翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
RCF の仕組み
Amazon SageMaker AI Random Cut Forest (RCF) は、データセット内の異常なデータポイントを検出するための教師なしアルゴリズムです。これらは、その他の高度に構造化された、またはパターン化されたデータとは異なる観測値です。異常は、時系列データにおける突然のスパイク、周期性の中断、分類できないデータポイントとして現れる場合があります。プロットで見ると「通常の」データと容易に区別できることが多いため、簡単に説明できます。「通常の」データは多くの場合に単純なモデルで記述できるため、これらの異常をデータセットに含めると、機械学習タスクの複雑さが大幅に増加する可能性があります。
RCF アルゴリズムの主なアイデアは、ツリーのフォレストを作成することです。各ツリーは、トレーニングデータのサンプルのパーティションを使用して取得されます。たとえば、入力データのランダムなサンプルが最初に決定されます。ランダムなサンプルは、フォレスト内のツリーの数に応じて分割されます。各ツリーにこのようなパーティションが与えられ、そのポイントのサブセットが k-d ツリーに編成されます。ツリーによってデータポイントに割り当てられた異常スコアは、想定されたツリーの複雑性の変化、そのポイントのツリーへの追加の結果として定義されます。これは、ツリー内の生成されるポイントの深さにおおよそ反比例します。Random Cut Forest は、各構成ツリーからの平均スコアを計算し、サンプルサイズに関して結果をスケーリングすることによって、異常スコアを割り当てます。RCF アルゴリズムは、リファレンス [1] で説明されているものに基づいています。
ランダムなデータのサンプリング
RCF アルゴリズムにおける最初のステップは、トレーニングデータのランダムなサンプルを取得することです。特に、合計データポイント
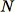 からのサイズ
からのサイズ
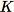 のサンプルが必要だとします。トレーニングデータが十分に小さければ、データセット全体を使用することができ、このセットからランダムに
個の要素を抽出することができます。ただし、多くの場合、トレーニングデータが大きすぎてすべてが一度には収まらないため、このアプローチは実行不可能です。代わりに、貯蔵サンプリングと呼ばれる手法を使用します。
のサンプルが必要だとします。トレーニングデータが十分に小さければ、データセット全体を使用することができ、このセットからランダムに
個の要素を抽出することができます。ただし、多くの場合、トレーニングデータが大きすぎてすべてが一度には収まらないため、このアプローチは実行不可能です。代わりに、貯蔵サンプリングと呼ばれる手法を使用します。
貯蓄サンプリング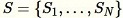 からランダムなサンプルを効率的に引き出すためのアルゴリズムであり、データセット内の要素は一度に 1 つずつまたはバッチで観測できます。実際に、
が事前に認識されていなくても、貯蓄サンプリングは成功します。
からランダムなサンプルを効率的に引き出すためのアルゴリズムであり、データセット内の要素は一度に 1 つずつまたはバッチで観測できます。実際に、
が事前に認識されていなくても、貯蓄サンプリングは成功します。
