ModelBuilder を使用して Amazon SageMaker でモデルを作成します
SageMaker エンドポイントでのデプロイ用にモデルを準備するには、モデルイメージの選択、エンドポイント設定のセットアップ、サーバーとクライアントとの間でデータを転送するためのシリアル化およびシリアル化解除関数のコーディング、モデルの依存関係の特定、Amazon S3 へのアップロードなど、複数のステップが必要です。ModelBuilder を使用すると、初期セットアップとデプロイの複雑さを軽減し、デプロイ可能なモデルを 1 つのステップで作成できるようになります。
ModelBuilder は以下のタスクを実行します。
XGBoost や PyTorch などのさまざまなフレームワークを使用してトレーニングされた機械学習モデルを、1 つのステップでデプロイ可能なモデルに変換します。
モデルフレームワークに基づいて自動コンテナ選択を実行します。コンテナを手動で指定する必要はありません。独自の URI を
ModelBuilderに渡すことで、独自のコンテナを持ち込むことができます。データを推論のためにサーバーに送信する前にクライアント側でのシリアル化の処理、およびサーバーから返された結果の逆シリアル化の処理。データは、手動処理なしで正しくフォーマットされます。
依存関係の自動キャプチャを可能にし、モデルサーバーの想定に従ってモデルをパッケージ化します。
ModelBuilderの依存関係の自動キャプチャは、依存関係を動的にロードするためのベストエフォートアプローチです。(自動キャプチャをローカルでテストし、ニーズに合わせて依存関係を更新することをお勧めします)。大規模言語モデル (LLM) のユースケースでは、オプションで、SageMaker エンドポイントでホストするときにパフォーマンスを向上させるためにデプロイできる、サービングプロパティのローカルパラメータチューニングを実行します。
TorchServe、Triton、DJLServing、TGI コンテナなど、一般的なモデルサーバーとコンテナのほとんどをサポートします。
ModelBuilder を使用してモデルを構築する
ModelBuilder は、XGBoost や PyTorch などのフレームワークモデル、またはユーザーが指定した推論仕様を取得し、デプロイ可能なモデルに変換する Python クラスです。ModelBuilder は、デプロイ用のアーティファクトを生成するビルド関数を提供します。生成されたモデルアーティファクトはモデルサーバーに固有であり、入力の 1 つとして指定することもできます。ModelBuilder クラスの詳細については、「ModelBuilder
次の図は、ModelBuilder を使用する際のモデル作成ワークフロー全体を示しています。ModelBuilder は、デプロイ前にローカルでテストできるデプロイ可能なモデルを作成するために、スキーマとともにモデルまたは推論仕様を受け入れます。
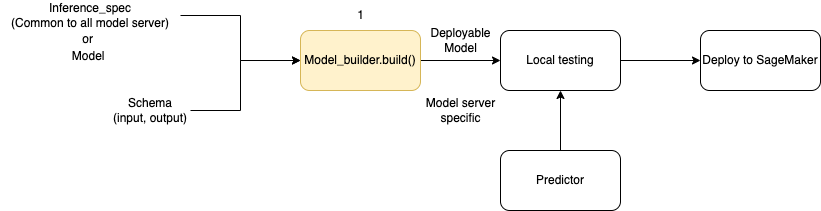
ModelBuilder は、適用するカスタマイズを処理できます。ただし、フレームワークモデルをデプロイするために、モデルビルダーは、少なくとも 1 つのモデル、サンプル入出力、ロールを想定しています。次のコード例では、ModelBuilder はフレームワークモデルと最小引数を持つ インスタンス SchemaBuilder で呼び出されます (エンドポイントの入出力をシリアル化および逆シリアル化するための対応する関数を推測するため)。コンテナは指定されておらず、パッケージ化された依存関係も渡されません。SageMaker はモデルを構築するときにこれらのリソースを自動的に推測します。
from sagemaker.serve.builder.model_builder import ModelBuilder from sagemaker.serve.builder.schema_builder import SchemaBuilder model_builder = ModelBuilder( model=model, schema_builder=SchemaBuilder(input, output), role_arn="execution-role", )
次のコードサンプルは、モデルではなく推論仕様 (InferenceSpecインスタンスとして)を持つ ModelBuilder を呼び出し、さらにカスタマイズします。この場合、モデルビルダーへの呼び出しには、モデルアーティファクトを保存するパスが含まれ、使用可能なすべての依存関係の自動キャプチャも有効になります。InferenceSpec の詳細については、「モデルのロードとリクエストの処理をカスタマイズする」を参照してください。
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": True} )
シリアル化と逆シリアル化の方法を定義する
SageMaker エンドポイントを呼び出すと、データは異なる MIME タイプの HTTP ペイロードを介して送信されます。例えば、推論のためにエンドポイントに送信されるイメージは、クライアント側でバイトに変換し、HTTP ペイロードを介してエンドポイントに送信する必要があります。エンドポイントがペイロードを受信すると、バイト文字列をモデルが想定するデータタイプに逆シリアル化する必要があります (サーバー側の逆シリアル化とも呼ばれます)。モデルが予測を完了したら、結果も、HTTP ペイロードを介してユーザーまたはクライアントに返送できるバイトにシリアル化する必要があります。クライアントがレスポンスのバイトデータを受信すると、クライアント側で逆シリアル化を実行して、バイトデータを JSON などの想定されるデータ形式に変換する必要があります。少なくとも、以下のデータを変換する必要があります。
推論リクエストのシリアル化 (クライアントによる処理)
推論リクエストの逆シリアル化 (サーバーまたはアルゴリズムによる処理)
ペイロードに対してモデルを呼び出し、レスポンスペイロードを送り返す
推論レスポンスのシリアル化 (サーバーまたはアルゴリズムによる処理)
