翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Debugger XGBoost トレーニングレポートのチュートリアル
このセクションでは、デバッガー XGBoost トレーニングレポートについて具体的に説明します。レポートは、出力テンソル正規表現に応じて自動的にまとめられ、バイナリ分類、複数クラス分類、回帰のトレーニングジョブのタイプが認識されます。
重要
レポートでは、プロットと推奨事項は情報提供のために提供され、決定的ではありません。お客様は情報を独自に評価する責任を負うものとします。
トピック
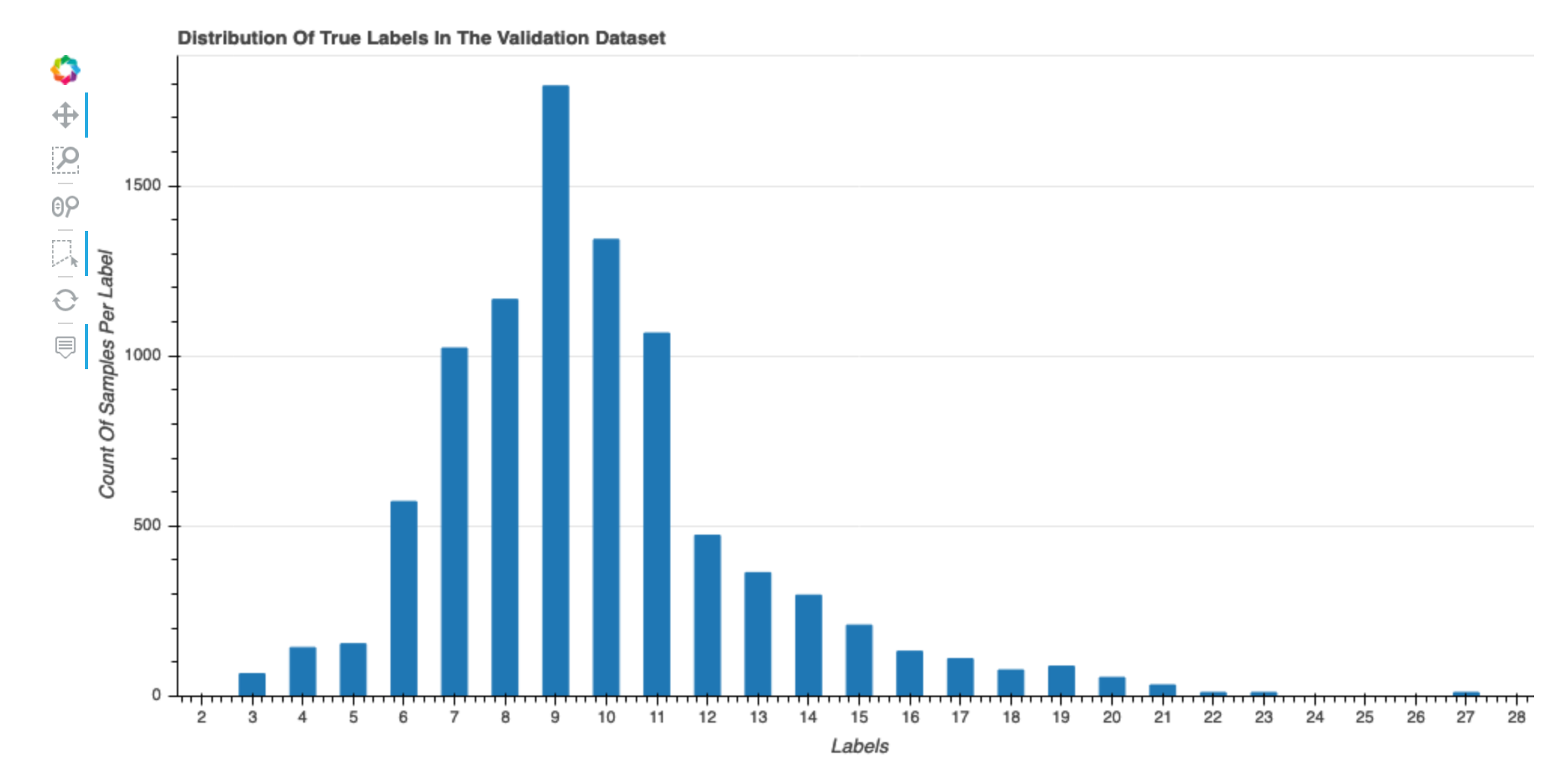
データセットの正解ラベルの分布
このヒストグラムは、元のデータセット内のラベル付けされたクラス (分類用) または値 (回帰用) の分布を示しています。データセットの歪みは、不正確さの原因となる可能性があります。この視覚化は、バイナリ分類、複数クラス分類、回帰のモデルタイプに使用できます。
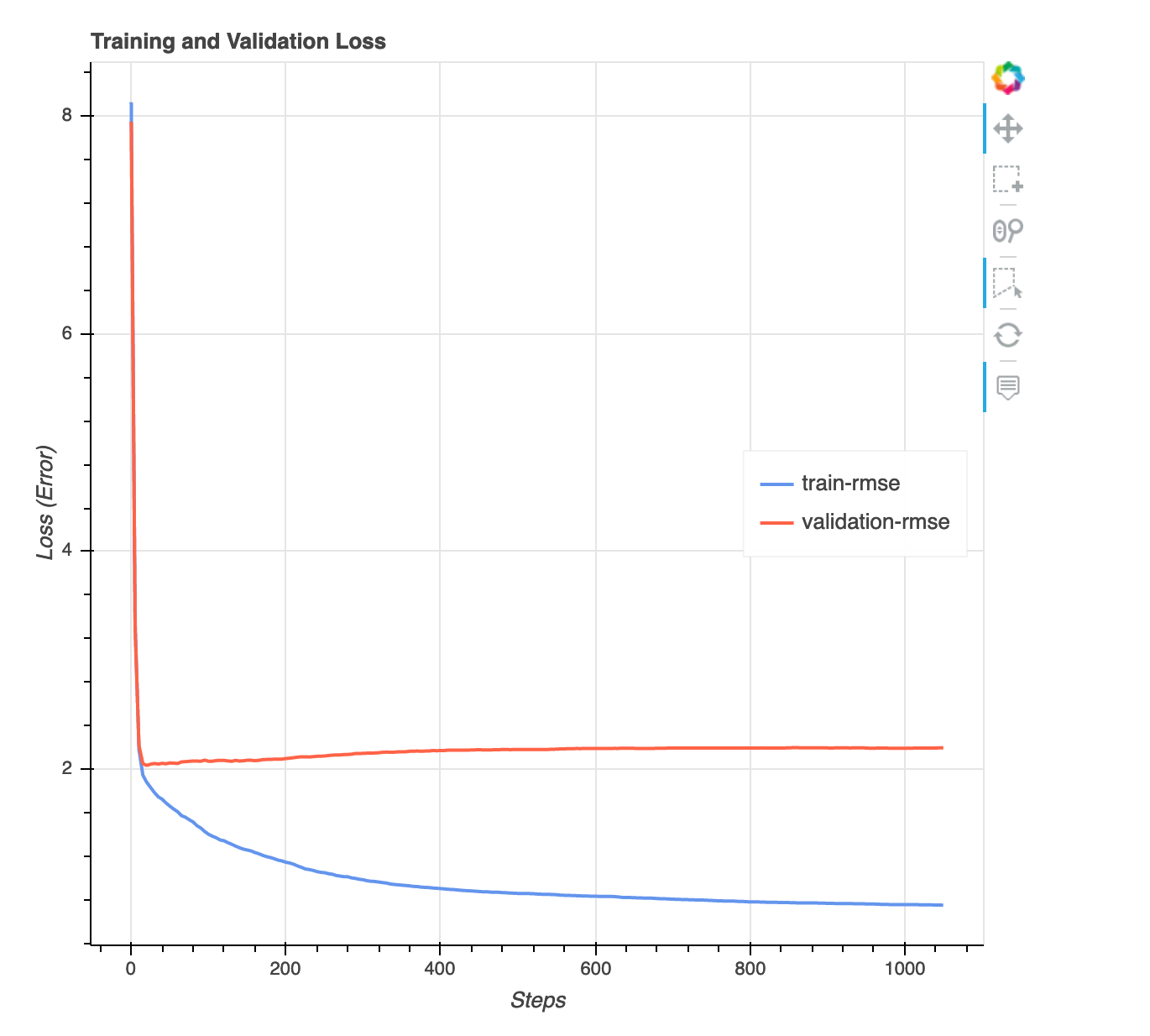
損失対ステップグラフ
これは、トレーニングステップ全体でのトレーニングデータと検証データにおける損失の進行を示す折れ線グラフです。