翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルホスティングに関するよくある質問
SageMaker AI 推論ホスティングに関するよくある質問への回答については、次のよくある質問項目を参照してください。
ホスティング全般
以下のよくある質問項目は、SageMaker AI 推論に関する一般的な質問に回答しています。
A: モデルを構築してトレーニングした後、Amazon SageMaker AI にはモデルをデプロイするための 4 つのオプションが用意されているため、予測を開始できます。リアルタイム推論は、レイテンシー要件がミリ秒単位、ペイロードサイズが最大 6 MB、処理時間が最大 60 秒のワークロードに適しています。バッチ変換は、事前に利用可能な大量のデータをオフラインで予測する場合に最適です。非同期推論は、1 秒未満のレイテンシーを必要とせず、ペイロードサイズが最大 1 GB、処理時間が最長 15 分のワークロード向けに設計されています。サーバーレス推論では、基盤となるインフラストラクチャを設定したり管理したりすることなく、推論用の機械学習モデルを迅速にデプロイできます。また、推論リクエストの処理に使用したコンピューティング能力に対してのみ支払いが発生するため、断続的なワークロードに最適です。
A: 次の図は、SageMaker AI ホスティングモデルのデプロイオプションを選択するのに役立ちます。
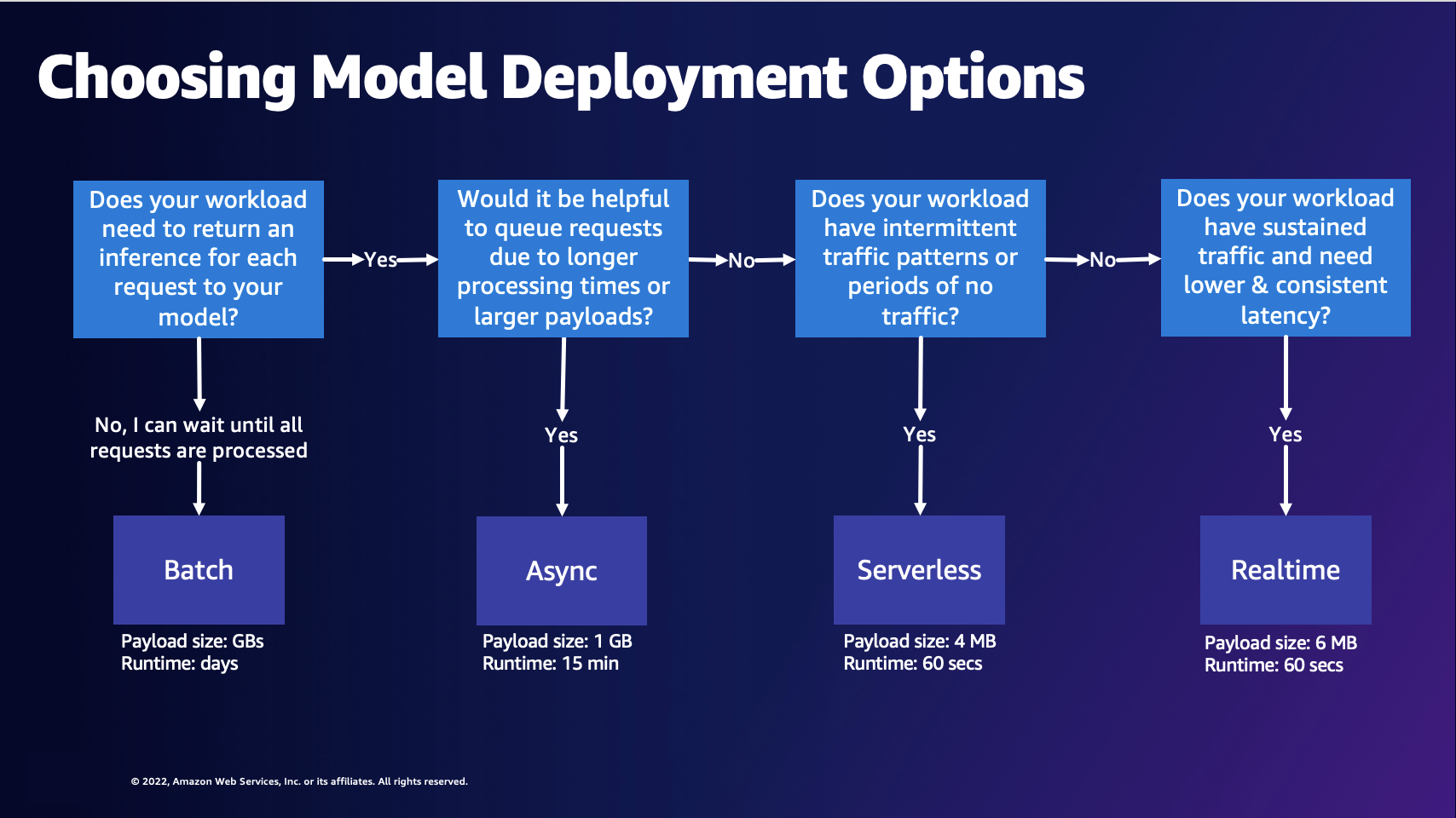
前の図では、次の決定プロセスを順を追って説明しています。リクエストをバッチ処理する場合は、バッチ変換を選択するとよいでしょう。それ以外の場合、モデルへのリクエストごとに推論を受け取りたい場合は、非同期推論、サーバーレス推論、またはリアルタイム推論を選択するとよいでしょう。処理時間が長い場合やペイロードが大きく、リクエストをキューに入れる場合は、非同期推論を選択できます。ワークロードに予測不能なトラフィックや断続的なトラフィックがある場合は、サーバーレス推論を選択できます。持続的なトラフィックで、リクエストのレイテンシーを低く一定に抑える必要がある場合は、リアルタイム推論を選択できます。
A: SageMaker AI 推論でコストを最適化するには、ユースケースに適したホスティングオプションを選択する必要があります。Amazon SageMaker AI Savings Plans
A: パフォーマンスを向上させコストを削減するために適切なエンドポイント設定に関する推奨事項が必要な場合は、Amazon SageMaker 推論レコメンダーを使用する必要があります。以前は、モデルをデプロイするデータサイエンティストは、手動でベンチマークを実行して適切なエンドポイント設定を選択する必要がありました。まず、70 種類以上のインスタンスタイプの中からモデルのリソース要件とサンプルペイロードに基づいて適切な機械学習インスタンスタイプを選択し、次に異なるハードウェアに合わせてモデルを最適化する必要がありました。次に、広範囲にわたる負荷テストを実施して、レイテンシーとスループットの要件が満たされていること、およびコストが低いことを検証する必要がありました。推論レコメンダーは、以下のことを行うのに役立つため、このような複雑さを解消できます。
-
インスタンスレコメンデーションがあれば数分で始められます。
-
インスタンスタイプ全体で負荷テストを実施して、エンドポイント設定に関する推奨事項を数時間以内に取得します。
-
コンテナとモデルサーバーのパラメーターを自動的に調整し、特定のインスタンスタイプに合わせてモデル最適化を実行します。
A: SageMaker AI エンドポイントは、モデルサーバーを含むコンテナ化されたウェブサーバーを使用する HTTP REST エンドポイントです。これらのコンテナは、機械学習モデルのリクエストをロードして処理します。これらにはポート 8080 の /invocations と /ping に応答するウェブサーバーを実装する必要があります。