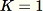 である場合など、1 つのサンプルしかリクエストされない場合、アルゴリズムは次のようになります。
である場合など、1 つのサンプルしかリクエストされない場合、アルゴリズムは次のようになります。
アルゴリズム: 貯蔵サンプリング
-
入力: データセットまたはデータストリーム
-
ランダムなサンプル
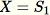 の初期化
の初期化 -
確認済みのサンプルごと
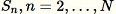 :
:-
均一な乱数
![Equation in text-form: \xi \in [0,1]](images/rcf6.jpg) を選択
を選択 -
もし
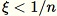
-
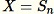 を設定する
を設定する
-
-
-
戻り値
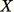
このアルゴリズムは、すべての
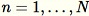 において
において
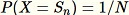 となるようなランダムなサンプルを選択します。
となるようなランダムなサンプルを選択します。
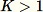 である場合、アルゴリズムはさらに複雑になります。また、ランダムサンプリングの中で置き換えがあるものとないものの区別が必要です。RCF は、[2] で説明されているアルゴリズムに基づいて、トレーニングデータに対して置き換えのない拡張貯蔵サンプリングを実行します。
である場合、アルゴリズムはさらに複雑になります。また、ランダムサンプリングの中で置き換えがあるものとないものの区別が必要です。RCF は、[2] で説明されているアルゴリズムに基づいて、トレーニングデータに対して置き換えのない拡張貯蔵サンプリングを実行します。
RCF モデルをトレーニングして推論を生成する
RCF の次のステップは、ランダムなデータサンプルを使用してランダムカットフォレストを構築することです。まず、サンプルは、フォレスト内のツリー数に等しく、等しいサイズのパーティション数に分割されます。次に、各パーティションは個々のツリーに送信されます。ツリーは、データドメインを境界ボックスに分割することにより、そのパーティションを再帰的にバイナリツリーに編成します。
この手順を、分かりやすく例を挙げて説明しましょう。たとえば、あるツリーに次の 2 次元データセットが指定されているとします。対応するツリーは、ルートノードに初期化されます。
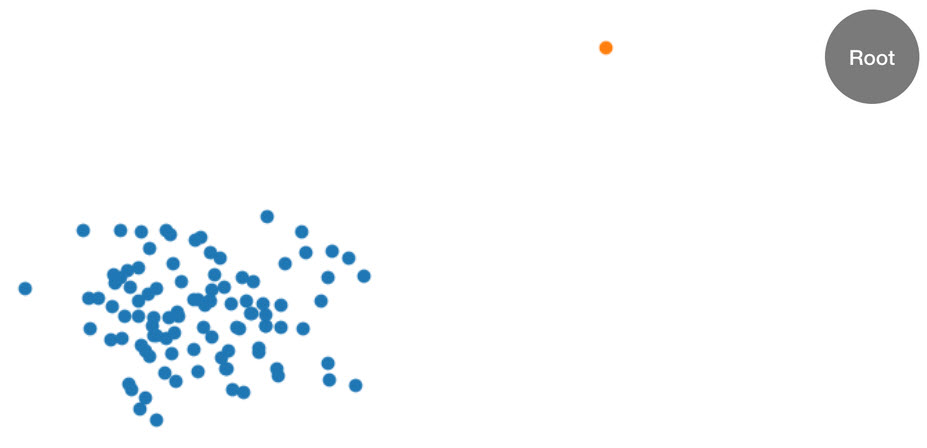
図: 1 つの異常データポイント (オレンジ色) を除き、ほとんどのデータがクラスター内 (青) にある 2 次元データセット。ツリーはルートノードで初期化されます。
RCF アルゴリズムは、まずデータの境界ボックスを計算し、ランダムな次元 (より高い「分散」を持つ次元の重み付けを高くする) を選択し、その後、その次元を通して超平面「カット」の位置をランダムに決定することにより、ツリー内のこれらのデータを整理します。生成される 2 つのサブスペースが独自のサブツリーを定義します。この例では、カットにより、サンプルの残りの部分から孤立したポイントが分離されます。結果のバイナリツリーの最初のレベルは、2 つのノードで構成されます。1 つは、最初のカットの左側のポイントのサブツリーを構成し、もう 1 つは右側にある単一点を表します。
