翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルを評価する
Amazon SageMaker AI を使用してモデルをトレーニングおよびデプロイしたところで、モデルを評価し、新しいデータに対して正確な予測が生成されることを確認します。モデルの評価には、「データセットを準備する」で作成したテストデータセットを使用します。
SageMaker AI ホスティングサービスにデプロイしたモデルを評価する
モデルを評価して本番環境で使用するには、テストデータセットを使用してエンドポイントを呼び出し、取得した推論によって、達成する目標精度が返されるかどうかを確認します。
モデルを評価するには
-
次の関数を設定して、テストセットの各行を予測します。次のサンプルコードでは、
rows引数で、一度に予測する行の数を指定します。この値を変更すると、インスタンスのハードウェアリソースを完全に利用するバッチ推論を実行できます。import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
次のコードを実行して、テストデータセットの予測を行い、ヒストグラムをプロットします。実際の値の 0 列目を除外し、テストデータセットの特徴列のみを取得する必要があります。
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()
-
予測値は浮動小数点タイプです。浮動小数点値に基づいて
TrueまたはFalseを決定するには、カットオフ値を設定する必要があります。次のサンプルコードに示すように、Scikit-learn ライブラリを使用すると、0.5 のカットオフを使用した出力混同メトリクスと分類レポートが返されます。import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))この場合、次のような混同行列が返されます。
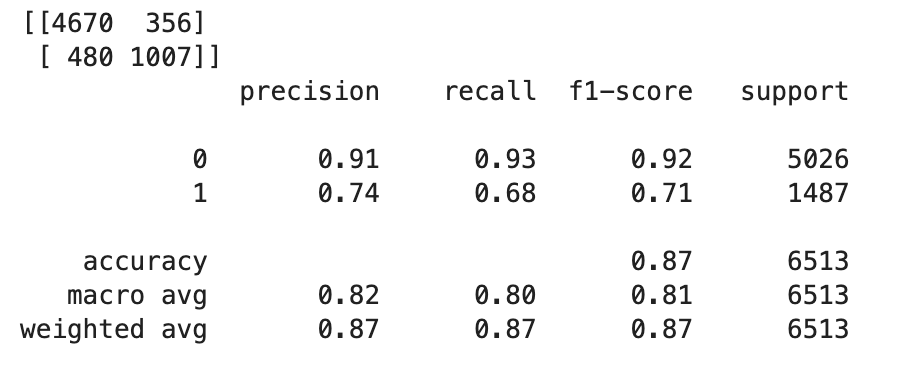
-
特定のテストセットで最適なカットオフを求めるには、ロジスティック回帰の対数損失関数を計算します。対数損失関数は、Ground Truth ラベルの予測確率を返すロジスティックモデルの負の対数尤度として定義されます。次のサンプルコードは、対数損失値を数値順かつ反復的に計算します (