一般的なモデルサーバーには、TensorFlow Serving、TorchServe、マルチモデルサーバーがあります。SageMaker AI フレームワークコンテナには、これらのモデルサーバーが組み込まれています。
A: SageMaker AI 推論のすべてのものがコンテナ化されます。SageMaker AI は、TensorFlow、SKlearn、HuggingFace などの一般的なフレームワーク用のマネージドコンテナを提供します。これらのイメージの包括的な最新リストについては、「Available Images
カスタムフレームワークによっては、そのためにコンテナを構築する必要がある場合があります。このアプローチは、「独自のコンテナの持ち込み」または「BYOC」と呼ばれています。BYOC アプローチでは、Docker イメージを提供してフレームワークまたはライブラリを設定します。次に、イメージを Amazon Elastic Container Registry (Amazon ECR) にプッシュして、SageMaker AI でイメージを使用できるようにします。BYOC アプローチの例については、「Overivew of Containers for Amazon SageMaker AI
イメージをゼロから構築する代わりに、コンテナを拡張することもできます。SageMaker AI が提供するベースイメージの 1 つを取得し、その上に依存関係を Dockerfile に追加できます。
A: SageMaker AI は、SageMaker AI の外部でトレーニングした独自のトレーニング済みフレームワークモデルを持ち込んで、任意の SageMaker AI ホスティングオプションにデプロイする機能を提供します。
SageMaker AI では、モデルをmodel.tar.gzファイルにパッケージ化し、特定のディレクトリ構造を持つ必要があります。各フレームワークには独自のモデル構造があります (構造の例については、次の質問を参照してください)。詳細については、「TensorFlow
TensorFlow、PyTorch、MXNet などの構築済みのフレームワークイメージから選択してトレーニング済みモデルをホストできますが、独自のコンテナを構築してトレーニング済みモデルを SageMaker AI エンドポイントでホストすることもできます。チュートリアルについては、Jupyter ノートブックの例「Building your own algorithm container
A: SageMaker AI では、モデルアーティファクトを.tar.gzファイルまたは tarball で圧縮する必要があります。SageMaker AI は、この.tar.gzファイルをコンテナの /opt/ml/model/ ディレクトリに自動的に抽出します。tarball にはシンボリックリンクや不要なファイルが含まれていてはなりません。TensorFlow、PyTorch、MXNet などのフレームワークコンテナのいずれかを使用している場合、コンテナは TAR 構造が次のようになることを想定しています。
TensorFlow
model.tar.gz/ |--[model_version_number]/ |--variables |--saved_model.pb code/ |--inference.py |--requirements.txt
PyTorch
model.tar.gz/ |- model.pth |- code/ |- inference.py |- requirements.txt # only for versions 1.3.1 and higher
MXNet
model.tar.gz/ |- model-symbol.json |- model-shapes.json |- model-0000.params |- code/ |- inference.py |- requirements.txt # only for versions 1.6.0 and higher