推論レスポンスの逆シリアル化 (クライアントによる処理)
次の図は、エンドポイントを呼び出すときに発生するシリアル化と逆シリアル化のプロセスを示しています。
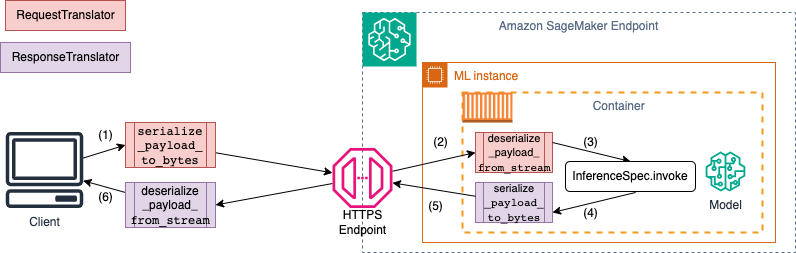
SchemaBuilder にサンプル入出力を指定すると、スキーマビルダーは、入出力をシリアル化および逆シリアル化するための、対応するマーシャリング関数を生成します。CustomPayloadTranslator で、シリアル化関数をさらにカスタマイズできます。ただし、ほとんどの場合、次のようなシンプルなシリアライザーで十分です。
input = "How is the demo going?" output = "Comment la démo va-t-elle?" schema = SchemaBuilder(input, output)
SchemaBuilder の詳細については、「SchemaBuilder
次のコードスニペットは、クライアント側とサーバー側でシリアル化関数と逆シリアル化関数の両方をカスタマイズする例の概要を示しています。CustomPayloadTranslator を使用して独自のリクエストとレスポンスのトランスレーターを定義し、これらのトランスレーターを SchemaBuilder に渡すことができます。
入力と出力をトランスレーターに含めることで、モデルビルダーはモデルが想定するデータ形式を抽出できます。例えば、サンプル入力が未加工画像であり、カスタムトランスレーターが画像をクロップして、クロップした画像をテンソルとしてサーバーに送信するとします。ModelBuilder は、クライアント側とサーバー側の両方でデータを変換する方法を導き出すために、未加工入力とカスタム前処理または後処理コードの両方を必要とします。
from sagemaker.serve import CustomPayloadTranslator # request translator class MyRequestTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on client side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the input payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on server side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object # response translator class MyResponseTranslator(CustomPayloadTranslator): # This function converts the payload to bytes - happens on server side def serialize_payload_to_bytes(self, payload: object) -> bytes: # converts the response payload to bytes ... ... return //return object as bytes # This function converts the bytes to payload - happens on client side def deserialize_payload_from_stream(self, stream) -> object: # convert bytes to in-memory object ... ... return //return in-memory object
次の例に示すように、SchemaBuilder オブジェクトを作成するときに、事前に定義されたカスタムトランスレーターとともにサンプル入出力を渡します。
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
次に、サンプル入出力を、前に定義したカスタムトランスレーターとともに SchemaBuilder オブジェクトに渡します。
my_schema = SchemaBuilder( sample_input=image, sample_output=output, input_translator=MyRequestTranslator(), output_translator=MyResponseTranslator() )
以下のセクションでは、ModelBuilder を使用してモデルを構築し、そのサポートクラスを使用してユースケースのエクスペリエンスをカスタマイズする方法について詳しく説明します。
モデルのロードとリクエストの処理をカスタマイズする
InferenceSpec を通じて独自の推論コードを指定すると、カスタマイズのレイヤーが追加されます。InferenceSpec を使用すると、モデルのロード方法と受信推論リクエストの処理方法をカスタマイズでき、デフォルトのロードと推論処理メカニズムをバイパスできます。この柔軟性は、非標準モデルまたはカスタム推論パイプラインを操作する場合に特に役立ちます。invoke メソッドをカスタマイズして、モデルが受信リクエストを前処理および後処理する方法を制御できます。invoke メソッドを使用すると、モデルが確実に推論リクエストを正しく処理できます。次の例では、InferenceSpec を使用して HuggingFace パイプラインでモデルを生成します。InferenceSpec の詳細については、「InferenceSpec
from sagemaker.serve.spec.inference_spec import InferenceSpec from transformers import pipeline class MyInferenceSpec(InferenceSpec): def load(self, model_dir: str): return pipeline("translation_en_to_fr", model="t5-small") def invoke(self, input, model): return model(input) inf_spec = MyInferenceSpec() model_builder = ModelBuilder( inference_spec=your-inference-spec, schema_builder=SchemaBuilder(X_test, y_pred) )