損失は、平均二乗誤差など、目的関数で定義したものです。このプロットから、モデルがオーバーフィットかアンダーフィットかを判断できます。このセクションでは、オーバーフィットおよびアンダーフィット問題の解決方法の決定に使えるインサイトも提供します。この視覚化は、バイナリ分類、複数クラス分類、回帰のモデルタイプに使用できます。
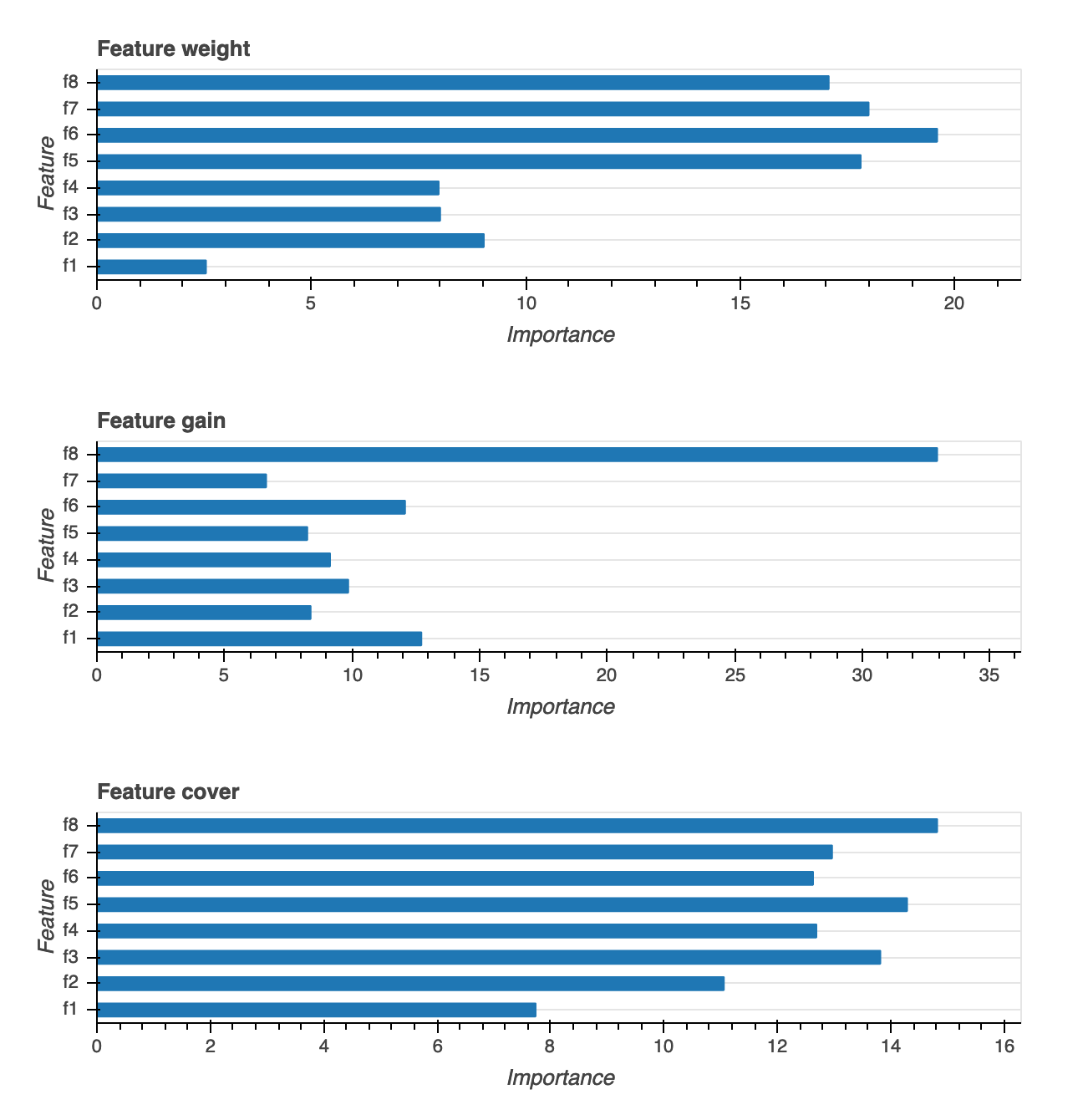
特徴量重要度
特徴の重要度の視覚化には、ウェイト、ゲイン、カバレッジという 3 つの異なるタイプが用意されています。それぞれの詳細な定義については、レポートで説明しています。