A: ContentType は、リクエスト本文の入力データの MIME タイプ (エンドポイントに送信するデータの MIME タイプ) です。モデルサーバーは ContentType を使用して、指定されたタイプを処理できるかどうかを判断します。
Accept は、推論レスポンスの MIME タイプ (エンドポイントが返すデータの MIME タイプ) です。モデルサーバーは Accept タイプを使用して、指定されたタイプを返す処理ができるかどうかを判断します。
一般的な MIME タイプには text/csv、application/json、application/jsonlines などがあります。
A: SageMaker AI は、変更なしでモデルコンテナにリクエストを渡します。コンテナにはリクエストを逆シリアル化するロジックが含まれている必要があります。組み込みアルゴリズムに定義されている形式については、「Common Data Formats for Inference」を参照してください。独自のコンテナを構築している場合、または SageMaker AI Framework コンテナを使用している場合は、選択したリクエスト形式を受け入れるロジックを含めることができます。
同様に、SageMaker AI も変更せずにレスポンスを返し、クライアントはレスポンスを逆シリアル化する必要があります。組み込みアルゴリズムの場合は、特定の形式でレスポンスが返されます。独自のコンテナを構築している場合、または SageMaker AI Framework コンテナを使用している場合は、選択した形式でレスポンスを返すロジックを含めることができます。
Invoke Endpoint API 呼び出しを使用して、エンドポイントに対する推論を行います。
入力をペイロードとして InvokeEndpoint API に渡すときは、モデルが必要とする正しいタイプの入力データを提供する必要があります。InvokeEndpoint API 呼び出しでペイロードを渡すと、リクエストバイトはモデルコンテナに直接転送されます。例えば、イメージの場合は、ContentType に application/jpeg を使用して、モデルがこのタイプのデータに対して推論を実行できることを確認できます。これは JSON、CSV、動画、または処理対象となるその他の種類の入力に当てはまります。
考慮すべきもう 1 つの要素は、ペイロードサイズの制限です。リアルタイムエンドポイントとサーバーレスエンドポイントでは、ペイロードの上限は 6 MB です。動画を複数のフレームに分割し、フレームごとにエンドポイントを個別に呼び出すことができます。ユースケースが許せば、最大 1 GB のペイロードをサポートする非同期エンドポイントを使用して、ペイロード内の動画全体を送信することもできます。
非同期推論を使用して大きな動画でコンピュータービジョン推論を実行する方法を示す例については、こちらのブログ記事
リアルタイム推論
以下のよくある質問項目は、SageMaker AI Real-Time Inference に関する一般的な質問に回答しています。
A: SageMaker AI エンドポイントは、 AWS SDKs、SageMaker Python SDK、、 AWS Management Console AWS CloudFormationなどの AWSサポートされているツールを使用して作成できます AWS Cloud Development Kit (AWS CDK)。
エンドポイントの作成には、SageMaker AI モデル、SageMaker AI エンドポイント設定、SageMaker AI エンドポイントの 3 つの主要なエンティティがあります。SageMaker AI モデルは、使用しているモデルデータとイメージを指します。エンドポイント設定は、インスタンスタイプやインスタンス数を含む本番稼働用バリアントを定義します。その後、create_endpoint
A: いいえ。さまざまな AWS SDKs「呼び出し/作成」を参照)、対応するウェブ APIsを直接呼び出すこともできます。 SDKs
