翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
レコメンデーション結果
各 Inference Recommender ジョブの結果には InstanceType、InitialInstanceCount、EnvironmentParameters が含まれます。これらは、コンテナのレイテンシーとスループットを改善するためにコンテナに合わせて調整された環境変数パラメータです。結果には、MaxInvocations、ModelLatency、CostPerHour、CostPerInference、CpuUtilization、MemoryUtilization などのパフォーマンスとコストのメトリクスも含まれます。
以下の表では、これらのメトリクスについて説明します。これらのメトリクスは、ユースケースに最適なエンドポイント構成の検索対象を絞り込むのに役立ちます。たとえば、スループットを重視した全体的な価格性能が動機である場合は、CostPerInference に注目する必要があります。
| メトリクス | 説明 | ユースケース |
|---|---|---|
|
|
SageMaker AI から見たときにモデルが応答するのにかかる時間間隔。この間隔には、リクエストを送信し、モデルのコンテナからレスポンスを取得するのにかかるローカル通信時間と、コンテナ内で推論を完了するのにかかる時間が含まれます。 単位: ミリ秒 |
広告配信や医療診断など、レイテンシーの影響を受けやすいワークロード |
|
|
モデルエンドポイントに 1 分間に送信される最大 単位: なし |
ビデオ処理やバッチ推論など、スループットを重視するワークロード |
|
|
リアルタイムエンドポイントの 1 時間あたりの推定コスト。 単位: 米ドル |
レイテンシーの期限のないコストの影響を受けやすいワークロード |
|
|
リアルタイムエンドポイントの推論呼び出しあたりの推定コスト。 単位: 米ドル |
スループットを重視して、全体的なコストパフォーマンスを最大化する |
|
|
エンドポイントインスタンスの 1 分あたりの最大呼び出し数で予想されるCPU使用率。 単位: パーセント |
インスタンスのコアCPU使用率を可視化することで、ベンチマーク中のインスタンスの状態を把握する |
|
|
エンドポイントインスタンスの 1 分あたりの最大呼び出し数における予想メモリ使用率。 単位: パーセント |
インスタンスのコアメモリ使用率を可視化することで、ベンチマーク中のインスタンスの状態を把握できます。 |
場合によっては、 などの他の SageMaker AI エンドポイント呼び出しメトリクスを調べることができますCPUUtilization。すべての Inference Recommender ジョブの結果には、ロードテスト中にスピンアップされたエンドポイントの名前が含まれます。 CloudWatch を使用して、これらのエンドポイントが削除された後でもログを確認できます。
次の図は、レコメンデーション結果から 1 つのエンドポイントについて確認できる CloudWatch メトリクスとグラフの例です。この推奨結果はデフォルトジョブのものです。推奨結果のスカラー値を解釈する基準は、呼び出しグラフが最初に横ばいになり始めた時点です。たとえば、報告された ModelLatency 値は、03:00:31 あたりに横ばいになり始めています。
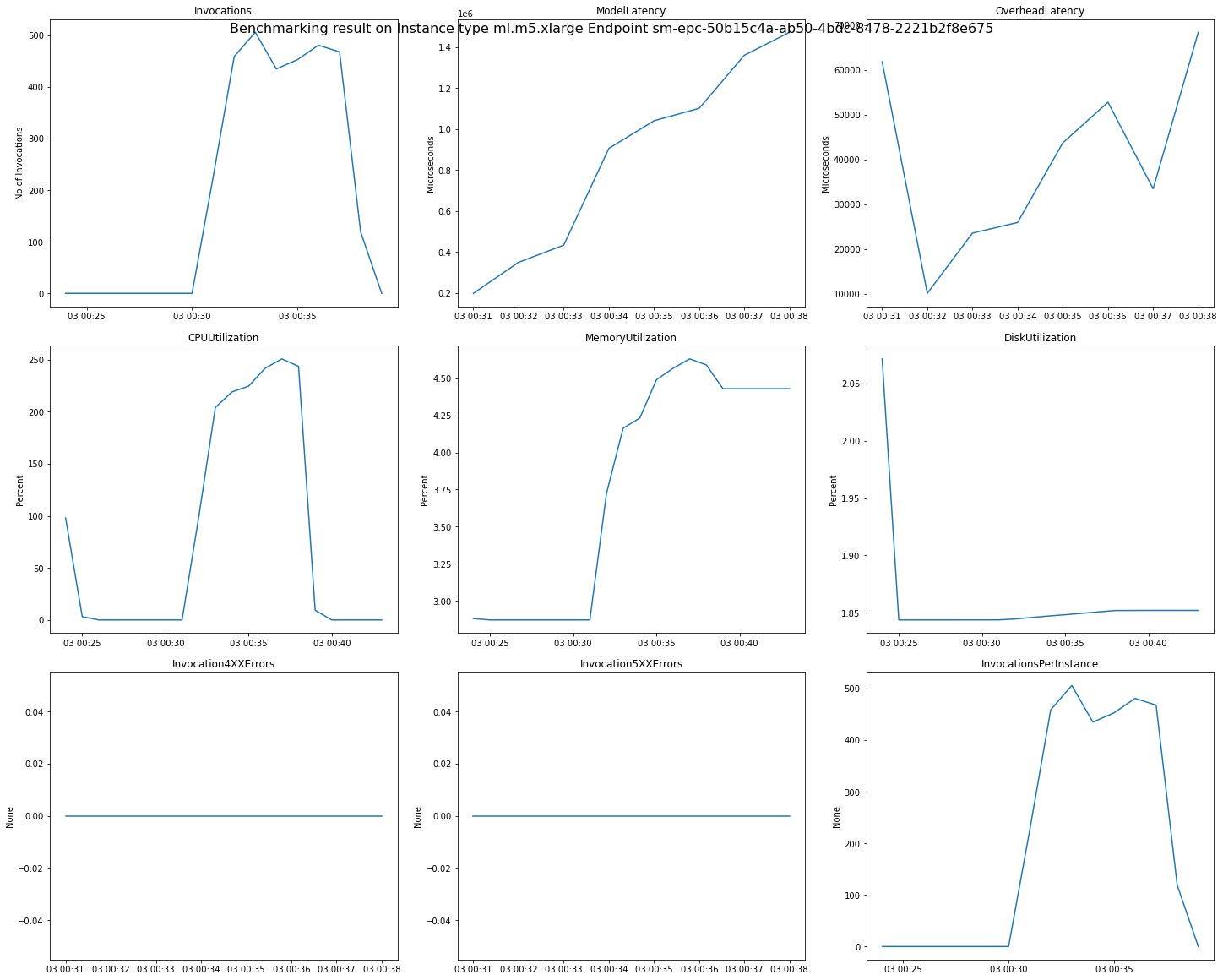
上記のグラフで使用される CloudWatch メトリクスの詳細については、SageMaker 「AI エンドポイント呼び出しメトリクス」を参照してください。
/aws/sagemaker/InferenceRecommendationsJobs 名前空間には Inference Recommender によって発行された ClientInvocations や NumberOfUsers のようなパフォーマンスメトリクスも表示されます。Inference Recommender によって発行されたメトリクスと説明の完全なリストについては、「SageMaker Inference Recommender ジョブのメトリクス」を参照してください。
for Python (Boto3) を使用して AWS SDKエンドポイントの CloudWatch メトリクスを調べる方法の例については、amazon-sagemaker-examples