特徴の重要度の視覚化により、トレーニングデータセット内のどの特徴が予測に貢献したかがわかります。特徴の重要度の視覚化は、バイナリ分類、複数クラス分類、回帰のモデルタイプで使用できます。
混同行列
この視覚化は、バイナリ分類モデルと複数クラス分類モデルにのみ適用されます。精度だけではモデルのパフォーマンスを評価するのに十分ではないことがあります。ヘルスケアや不正検出などの一部のユースケースでは、偽陽性率と偽陰性率を知ることも重要です。混同行列は、モデルのパフォーマンスを評価するための追加のディメンションを提供します。

混同行列の評価
このセクションでは、モデルの適合率、再現率、F1 スコアに関するマイクロ、マクロ、加重メトリクスについて、より多くのインサイトを提供します。
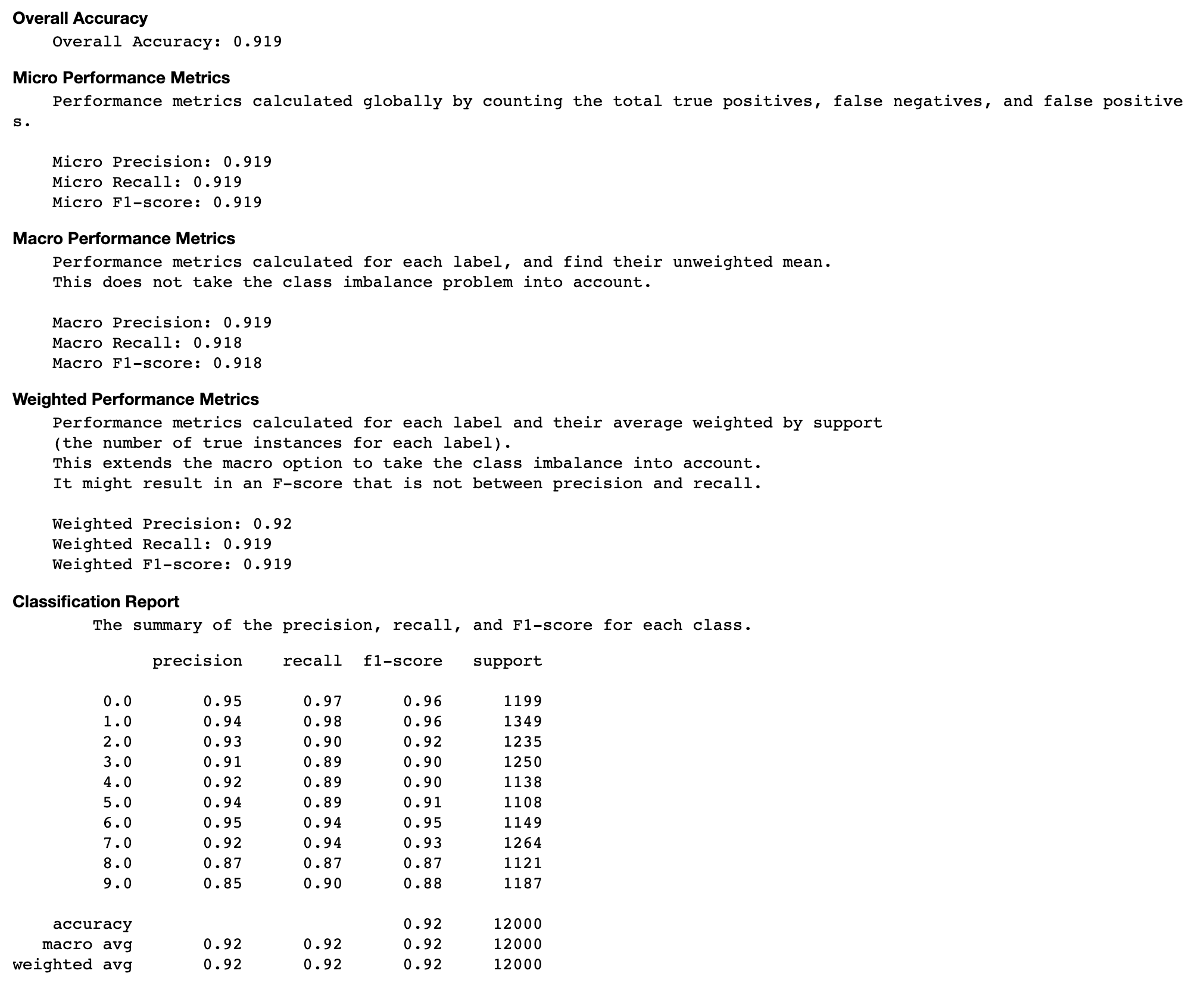
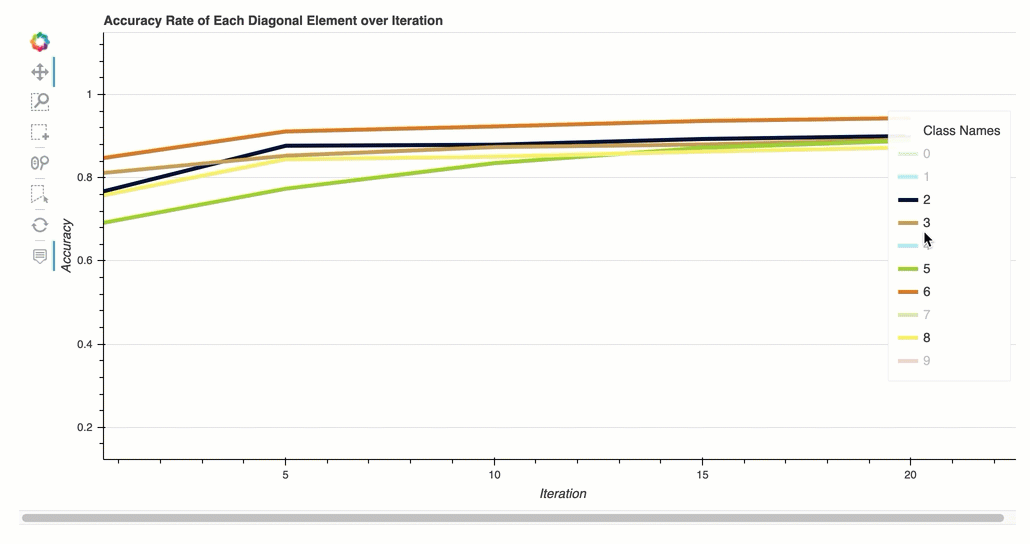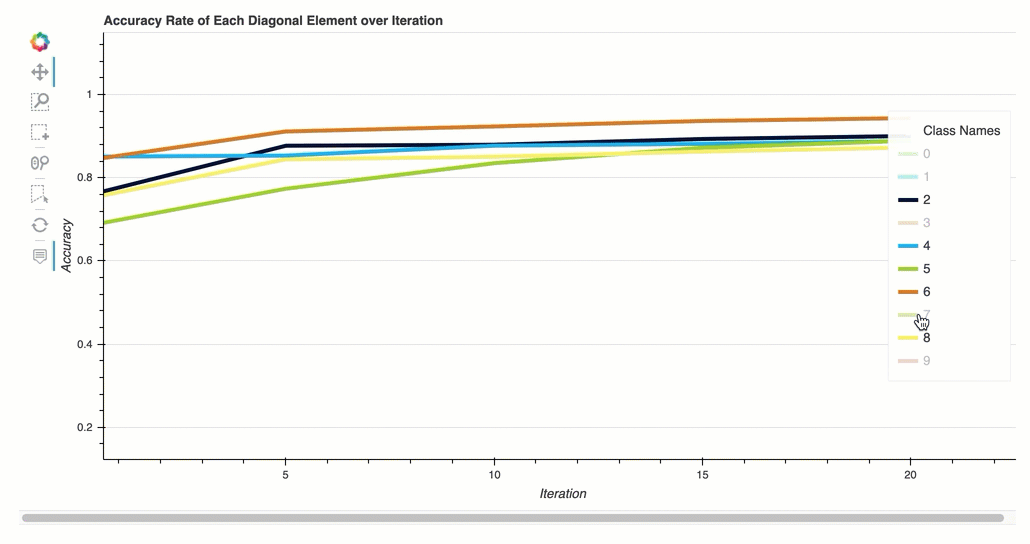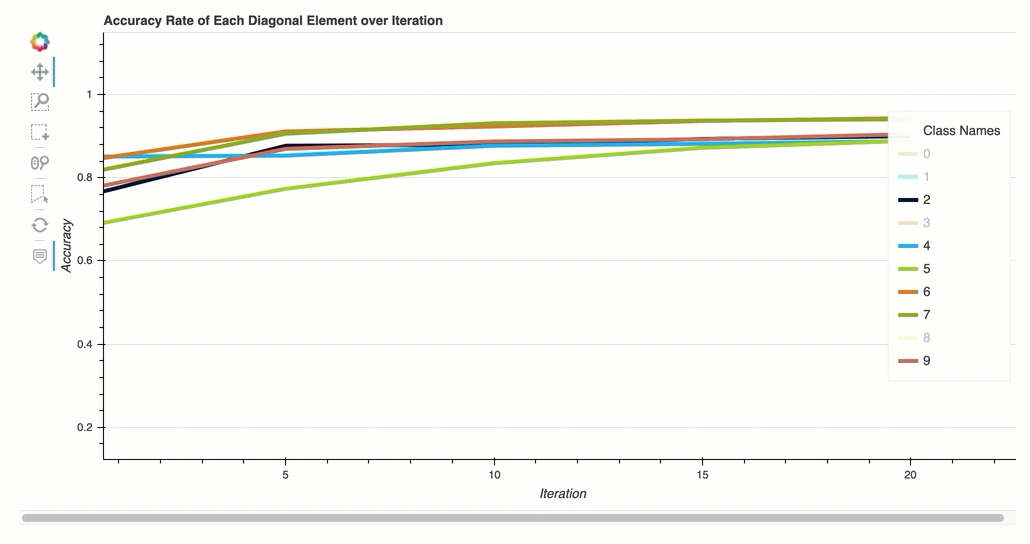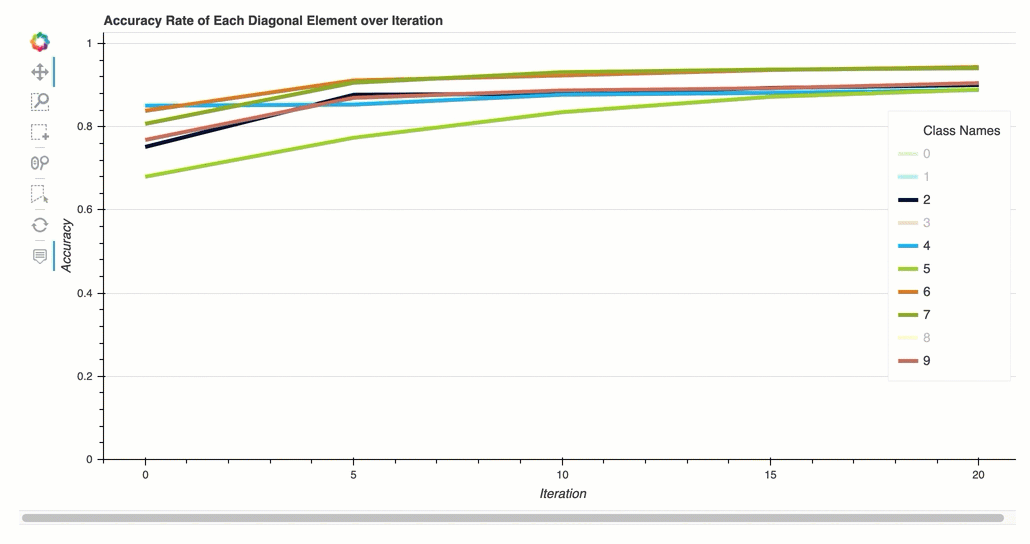
反復における各対角要素の正解率