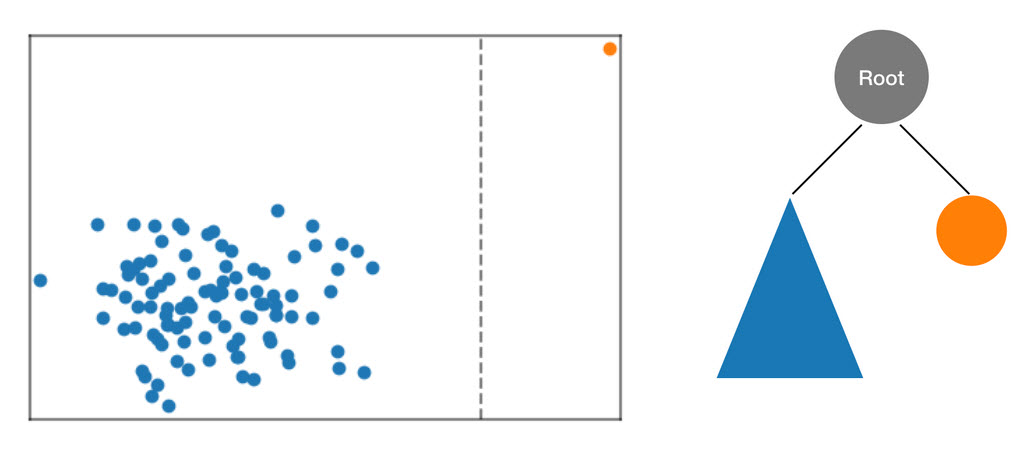
図: 2 次元データセットを分割するランダムなカット。異常なデータポイントは、他のポイントよりも小さなツリーの深さの境界ボックスに孤立して存在する可能性が高くなります。
その後、境界ボックスはデータの左右の半分それぞれについて計算され、ツリーの各葉がサンプルからの単一のデータポイントを表すようになるまでプロセスが繰り返されます。孤立したポイントが十分に離れている場合、ランダムなカットはポイント分離という結果になる可能性が高くなります。この観察は、大まかに言えば、ツリーの深さが異常スコアに反比例することを示しています。
トレーニング済みの RCF モデルを使用して推論を実行する場合、最終的な異常スコアは各ツリーで報告されるスコア全体の平均として報告されます。新しいデータポイントは、ツリーにまだ存在しないことがありますのでご注意ください。新しいポイントに関連付けられたスコアを確認するには、データポイントが指定されたツリーに挿入され、ツリーが効率的に (また一時的に) 上述のトレーニングプロセスと同等の方法で再構築されることが必要です。つまり、結果のツリーでは、その入力データポイントはツリーの構築時に最初に使用されたサンプルのメンバーのようになります。報告されたスコアは、ツリー内の入力ポイントの深さに反比例します。
ハイパーパラメータを選択する
RCF モデルを調整するために使用される主なハイパーパラメータは num_trees と num_samples_per_tree です。最終スコアは各ツリーで報告されるスコアの平均であるため、num_trees が増加すると、異常スコアで観察されるノイズは減少します。最適な値はアプリケーションごとに異なりますが、スコアノイズとモデル複雑さ間のバランスとして最初に 100 ツリーを使用することをお勧めします。推論時間はツリーの数に比例することに注意してください。トレーニング時間も影響を受けますが、大方は上述の貯蔵サンプリングアルゴリズムによって決まります。
パラメータ num_samples_per_tree は、データセット内で想定される異常の密度と関連しています。特に、num_samples_per_tree が異常データの比率を通常データに近づけるように 1/num_samples_per_tree を選択する必要があります。たとえば、各ツリーで 256 サンプルを使用する場合、時間の 256 分の 1、つまりおよそ 0.4% の異常がデータに含まれていることが予測されます。ここでも、このハイパーパラメータの最適な値はアプリケーションに応じて異なります。
リファレンス
-
Sudipto Guha、Nina Mishra、Gourav Roy、および Okke Schrijvers。「堅牢なランダムカットフォレストベースの、ストリームにおける異常検出。」 機械学習に関する国際会議、2712~2721 ページ、2016 年。
-
Byung-Hoon Park、George Ostrouchov、Nagiza F. Samatova、および Al Geist。「貯蔵ベースの、データストリームから置換可能なランダムサンプリング。」 2004 年データマイニングに関する SIAM 国際会議会報、492 ~ 496 ページ。Society for Industrial and Applied Mathematics、2004 年。