次の例は、前述の例の、よりカスタマイズされたバリエーションを示しています。モデルは、依存関係を持つ推論仕様で定義されます。この場合、推論仕様のコードは、lang-segment パッケージによって異なります。dependencies の引数には、Git を使用して lang-segment をインストールするようにビルダーに指示するステートメントが含まれています。モデルビルダーはユーザーから依存関係をカスタムインストールするように指示されるため、auto キーは依存関係の自動キャプチャをオフにする False です。
model_builder = ModelBuilder( mode=Mode.LOCAL_CONTAINER, model_path=model-artifact-directory, inference_spec=your-inference-spec, schema_builder=SchemaBuilder(input, output), role_arn=execution-role, dependencies={"auto": False, "custom": ["-e git+https://github.com/luca-medeiros/lang-segment-anything.git#egg=lang-sam"],} )
モデルの構築とデプロイ
build 関数を呼び出して、デプロイ可能なモデルを作成します。このステップでは、スキーマの作成、入出力のシリアル化と逆シリアル化の実行、その他のユーザー指定のカスタムロジックの実行に必要なコードを含む推論コード (inference.py として) を、作業ディレクトリに作成します。
整合性チェックとして、SageMaker は ModelBuilder ビルド関数の一部としてデプロイに必要なファイルをパッケージ化して pickle 化します。このプロセス中、SageMaker は pickle ファイルの HMAC 署名も作成し、deploy (または create) 中に、シークレットキーを環境変数として CreateModel API に追加します。エンドポイントの起動では、環境変数を使用して、pickle ファイルの整合性を検証します。
# Build the model according to the model server specification and save it as files in the working directory model = model_builder.build()
モデルの既存の deploy メソッドを使用して、モデルをデプロイします。このステップでは、SageMaker は、受信リクエストに応じて予測の作成を開始するときにモデルをホストするように、エンドポイントを設定します。ModelBuilder はモデルのデプロイに必要なエンドポイントリソースを推測しますが、これらの見積りは独自のパラメータ値で上書きできます。次の例では、1 つの ml.c6i.xlarge インスタンスにモデルをデプロイするように SageMaker に指示します。ModelBuilder で構築されたモデルでは、デプロイ中に追加機能としてライブログ記録が可能になります。
predictor = model.deploy( initial_instance_count=1, instance_type="ml.c6i.xlarge" )
モデルに割り当てられたエンドポイントリソースをより細かく制御したい場合は、ResourceRequirements オブジェクトを使用できます。ResourceRequirements オブジェクトを使用すると、デプロイするモデルの CPU、アクセラレーター、コピーの最小数をリクエストできます。メモリの最小および最大バウンド (MB) をリクエストすることもできます。この機能を使用するには、エンドポイントタイプを EndpointType.INFERENCE_COMPONENT_BASED として指定する必要があります。次の例では、4 つのアクセラレーター、最小メモリサイズ 1,024 MB、モデルのコピー 1 つをタイプ EndpointType.INFERENCE_COMPONENT_BASED のエンドポイントにデプロイすることをリクエストします。
resource_requirements = ResourceRequirements( requests={ "num_accelerators": 4, "memory": 1024, "copies": 1, }, limits={}, ) predictor = model.deploy( mode=Mode.SAGEMAKER_ENDPOINT, endpoint_type=EndpointType.INFERENCE_COMPONENT_BASED, resources=resource_requirements, role="role" )
独自のコンテナ
独自のコンテナ (SageMaker コンテナから拡張) を持ち込む場合は、次の例に示すように、イメージ URI を指定することもできます。また、モデルサーバーに固有のアーティファクトを生成するには、ModelBuilder のイメージに対応するモデルサーバーを特定する必要があります。
model_builder = ModelBuilder( model=model, model_server=ModelServer.TORCHSERVE, schema_builder=SchemaBuilder(X_test, y_pred), image_uri="123123123123.dkr.ecr.ap-southeast-2.amazonaws.com/byoc-image:xgb-1.7-1") )
ローカルモードで ModelBuilder を使用する