この視覚化は、バイナリ分類モデルと複数クラス分類モデルにのみ適用されます。これは、各クラスのトレーニングステップ全体を通して、混同行列の対角値をプロットした折れ線グラフです。このプロットは、トレーニングステップ全体を通じて、各クラスの精度がどのように進歩するかを示します。このプロットから、パフォーマンスの低いクラスを特定できます。
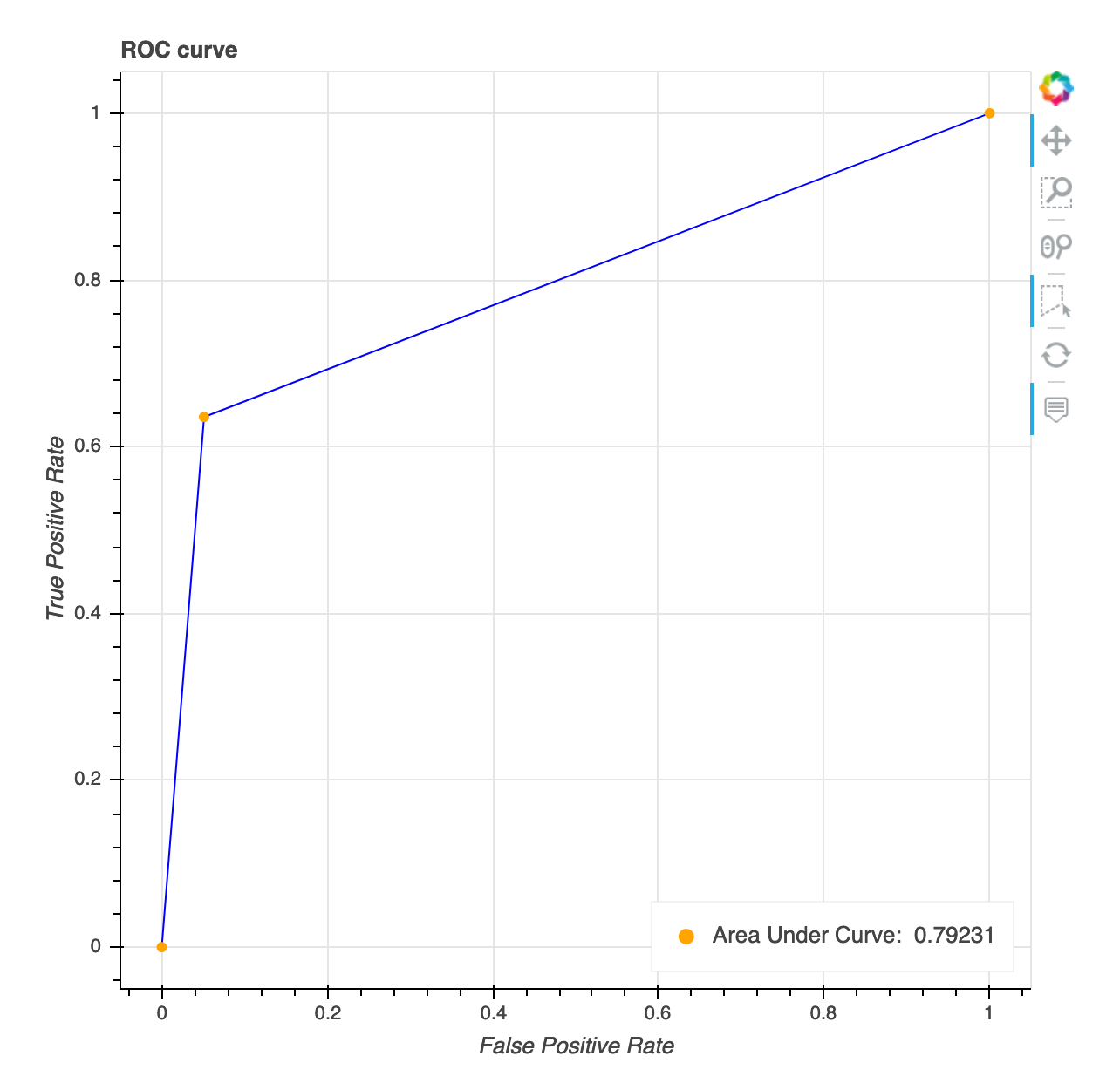
受信者操作特性曲線
この視覚化は、バイナリ分類モデルにのみ適用されます。受信者操作特性曲線は、バイナリ分類モデルのパフォーマンスを評価するために一般的に使用されます。曲線の Y 軸は真陽性率 (TPF)、X 軸は偽陽性率 (FPR) です。