A: マルチモデルエンドポイントは、SageMaker AI が提供するリアルタイム推論オプションです。マルチモデルエンドポイントを使用すると、1 つのエンドポイントで数千のモデルをホストできます。マルチモデルサーバー
A: SageMaker AI Real-Time Inference は、マルチモデルエンドポイント、マルチコンテナエンドポイント、シリアル推論パイプラインなど、さまざまなモデルデプロイアーキテクチャをサポートしています。
マルチモデルエンドポイント (MME) – MME を使用すると、高度にパーソナライズされた何千ものモデルを費用対効果の高い方法でデプロイできます。すべてのモデルは共有リソースフリートにデプロイされます。MME は、モデルのサイズとレイテンシーが似ていて、同じ ML フレームワークに属している場合に最も効果的です。これらのエンドポイントは、常に同じモデルを呼び出す必要がない場合に最適です。各モデルを SageMaker AI エンドポイントに動的にロードして、リクエストに対応できます。
マルチコンテナエンドポイント (MCE) – MCE では、お客様は 1 つの SageMaker エンドポイントのみを使用しながら、コールドスタートなしで多様な ML フレームワークと機能を備えた 15 種類のコンテナをデプロイできます。これらのコンテナは直接呼び出すことができます。MCE は、すべてのモデルをメモリ内に保持したい場合に最適です。
シリアル推論パイプライン (SIP) – SIP を使用すると、1 つのエンドポイントに 2~15 個のコンテナをつなぎ合わせることができます。SIP は、前処理とモデル推論を 1 つのエンドポイントにまとめる場合や、低レイテンシーの操作に最も適しています。
サーバーレス推論
以下の FAQ 項目は、Amazon SageMaker サーバーレス推論に関する一般的な質問に回答しています。
A: Amazon SageMaker Serverless Inference を使用してモデルをデプロイする は、ML モデルのデプロイとスケーリングを容易にする専用のサーバーレスモデルサービスオプションです。サーバーレス推論エンドポイントは、コンピューティングリソースを自動的に開始し、トラフィックに応じてスケールインおよびスケールアウトできるため、インスタンスタイプを選択したり、プロビジョンドキャパシティを実行したり、スケーリングを管理したりする必要がなくなります。オプションで、サーバーレスエンドポイントのメモリ要件を指定できます。課金されるのは、推論コードの実行期間と処理されたデータ量だけで、アイドル期間には課金されません。
A: サーバーレス推論を使用すると、事前に容量をプロビジョニングしたり、スケーリングポリシーを管理したりする必要がなくなるため、開発者のエクスペリエンスが簡素になります。サーバーレス推論は、使用パターンに基づいて数秒で数十から数千の推論まで瞬時にスケーリングできるため、トラフィックが断続的または予測不可能な ML アプリケーションに最適です。例えば、給与処理会社が使用するチャットボットサービスでは、月末には問い合わせが増え、その月の残りの期間はトラフィックが断続的に発生するとします。このようなシナリオでは、1 か月分のインスタンスをプロビジョニングしても、結局はアイドル期間分の料金を支払うことになるため、費用対効果が高くありません。
サーバーレス推論は、トラフィックを事前に予測したり、スケーリングポリシーを管理したりすることなく、すぐに自動的かつ迅速にスケーリングできるため、このようなユースケースに対処するのに役立ちます。さらに、推論コードの実行とデータ処理にかかるコンピューティング時間に対してのみ支払いが発生するため、トラフィックが断続的に発生するワークロードに最適です。
A: サーバーレスエンドポイントの最小 RAM サイズは 1024 MB(1 GB) で、選択できる最大 RAM サイズは 6144 MB(6 GB)です。選択できるメモリサイズは、1024 MB、2048 MB、3072 MB、4096 MB、5120 MB、6144 MBです。サーバーレス推論は、選択したメモリに比例してコンピューティングリソースを自動的に割り当てます。より大きなメモリサイズを選択すると、コンテナはより多くの vCPUs にアクセスできます。
