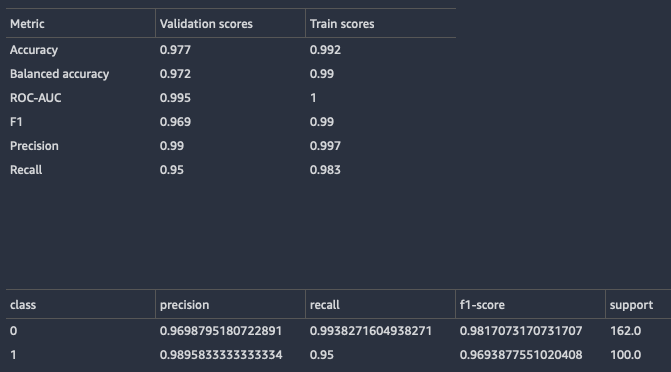
分類モデルの場合、Data Wrangler はモデルの要約と混同行列の両方を返します。
以下は、分類モデルの要約の例です。返される情報の詳細については、「定義」を参照してください。
以下に、クイックモデルが返す混同行列の例を示します。
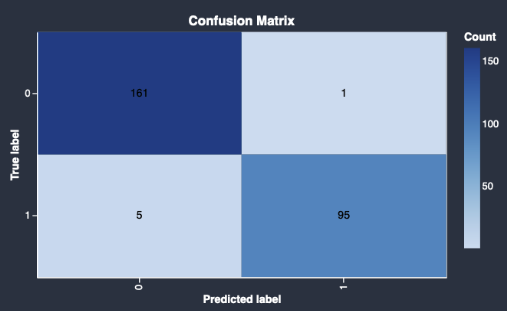
混同行列には、次の情報が表示されます。
-
予測されたラベルが実際のラベルと一致する回数。
-
予測されたラベルが実際のラベルと一致しない回数。
実際のラベルは、データ内の実際の観測値を表します。例えば、モデルを使用して不正取引を検出する場合、実際のラベルは実際に不正または不正でない取引を表します。予測されたラベルは、モデルがデータに割り当てるラベルを表します。
混同行列を使用すると、モデルが条件の有無をどの程度正確に予測できるかを確認できます。不正取引を予測する場合は、混同行列を使用してモデルの感度と特異性の両方を把握できます。感度とは、モデルが不正取引を検出する能力を指します。特異性とは、不正ではない取引を不正な取引として検出することを回避するモデルの能力を指します。
回帰問題のクイックモデル出力の例を次に示します。
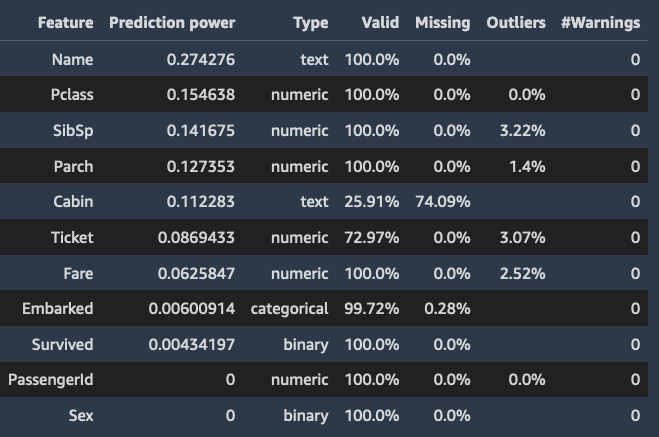
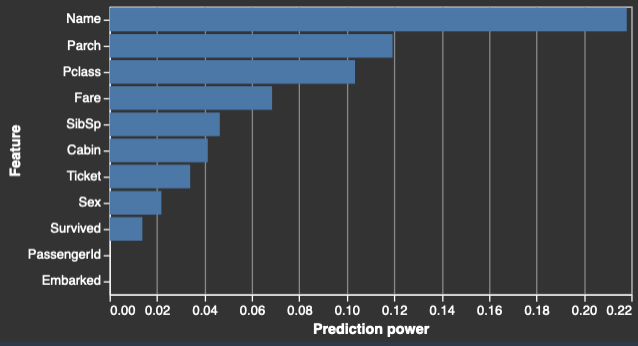
特徴の概要
ターゲット列を指定すると、Data Wrangler は特徴を予測能力の順に並べます。予測能力は、データを 80% のトレーニングフォールドと 20% の検証フォールドに分割した後で測定されます。Data Wrangler は、各特徴のモデルをトレーニングフォールドで別々にあてはめます。最小限の特徴の前処理を適用し、検証データの予測パフォーマンスを測定します。
スコアは [0,1] の範囲に正規化されます。予測スコアが高いほど、その列がターゲットを単独で予測するのに有用であることを示します。スコアが低いほど、列がターゲット列を予測できないことを示します。
単独で予測できない列を他の列と組み合わせて使用することで予測可能になることはまれです。予測スコアを使用して、データセット内の特徴が予測可能かどうかを確信をもって判断できます。
通常、スコアが低い場合は、特徴が冗長であることを示します。スコア 1 は完璧な予測能力を示し、多くの場合はターゲット漏洩を意味します。ターゲット漏洩は通常、予測時に使用できない列がデータセットに含まれている場合に発生します。例えば、ターゲット列と重複している場合があります。
各特徴の予測値を示す表とヒストグラムの例を以下に示します。
サンプル
Data Wrangler は、サンプルが異常かどうか、またはデータセットに重複があるかどうかに関する情報を提供します。
Data Wrangler は、アイソレーションフォレストアルゴリズムを使用して異常サンプルを検出します。アイソレーションフォレストは、データセットの各サンプル (行) に異常スコアを関連付けます。異常スコアが低い場合は、サンプルに異常があることを示します。スコアが高いほど、サンプルに異常がないことを示します。通常、異常スコアが負のサンプルは異常と見なされ、異常スコアが正のサンプルは異常ではないと見なされます。
異常の可能性があるサンプルを調べる場合は、異常な値に注意することをお勧めします。例えば、データの収集と処理におけるエラーによって異常な値になる場合があります。以下は、Data Wrangler によるアイソレーションフォレストアルゴリズムの実装による最も異常なサンプルの例です。異常サンプルを調べる際には、ドメイン知識とビジネスロジックを使用することをお勧めします。
Data Wrangler は重複行を検出し、データ内の重複行の比率を計算します。データソースによっては、有効な重複データが含まれている場合があります。他のデータソースには重複があり、データ収集に問題がある可能性があります。問題のあるデータ収集によって発生した重複サンプルは、データを独立したトレーニングフォールドと検証フォールドに分割することに依存する機械学習プロセスに支障をきたす可能性があります。
サンプルが重複すると影響を受ける可能性があるインサイトレポートの要素は次のとおりです。
-
クイックモデル
-
予測力の推定
-
ハイパーパラメータの自動調整
[行を管理] の [重複データの削除] トランスフォームを使用して、データセットから重複サンプルを削除できます。Data Wrangler は、重複が最も多い行を表示します。
定義
データインサイトレポートで使用される技術用語の定義は次のとおりです。