プロットには、曲線下面積 (AUC) の値も表示されます。AUC 値が大きいほど、分類器の予測度が高くなります。また、ROC 曲線を使って TPR と FPR の間のトレードオフを理解し、ユースケースに最適な分類しきい値を特定することもできます。分類しきい値を調整することで、モデルの動作を調整し、いずれかのタイプのエラー (FP/FN) を減らすことができます。
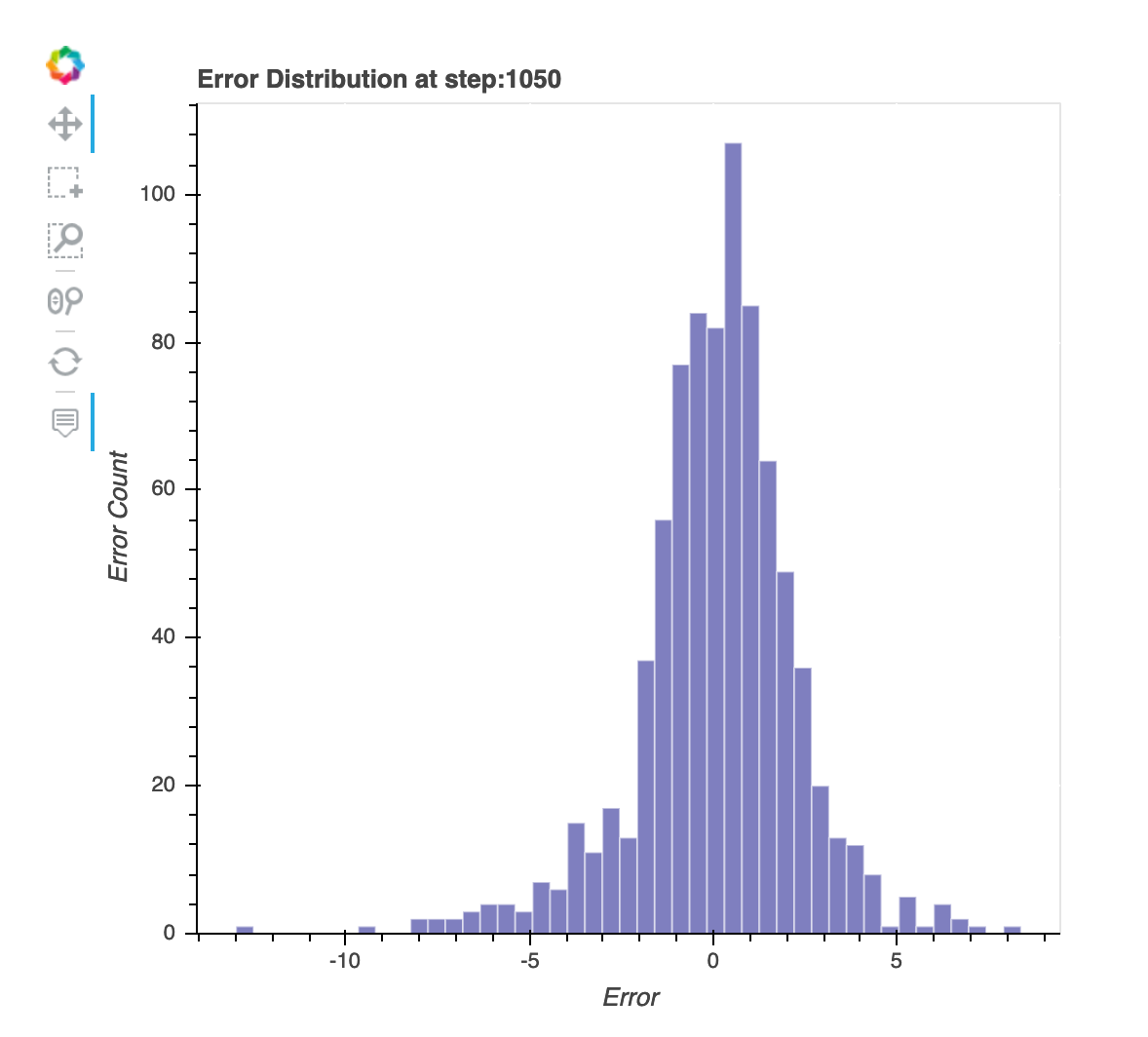
最後に保存したステップでの残差の分布
この視覚化は、デバッガーがキャプチャする最後のステップの残差分布を示す縦棒グラフです。