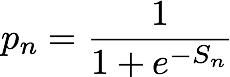翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
IP Insights の仕組み
Amazon SageMaker AI IP Insights は、エンティティを IP アドレスに関連付ける (エンティティ、IPv4アドレス) ペアの形式で観測データを使用する教師なしアルゴリズムです。IP Insights は、エンティティと IP アドレスの両方の潜在的なベクトル表現を学習することによって、エンティティが特定の IP アドレスを使用する可能性がどれほど高いのかを判別します。これら 2 つの表現の間の距離は、この関連付けにどの程度の可能性があるかを示すプロキシとして機能します。
IP Insights アルゴリズムは、ニューラルネットワークを使用して、エンティティと IP アドレスの潜在的なベクトル表現を学習します。エンティティはまず、大規模な固定ハッシュ空間にハッシュされ、次に単純な埋め込みレイヤーによってエンコードされます。ユーザー名やアカウントなどの文字列は、ログファイルに表示される IP Insights に直接入力IDsできます。エンティティ識別子のデータを前処理する必要はありません。トレーニング中にも推論中にもエンティティを任意の文字列値として提供できます。ハッシュサイズは、異なるエンティティが同じ潜在ベクトルにマッピングされたときに発生する衝突の数が重要でないことを保証できるだけの十分高い値に設定する必要があります。適切なハッシュサイズを選択する方法の詳細については、Feature Hashing for Large Scale Multitask Learning (大規模マルチタスク学習の特徴ハッシュ)
IP Insights はトレーニング中、エンティティと IP アドレスをランダムにペアにして、負のサンプルを自動的に生成します。これらの負のサンプルは、実際には発生する可能性の低いデータを表します。モデルは、トレーニングデータで観察された正のサンプルと、生成された負のサンプルとを区別するようにトレーニングされます。具体的には、モデルは次のように定義される交差エントロピー (ログの損失とも呼ばれる) を最小限に抑えるようにトレーニングされます。
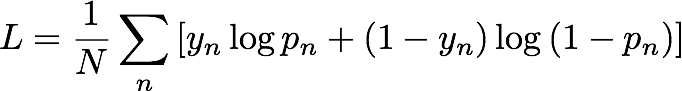
yn は、サンプルが観測データを管理する実分布から取得されたものか (yn=1)、負のサンプルを生成する分布から取得されたものか (yn=0) を示すラベルです。pn は、サンプルが実分布から取得したものである確率であり、モデルによって予測されます。
負のサンプルの生成は、観測データの正確なモデルを実現するために使用される重要なプロセスです。たとえば、負のサンプルの IP アドレスがすべて 10.0.0.0 である場合など、負のサンプルの可能性が非常に低い場合、モデルは負のサンプルの区別を自明な方法で学習し、実際の観測データセットを正確に特徴付けることができません。負のサンプルの現実性を高く保つために、IP Insights は IP アドレスをランダムに生成し、トレーニングデータから IP アドレスをランダムに選択することによって、負のサンプルを生成します。負のサンプリングのタイプと負のサンプルを生成するレートを設定するには、random_negative_sampling_rate および shuffled_negative_sampling_rate ハイパーパラメータを使用します。
n 番目の (エンティティ、IP アドレスのペア) が提供されると、IP Insights モデルは、エンティティと IP アドレスとの互換性を示すスコア Sn を出力します。このスコアは、実際の分布から取得したペア (エンティティ, IP アドレス) を、負の分布から取得したペアと比較することで得られる、対数オッズ比に対応します。これは次のように定義されます。
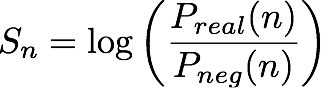
スコアは基本的に、n 番目のエンティティと IP アドレスのベクトル表現間の類似性の尺度です。これは、ランダムに生成されたデータセットのイベントより現実のイベントを観察する方がどれほど可能性が高いかを示していると解釈することができます。トレーニング中に、アルゴリズムはこのスコアを使用して、実分布 pn から取得したサンプルである確率の推定値を計算し、交差エントロピー最小化で使用します。