翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
データセットにアクセスするようにトレーニングジョブを設定する
トレーニングジョブを作成するとき、ユーザーは、選択したデータストレージ内のトレーニングデータセットの場所と、そのジョブのデータ入力モードを指定します。Amazon SageMaker AI は、Amazon Simple Storage Service (Amazon S3)、Amazon Elastic File System (Amazon EFS)、Amazon FSx for Lustre をサポートしています。入力モードのいずれかを選択してデータセットをリアルタイムでストリーミングするか、トレーニングジョブの開始時にデータセット全体をダウンロードできます。
注記
データセットは、トレーニングジョブ AWS リージョン と同じ に存在する必要があります。
SageMaker AI 入力モードと AWS クラウドストレージオプション
このセクションでは、Amazon EFS および Amazon FSx for Lustre に保存されているデータについて、SageMaker がサポートするファイル入力モードの概要を説明します。
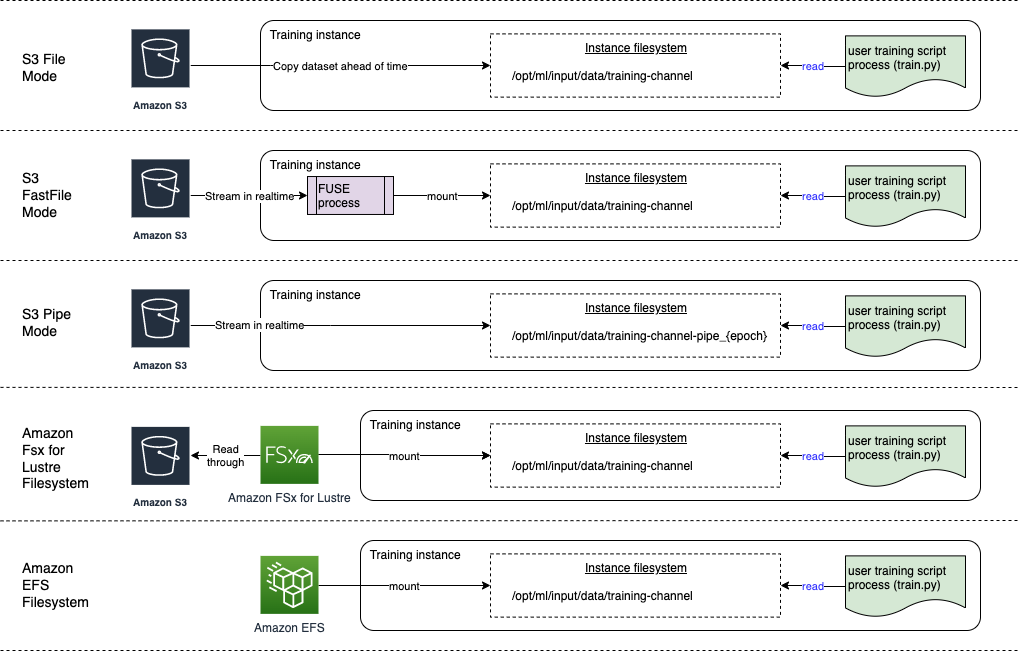
-
File モードでは、トレーニングコンテナへのデータセットをファイルシステムビューで表示します。他の 2 つのオプションのいずれかを明示的に指定しない場合、これがデフォルトの入力モードになります。ファイルモードを使用する場合、SageMaker AI はトレーニングデータをストレージの場所から Docker コンテナのローカルディレクトリにダウンロードします。トレーニングは、データセットのすべてがダウンロードされた後に開始されます。ファイルモードでは、トレーニングインスタンスにはデータセット全体を収めるのに十分なストレージ容量が必要です。ファイルモードのダウンロード速度は、データセットのサイズ、ファイルの平均サイズ、およびファイル数によって異なります。Amazon S3 プレフィックス、マニフェストファイル、または拡張マニフェストファイルのいずれかを指定することで、データセットをファイルモードに設定できます。すべてのデータセットファイルが共通の S3 プレフィックス内にある場合は、S3 プレフィックスを使用する必要があります。ファイルモードは SageMaker AI ローカルモード
(SageMaker トレーニングコンテナをインタラクティブに数秒で起動) と互換性があります。分散型トレーニングでは、 ShardedByS3Keyオプションを使用してデータセットを複数のインスタンスに分散できます。 -
高速ファイルモードでは、パイプモードのパフォーマンスにおける利点を生かしながら Amazon S3 データソースにファイルシステムとしてアクセスできます。高速ファイルモードでは、トレーニングの開始時にデータファイルを識別しますが、ダウンロードはしません。トレーニングは、データセットのすべてがダウンロードされるのを待たずに開始できます。つまり、指定した Amazon S3 プレフィックスに含まれるファイルの数が少ないほど、トレーニングの開始にかかる時間が短くなります。
パイプモードとは異なり、高速ファイルモードではデータにランダムにアクセスできます。ただし、データを順番に読み取る場合が最も効果的です。高速ファイルモードは拡張マニフェストファイルをサポートしていません。
高速ファイルモードでは、あたかもトレーニングインスタンスのローカルディスクにファイルがあるかのように、POSIX 準拠のファイルシステムインターフェイスを使用して S3 オブジェクトを公開します。トレーニングスクリプトがデータを消費すると、S3 コンテンツをオンデマンドでストリーミングします。つまり、データセット全体がトレーニングインスタンスのストレージスペースに収まる必要がなくなり、トレーニングを開始する前にデータセットがトレーニングインスタンスにダウンロードされるのを待つ必要がなくなります。高速ファイルは現在 S3 プレフィックスのみをサポートしています (マニフェストと拡張マニフェストはサポートしていません)。高速ファイルモードは SageMaker AI ローカルモードと互換性があります。
注記
高速ファイルモードを使用すると、次のログ記録が追加されるため、CloudTrail のコストが増加する可能性があります。
-
Amazon S3 データイベント (CloudTrail で有効化されている場合)。
-
AWS KMS キーで AWS KMS 暗号化された Amazon S3 オブジェクトにアクセスするときの復号イベント。
-
AWS KMS オペレーションに関連する管理イベント。
これらのイベントタイプで CloudTrail ログ記録が有効になっている場合は、CloudTrail の設定とモニタリングのコストを確認してください。
-
-
