翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
テンソル並列処理の仕組み
テンソル並列性は nn.Modules のレベルで行われるため、テンソル並列ランク間でモデル内の特定のモジュールをパーティション化します。これは、パイプラインの並列処理で使用されるモジュールのセットの既存のパーティションに加えて行われます。
テンソル並列処理によってモジュールをパーティション化すると、その前方伝播と後方伝播が分散されます。ライブラリは、これらのモジュールの分散実行を実装するために、デバイス間で必要な通信を処理します。モジュールは複数のデータ並列ランクにパーティション化されます。従来のワークロードの分散とは異なり、各データの並列ランクには、ライブラリのテンソル並列処理が使用されるとき、完全なモデルのレプリカが含まれません。代わりに、各データ並列ランクには、配布されていないモジュール全体に加えて、分散モジュールのパーティションのみが含まれる場合があります。
例: データ並列ランクにわたるテンソル並列処理について検討します。データ並列処理度は 4 で、テンソル並列度は 2 とします。モジュールのセットをパーティション化した後、次のモジュールツリーを保持するデータ並列グループがあるとします。
A ├── B | ├── E | ├── F ├── C └── D ├── G └── H
モジュール B、G、および H でテンソル並列処理がサポートされていると仮定します。このモデルのテンソル並列パーティションの結果として考えられる 1 つは、次のようになります。
dp_rank 0 (tensor parallel rank 0): A, B:0, C, D, G:0, H dp_rank 1 (tensor parallel rank 1): A, B:1, C, D, G:1, H dp_rank 2 (tensor parallel rank 0): A, B:0, C, D, G:0, H dp_rank 3 (tensor parallel rank 1): A, B:1, C, D, G:1, H
各行は、dp_rank に格納されているモジュールのセットを表し、表記 X:y はモジュール X の y 分の 1 を表します。次の点に注意してください:
-
パーティショニングは、
TP_GROUPと呼ばれるデータ並列ランクのサブセット間で行われ、DP_GROUP全体ではありません。つまり正確なモデルパーティションがdp_rank0 とdp_rank2、同様にdp_rank1 とdp_rank3 間で複製されます。 -
モジュール
EおよびFは、親モジュールのBがパーティション化されているため、モデルの一部ではなくなります。通常はEおよびFの一部である実行はすべて (パーティション化された)Bモジュール内で行われます。 -
Hはテンソル並列処理でサポートされていますが、この例ではパーティション化されていません。これは、モジュールをパーティション化するかどうかは、ユーザー入力に依存することを強調するためです。モジュールがテンソル並列処理でサポートされているからといって、必ずしもパーティション化されているわけではありません。
ライブラリがテンソル並列処理をモジュールに適応させる PyTorch nn.Linear方法
データ並列ランクに対してテンソル並列処理を実行すると、パラメータ、勾配、およびオプティマイザ状態のサブセットが、パーティション化されたモジュールのテンソル並列デバイス間でパーティション化されます。残りのモジュールでは、テンソル並列デバイスは通常のデータ並列方式で動作します。パーティション化されたモジュールを実行するために、デバイスはまず、同じテンソル並列処理グループのピアデバイス間ですべてのデータサンプルの必要な部分を収集します。次に、デバイスはこれらのすべてのデータサンプルでモジュールのローカルフラクションを実行し、その後に別の同期ラウンドを実行します。この同期は、各データサンプルの出力部分を組み合わせて、データサンプルが最初に生成された に組み合わせたGPUsデータサンプルを返します。次の図は、パーティション化された nn.Linear モジュールにおけるこのプロセスの例を示しています。
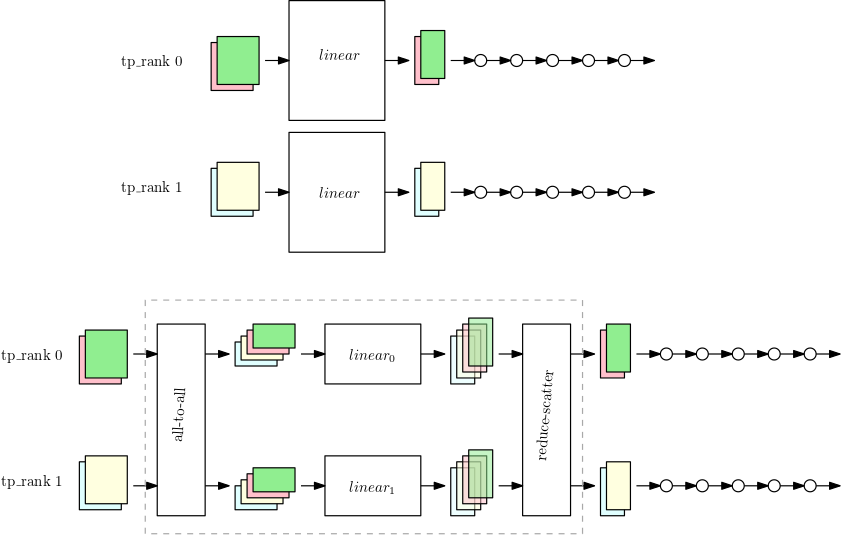
最初の図は、大きな nn.Linear モジュールのある小さなモデルで、2 つのテンソル並列処理ランクに対してデータ並列処理を行います。nn.Linear モジュールは 2 つの並列ランクにレプリケートされます。
2 番目の図は、より大きなモデルに適用されたテンソル並列処理を示しており、nn.Linear モジュールが分割されています。各 tp_rank はリニアモジュールの半分と、残りのオペレーション全体を保持します。リニアモジュールの実行中、各 tp_rank は、すべてのデータサンプルの関連する半分を収集し、それを nn.Linear モジュールの半分に渡します。各ランクが独自のデータサンプルの最終的な線形出力を持つように、結果をリダクション散乱 (総和を縮小オペレーションとして) する必要があります。残りのモデルは、一般的なデータ並列方式で実行されます。