-(y*log(p)+(1-y)log(1-p)) 。ここでyは実際のラベルであり、pは対応するテストサンプルの確率推定値です。この場合、対数損失とカットオフのグラフが返されます。import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()次のような対数損失曲線が返されます。
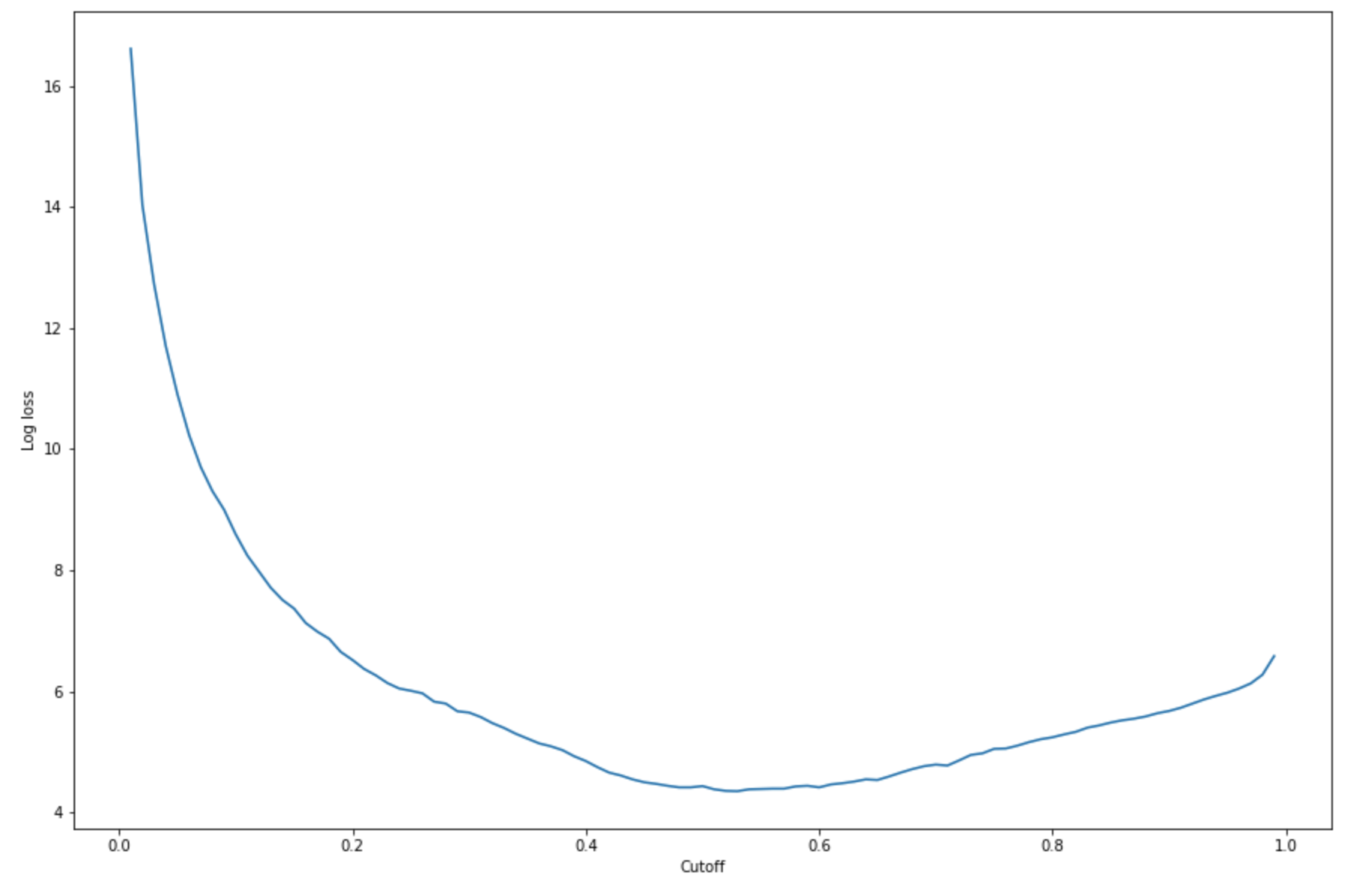
-
NumPy
argminとminの関数を使用して、誤差曲線の最小点を求めます。print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )この場合、次のようなメッセージが返されます:
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897。対数損失関数を計算して最小化する代わりに、代替としてコスト関数を見積もることができます。例えば、顧客離れ予測問題などのビジネス問題の二項分類を実行するようにモデルをトレーニングする場合、混同行列の要素に重みを設定することによって、それぞれに対応するコスト関数を計算できます。
これで、SageMaker AI で最初のモデルのトレーニング、デプロイ、評価が完了しました。
ヒント
モデルの品質、データ品質、バイアスドリフトをモニタリングするには、Amazon SageMaker Model Monitor と SageMaker AI Clarify を使用します。詳細については、「Amazon SageMaker Model Monitor」、「データの品質をモニタリングする」、「モデルの品質をモニタリングする」、「バイアスドリフトをモニタリングする」、「特徴属性ドリフトをモニタリングする」を参照してください。
ヒント
信頼性の低い機械学習予測または予測のランダムなサンプルの人間によるレビューを取得する場合は、Amazon Augmented AI の人間によるレビューワークフローを使用します。詳細については、「Amazon Augmented AI を使用したヒューマンレビュー」を参照してください。
