翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon でモデルをデプロイし、推論を得るためのオプションを理解する SageMaker
SageMaker 推論の使用を開始するには、 でモデルをデプロイ SageMaker して推論を取得するためのオプションを説明する以下のセクションを参照してください。Amazon の推論オプション SageMaker このセクションは、推論のユースケースに最適な機能を判断するのに役立ちます。
トラブルシューティングとリファレンス情報の詳細については、 リソースセクション、開始に役立つブログと例、一般的な を参照してくださいFAQs。
トピック
開始する前に
これらのトピックは、1 つ以上の機械学習モデルを構築およびトレーニングし、それらのモデルをデプロイする準備ができていることを前提としています。にモデルをデプロイ SageMaker して推論を取得するために SageMaker 、 でモデルをトレーニングする必要はありません。独自のモデルがない場合は、 SageMakerの組み込みアルゴリズムまたは事前トレーニング済みモデルを使用することもできます。
デプロイするモデルを初めて選択 SageMaker していなければ、「Amazon チュートリアルの開始方法 SageMaker」のステップを実行します。チュートリアルを使用して、 が SageMakerデータサイエンスプロセスを管理し、モデルデプロイを処理する方法を理解します。モデルトレーニングの詳細については、「モデルのトレーニング」を参照してください。
追加情報、リファレンス、および例については、「リソース」を参照してください。
モデルをデプロイするための手順
推論エンドポイントの一般的なワークフローは以下のとおりです。
Amazon S3 SageMaker に保存されているモデルアーティファクトとコンテナイメージを指して、推論でモデルを作成します。
推論オプションを選択します。詳細については、「Amazon の推論オプション SageMaker」を参照してください。
インスタンスタイプとエンドポイントの背後に必要なインスタンス数を選択して、 SageMaker 推論エンドポイント設定を作成します。Amazon SageMaker Inference Recommender を使用して、インスタンスタイプのレコメンデーションを取得できます。サーバーレス推論の場合は、モデルサイズに基づいて必要なメモリ設定を指定するだけです。
SageMaker 推論エンドポイントを作成します。
エンドポイントを呼び出して、推論をレスポンスとして受け取ります。
次の図は、ここまでのワークフローを示しています。
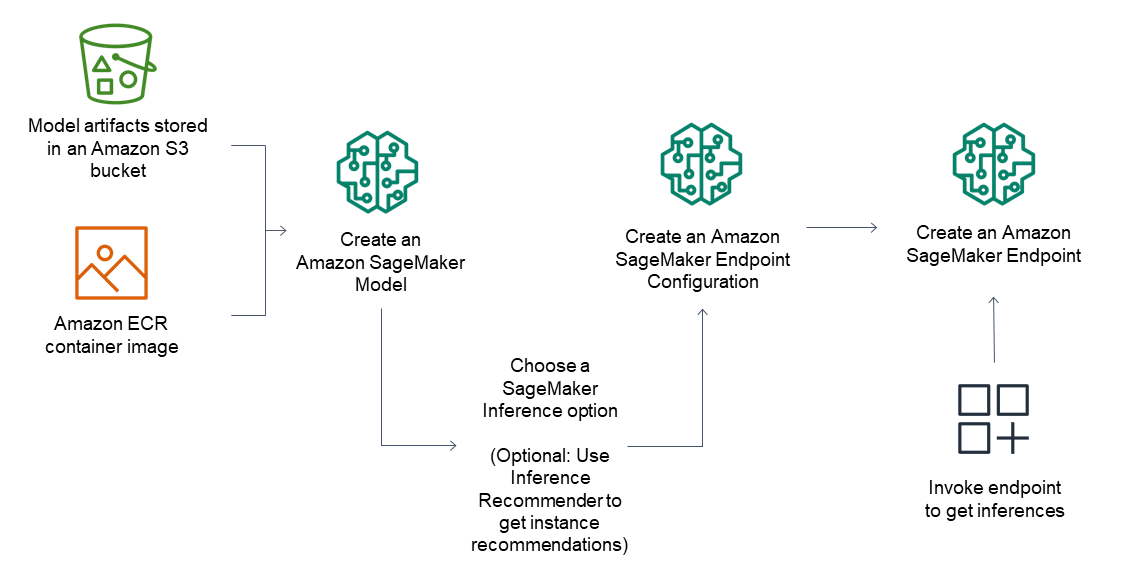
これらのアクションは、 AWS コンソール、 AWS SDKs、 SageMaker Python SDK、 AWS CloudFormation または を使用して実行できます AWS CLI。
バッチ変換によるバッチ推論の場合は、モデルアーティファクトと入力データを指定し、バッチ推論ジョブを作成します。推論用のエンドポイントをホストする代わりに、 SageMaker は任意の Amazon S3 ロケーションに推論を出力します。