mode 引数を使用してローカルテストとエンドポイントへのデプロイを切り替えることで、モデルをローカルにデプロイできます。次のスニペットに示すように、モデルアーティファクトを作業ディレクトリに保存する必要があります。
model = XGBClassifier() model.fit(X_train, y_train) model.save_model(model_dir + "/my_model.xgb")
モデルオブジェクトである SchemaBuilder インスタンスを渡し、モードを Mode.LOCAL_CONTAINER に設定します。build 関数を呼び出すと、ModelBuilder はサポートされているフレームワークコンテナを自動的に識別し、依存関係をスキャンします。次の例は、ローカルモードで XGBoost モデルを使用したモデルの作成を示しています。
model_builder_local = ModelBuilder( model=model, schema_builder=SchemaBuilder(X_test, y_pred), role_arn=execution-role, mode=Mode.LOCAL_CONTAINER ) xgb_local_builder = model_builder_local.build()
次のスニペットに示すように、deploy 関数を呼び出してローカルにデプロイします。インスタンスタイプまたはカウントにパラメータを指定すると、これらの引数は無視されます。
predictor_local = xgb_local_builder.deploy()
ローカルモードのトラブルシューティング
個々のローカル設定によっては、環境でスムーズに ModelBuilder を実行できない場合があります。直面する可能性のある問題とその解決方法については、次のリストを参照してください。
既に使用されています:
Address already in useエラーが発生する可能性があります。この場合、Docker コンテナがそのポートで実行されているか、別のプロセスで使用されている可能性があります。Linux ドキュメントで説明されているアプローチに従ってプロセスを特定し、ローカルプロセスをポート 8080 から別のポートに適切にリダイレクトするか、Docker インスタンスをクリーンアップします。 IAM アクセス許可の問題: Amazon ECR イメージをプルしたり、Amazon S3 にアクセスしようとした際に、アクセス許可の問題が発生する可能性があります。この場合、ノートブックまたは Studio Classic インスタンスの実行ロールに移動して、
SageMakerFullAccessのポリシー、またはそれぞれの API アクセス許可を検証します。EBS ボリューム容量の問題: 大規模言語モデル (LLM) をデプロイする場合、ローカルモードで Docker を実行している間にスペースが不足したり、Docker キャッシュのスペース制限が発生したりする可能性があります。この場合、Docker ボリュームを、十分なスペースがあるファイルシステムに移動します。Docker ボリュームを移動するには、次の手順を実行します。
次の出力に示すように、ターミナルを開き、
dfを実行してディスク使用量を表示します。(python3) sh-4.2$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 195928700 0 195928700 0% /dev tmpfs 195939296 0 195939296 0% /dev/shm tmpfs 195939296 1048 195938248 1% /run tmpfs 195939296 0 195939296 0% /sys/fs/cgroup /dev/nvme0n1p1 141545452 135242112 6303340 96% / tmpfs 39187860 0 39187860 0% /run/user/0 /dev/nvme2n1 264055236 76594068 176644712 31% /home/ec2-user/SageMaker tmpfs 39187860 0 39187860 0% /run/user/1002 tmpfs 39187860 0 39187860 0% /run/user/1001 tmpfs 39187860 0 39187860 0% /run/user/1000256 GB の SageMaker ボリュームを最大限に活用できるように、デフォルトの Docker ディレクトリを
/dev/nvme0n1p1から/dev/nvme2n1に移動します。詳細については、Docker ディレクトリを移動する方法に関するドキュメントを参照してください。 次のコマンドを使用して Docker を停止します。
sudo service docker stopdaemon.jsonを/etc/dockerに追加するか、次の JSON ブロブを既存のものに追加します。{ "data-root": "/home/ec2-user/SageMaker/{created_docker_folder}" }次のコマンドを使用して、
/var/lib/dockerの Docker ディレクトリを/home/ec2-user/SageMakerに移動します。sudo rsync -aP /var/lib/docker/ /home/ec2-user/SageMaker/{created_docker_folder}次のコマンドを使用して Docker を開始します。
sudo service docker start次のコマンドを使用してごみ箱をクリーンアップします。
cd /home/ec2-user/SageMaker/.Trash-1000/files/* sudo rm -r *SageMaker ノートブックインスタンスを使用している場合は、Docker 準備ファイル
の手順に従って、Docker をローカルモード用に準備できます。
ModelBuilder の例
ModelBuilder を使用してモデルを構築するその他の例については、「ModelBuilder sample notebooks