Pipe モードでは、データは Amazon S3 データソースから直接ストリーミングされます。ストリーミングにより、ファイルモードよりトレーニングジョブの開始時間が短縮され、スループットが向上します。
データを直接ストリーミングすると、トレーニングインスタンスで使用される Amazon EBS ボリュームのサイズを縮小できます。パイプモードでは、最終的なモデルアーティファクトを保存するのに十分なディスク容量が必要です。
これはもう 1 つのストリーミングモードですが、主に新しくて使いやすい高速ファイルモードに置き換えられています。パイプモードでは、データは Amazon S3 から高い同時実行性とスループットでプリフェッチされ、名前付きパイプにストリーミングされます。名前付きパイプは、その動作から先入れ先出し (FIFO) パイプとも呼ばれます。各パイプは 1 つのプロセスでのみ読み取ることができます。SageMaker AI 専用の TensorFlow 拡張機能を使用すると、テキスト、TFRecords、または RecordIO ファイル形式をストリーミングするためのネイティブの TensorFlow データローダーにパイプモードを簡単に統合できます
。パイプモードは、マネージドシャーディングとデータのシャッフルもサポートします。 -
Amazon S3 Express One Zone は、SageMaker モデルトレーニングなどの最もレイテンシーに敏感なアプリケーションに一貫した 1 桁ミリ秒のデータアクセスを提供できる高パフォーマンスの単一アベイラビリティーゾーン (AZ) ストレージクラスです。Amazon S3 Express One Zone を使用すると、お客様はオブジェクトストレージとコンピューティングリソースを 1 つの AWS アベイラビリティーゾーンに集約できるため、コンピューティングパフォーマンスとコストの両方を最適化してデータ処理速度を向上させることができます。アクセス速度をさらに向上させ、1 秒あたり数十万ものリクエストに対応するために、データは新しいバケットタイプ、つまり Amazon S3 ディレクトリバケットに保存されます。
SageMaker AI モデルトレーニングは、ファイルモード、高速ファイルモード、パイプモードのデータ入力場所として、高性能の Amazon S3 Express One Zone ディレクトリバケットに対応しています。Amazon S3 Express One Zone を使用するには、Amazon S3 バケットの代わりに、Amazon S3 Express One Zone ディレクトリバケットの場所を入力します。IAM ロールの ARN に、必要なアクセスコントロールとアクセス許可ポリシーを指定します。詳細については、「AmazonSageMakerFullAccesspolicy」を参照してください。SageMaker AI 出力データは、Amazon S3 マネージドキー (SSE-S3) を使用するサーバー側の暗号化でのみディレクトリバケットで暗号化できます。 AWS KMS キーによるサーバー側の暗号化 (SSE-KMS) は現在、SageMaker AI 出力データをディレクトリバケットに保存するためにサポートされていません。詳細については、「Amazon S3 Express One Zone」を参照してください。
-
Amazon FSx for Lustre – FSx for Lustre では、低レイテンシーのファイル取得により、数百ギガバイトのスループットと数百万の IOPS に拡張できます。トレーニングジョブを開始すると、SageMaker AI は FSx for Lustre ファイルシステムをトレーニングインスタンスファイルシステムにマウントし、トレーニングスクリプトを開始します。マウント自体は比較的高速な操作で、FSx for Lustre に保存されているデータセットのサイズには依存しません。
FSx for Lustre にアクセスするには、トレーニングジョブを Amazon Virtual Private Cloud (VPC) に接続する必要があります。これには DevOps の設定と関与が必要です。データ転送コストを回避するために、ファイルシステムは単一のアベイラビリティーゾーンを使用するため、トレーニングジョブの実行時にこのアベイラビリティーゾーン ID にマップする VPC サブネットを指定する必要があります。
-
Amazon EFS – Amazon EFS をデータソースとして使用するには、トレーニング前にデータが既に Amazon EFS に存在している必要があります。SageMaker AI は、指定した Amazon EFS ファイルシステムをトレーニングインスタンスにマウントし、トレーニングスクリプトを開始します。Amazon EFS にアクセスするには、トレーニングジョブを VPC に接続する必要があります。
ヒント
SageMaker AI 推定器に VPC 設定を指定する方法の詳細については、SageMaker AI Python SDK ドキュメントの「Use File Systems as Training Inputs
」を参照してください。