モデルサイズに応じて、エンドポイントのメモリサイズを選択します。一般に、メモリサイズは少なくともモデルサイズと同じ大きさである必要があります。レイテンシー SLA に基づいてモデルに適したメモリを選択するために、ベンチマークが必要になる場合があります。メモリサイズの増分の料金は異なります。詳細については、Amazon SageMaker AI の料金」ページ
バッチ変換
以下のよくある質問項目は、SageMaker AI バッチ変換に関する一般的な質問に回答しています。
A: CSV、RecordIO、TFRecord などの特定のファイル形式の場合、SageMaker AI はデータを単一レコードまたは複数レコードのミニバッチに分割し、これをペイロードとしてモデルコンテナに送信できます。の値が BatchStrategyの場合MultiRecord、SageMaker AI は各リクエストの最大レコード数をMaxPayloadInMB上限として送信します。の値が BatchStrategyの場合SingleRecord、SageMaker AI は各リクエストで個々のレコードを送信します。
A: バッチ変換の最大タイムアウトは 3600 秒です。レコード (ミニバッチあたり) の最大ペイロードサイズは 100 MB です。
A: CreateTransformJob API を使用している場合、MaxPayloadInMB、MaxConcurrentTransforms、BatchStrategy などのパラメータに最適値を使用することで、バッチ変換ジョブの完了にかかる時間を短縮できます。MaxConcurrentTransforms の理想的な値は、バッチ変換ジョブに含まれるコンピューティングワーカーの数と同じです。SageMaker AI コンソールを使用している場合は、バッチ変換ジョブ設定ページの「追加設定」セクションでこれらの最適なパラメータ値を指定できます。SageMaker AI は、組み込みアルゴリズムに最適なパラメータ設定を自動的に見つけます。カスタムアルゴリズムの場合は、これらの値を execution-parameters エンドポイントを通じて指定します。
A: バッチ変換は CSV と JSON をサポートしています。
非同期推論
以下のよくある質問項目は、SageMaker AI 非同期推論に関する一般的な質問に回答しています。
非同期推論を使用して、受信した推論リクエストをキューに入れて非同期に処理します。このオプションは、ペイロードサイズが大きいリクエストや、到着時に処理する必要があるリクエストの処理時間が長いリクエストに最適です。オプションで、リクエストをアクティブに処理していないときにインスタンス数をゼロにスケールダウンするように Auto Scaling 設定を構成できます。
A: Amazon SageMaker AI は、非同期エンドポイントの自動スケーリング (自動スケーリング) をサポートしています。自動スケーリングは、ワークロードの変動に応じて、モデルにプロビジョニングされたインスタンスの数を動的に調整します。SageMaker AI がサポートする他のホストモデルとは異なり、非同期推論を使用すると、非同期エンドポイントインスタンスをゼロにスケールダウンすることもできます。インスタンスがゼロの場合に受信されるリクエストは、エンドポイントがスケールアップされると処理のためにキューに入れられます。詳細については、「Autoscale an asynchronous endpoint」を参照してください。
Amazon SageMaker サーバーレス推論も自動的にゼロまでスケールダウンします。SageMaker AI がサーバーレスエンドポイントのスケーリングを管理するため、これは表示されませんが、トラフィックが発生していない場合は、同じインフラストラクチャが適用されます。
