翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
入力モードとストレージユニットの選択
トレーニングジョブに最適なデータソースは、データセットのサイズ、ファイル形式、ファイルの平均サイズ、トレーニング時間、データローダーのシーケンシャルまたはランダムの読み取りパターン、モデルがトレーニングデータを使用する速度などのワークロードの特性によって異なります。以下のベストプラクティスは、ユースケースに最適な入力モードとデータストレージサービスを開始するためのガイドラインを提供します。
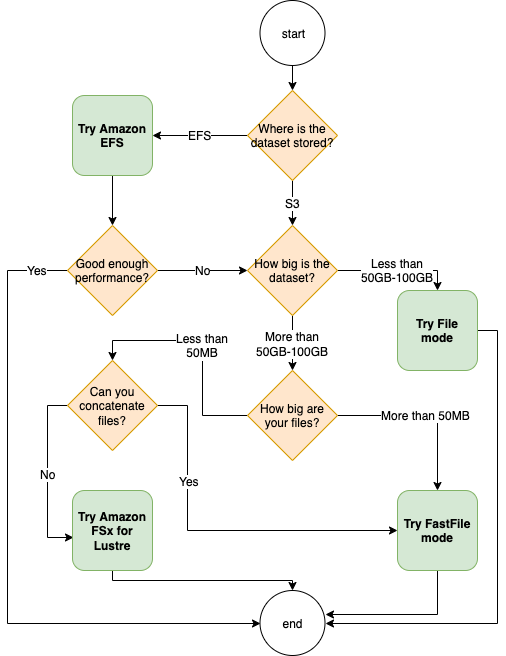
Amazon を使用するタイミング EFS
データセットが Amazon Elastic File System に保存されている場合、ストレージEFSに Amazon を使用する前処理または注釈アプリケーションがある場合があります。Amazon EFS ファイルシステムを指すデータチャネルで設定されたトレーニングジョブを実行できます。詳細については、「Amazon FSx for Lustre と Amazon EFS ファイルシステム SageMaker を使用した Amazon でのトレーニングの高速化
小規模なデータセットにはファイルモードを使用してください。
データセットが Amazon Simple Storage Service に保存されていて、全体の容量が比較的小さい場合 (例えば、50~100 GB 未満) は、ファイルモードを使用してみてください。50 GB のデータセットをダウンロードする場合のオーバーヘッドは、ファイルの総数によって異なる場合があります。例えば、データセットが 100 MB のシャードに分割されている場合、約 5 分かかります。この起動時のオーバーヘッドが許容できるかどうかは、主にトレーニングジョブの全体的な所要時間によって異なります。トレーニングフェーズが長くなると、ダウンロードフェーズもそれに比例して小さくなるからです。
多数の小さなファイルをシリアル化する
データセットのサイズが小さい (50~100 GB 未満) が、多数の小さなファイル (1 ファイルあたり 50 MB 未満) で構成されている場合、ファイルモードのダウンロードオーバーヘッドが増加します。これは、各ファイルを Amazon Simple Storage Service からトレーニングインスタンスボリュームに個別にダウンロードする必要があるためです。このオーバーヘッドとデータトラバーサルの所要時間を全体的に短縮するには、 TFRecord
高速ファイルモードを使用するタイミング
ファイルが大きい大規模なデータセット (ファイルあたり 50 MB 以上) の場合、最初のオプションは高速ファイルモードを試すことです。高速ファイルモードは、ファイルシステムの作成や への接続が不要であるため、FSxLustre よりも簡単に使用できますVPC。高速ファイルモードは、サイズの大きいファイルコンテナ (150 MB 以上) に最適で、50 MB を超えるファイルにも適している場合があります。高速ファイルモードではPOSIXインターフェイスが提供されるため、ランダム読み取り (非連続バイト範囲の読み取り) がサポートされます。ただし、これは理想的な使用例ではなく、スループットはシーケンシャル読み取りよりも低下する可能性があります。ただし、比較的大規模で計算量の多い ML モデルを使用している場合は、高速ファイルモードでもトレーニングパイプラインの実効帯域幅を飽和させることができ、IO ボトルネックにならない可能性があります。実験して確認する必要があります。ファイルモードから高速ファイルモード (および戻る) に切り替えるには、 SageMaker Python を使用して入力チャネルを定義しながら input_mode='FastFile'パラメータを追加 (または削除) しますSDK。
sagemaker.inputs.TrainingInput(S3_INPUT_FOLDER, input_mode = 'FastFile')
Amazon FSx for Lustre を使用するタイミング
データセットがファイルモードに大きすぎる場合、 には簡単にシリアル化できない小さなファイルが多数あるか、ランダムな読み取りアクセスパターンが使用されているため、FSxLustre は考慮すべきオプションです。そのファイルシステムは、数百ギガバイト/秒 (GB/秒) のスループットと数百万の にスケールされます。これはIOPS、多くの小さなファイルがある場合に最適です。ただし、ロードが緩やかで、FSxLustre ファイルシステムの をセットアップして初期化するオーバーヘッドが原因で、コールドスタートの問題が発生する可能性があることに注意してください。
ヒント
詳細については、「Amazon SageMaker トレーニングジョブに最適なデータソースを選択する