この視覚化では、残差分布がゼロを中心とする正規分布に近いかどうかをチェックできます。残差が歪んでいる場合、特徴はラベルを予測するのに十分ではない可能性があります。
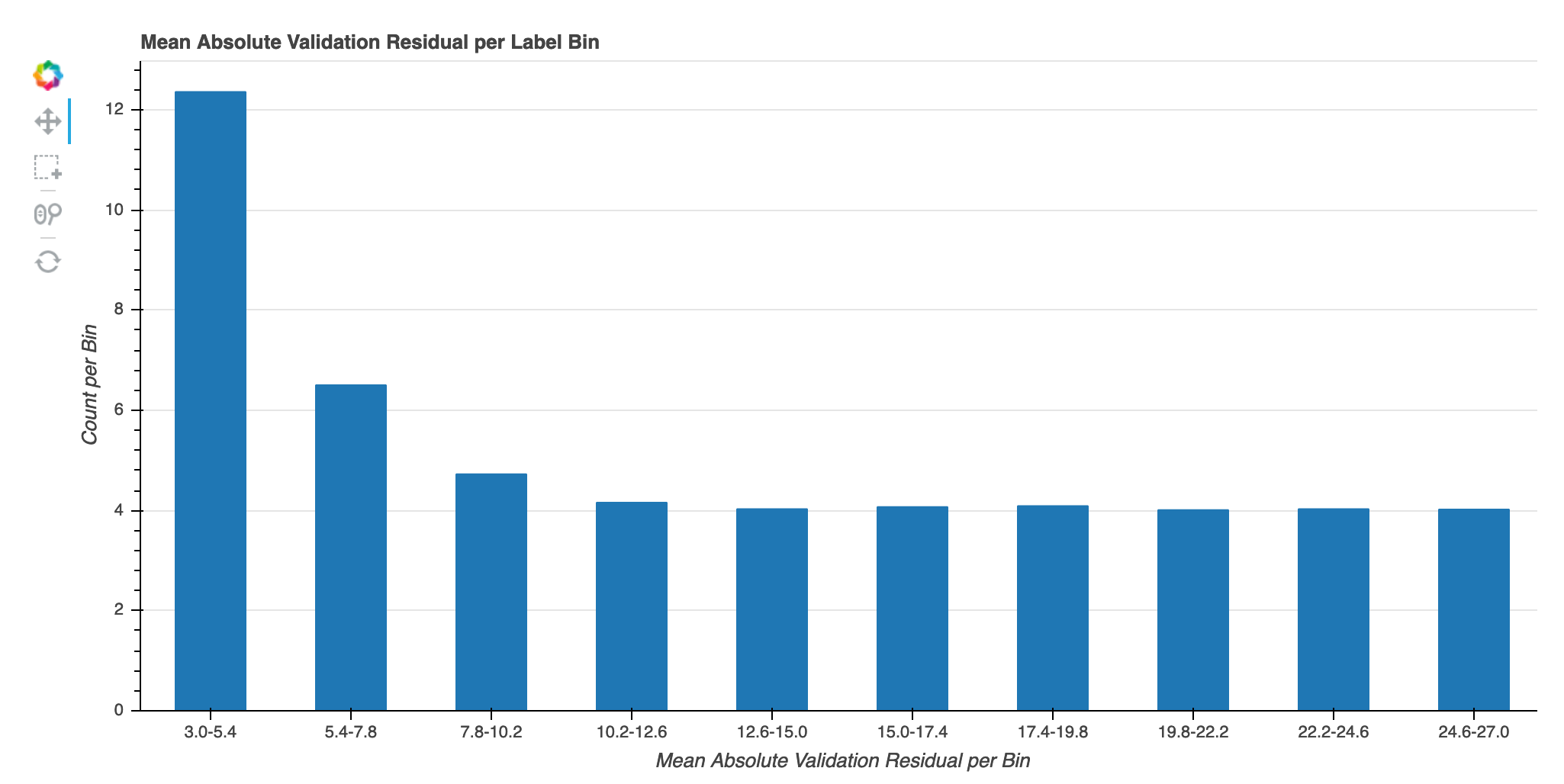
反復におけるラベルビンあたりの絶対検証エラー
この視覚化は、回帰モデルにのみ適用されます。実際のターゲット値は 10 間隔に分割されます。この視覚化では、トレーニングステップ全体で、各間隔の検証エラーがどのように進行するかをラインプロットで表示します。絶対検証エラーは、検証時の予測値と実際値の差の絶対値です。この視覚化から、パフォーマンスの低い間隔を特定できます。