HyperPod が提供する基本ライフサイクルスクリプトから開始する
このセクションでは、トップダウンアプローチを使用して HyperPod で Slurm を設定する基本的なフローのすべてのコンポーネントについて説明します。これは、CreateCluster API を実行する HyperPod クラスター作成リクエストの準備から始まり、階層構造をライフサイクルスクリプトにまで掘り下げます。Awsome Distributed Training GitHub リポジトリ
git clone https://github.com/aws-samples/awsome-distributed-training/
SageMaker HyperPod で Slurm クラスターを設定するための基本ライフサイクルスクリプトは、1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
cd awsome-distributed-training/1.architectures/5.sagemaker_hyperpods/LifecycleScripts/base-config
次のフローチャートは、基本ライフサイクルスクリプトの設計方法の詳細な概要を示しています。以下の図と手順ガイドでは、HyperPod CreateCluster API コール時の動作について説明しています。
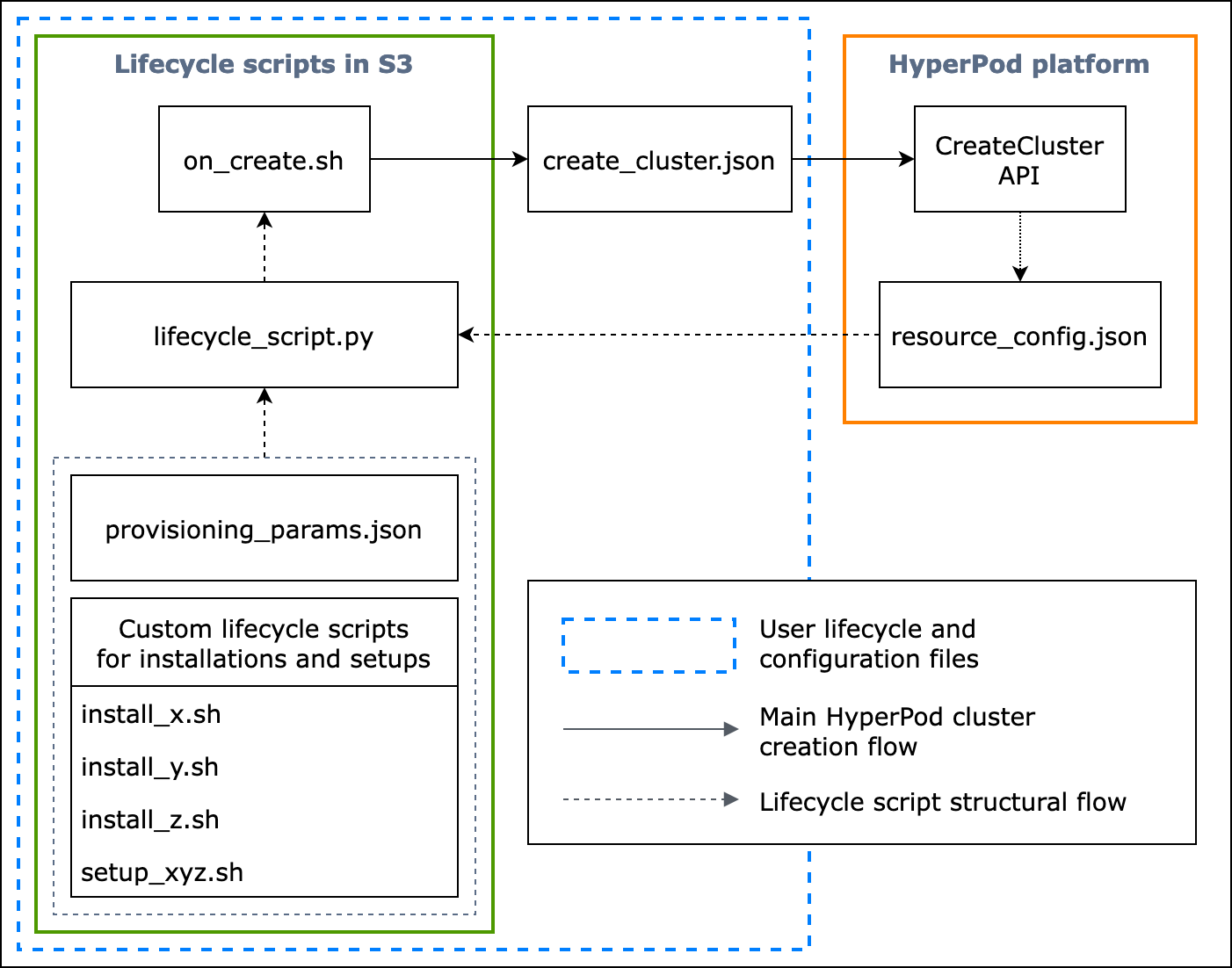
図: HyperPod クラスター作成とライフサイクルスクリプトの構造の詳細なフローチャート。(1) 破線の矢印はボックスが「呼び出される」場所を指しており、設定ファイルとライフサイクル スクリプトの準備の流れを示しています。provisioning_parameters.json とライフサイクルスクリプトの準備から始まります。その後、これらは lifecycle_script.py でコード化され、集合実行が順番に行われます。また、lifecycle_script.py スクリプトの実行は、HyperPod インスタンスターミナルで実行される on_create.sh シェルスクリプトによって行われます。(2) 実線の矢印は、HyperPod クラスターの主な作成フローと、ボックスがどのように「呼び出される」か、または「送信される」かを示しています。on_create.sh は、create_cluster.json またはコンソール UI の [クラスターを作成] リクエストフォームのいずれかで、クラスター作成リクエストに必要となります。リクエストを送信すると、HyperPod はリクエストとライフサイクルスクリプトの指定された設定情報に基づいて CreateCluster API を実行します。(3) 点線の矢印は、クラスターリソースのプロビジョニング時に HyperPod プラットフォームがクラスターインスタンスに resource_config.json を作成することを示しています。resource_config.json には、クラスター ARN、インスタンスタイプ、IP アドレスなどの HyperPod クラスターリソース情報が含まれています。クラスターの作成時に resource_config.json ファイルを期待するようライフサイクルスクリプトを準備する必要がある点に注意してください。詳細については、以下の手順ガイドを参照してください。
以下の手順ガイドでは、HyperPod クラスターの作成中に何が起こるか、および基本ライフサイクルスクリプトの設計方法について説明しています。
-
create_cluster.json– HyperPod クラスター作成リクエストを送信するには、JSON 形式のCreateClusterリクエストファイルを準備します。このベストプラクティス例では、リクエストファイルの名前がcreate_cluster.jsonであると想定しています。インスタンスグループを使用して HyperPod クラスターをプロビジョニングするには、create_cluster.jsonを書き込みます。ベストプラクティスとして、HyperPod クラスターで設定する予定の Slurm ノードの数と同じ数のインスタンスグループを追加することをお勧めします。設定する予定の Slurm ノードに割り当てるインスタンスグループに、固有の名前を付けてください。さらに、S3 バケットパスを指定して、設定ファイルとライフサイクルスクリプトのセット全体を
CreateClusterリクエストフォームのフィールド名InstanceGroups.LifeCycleConfig.SourceS3Uriに保存し、エントリポイントシェルスクリプトのファイル名 (on_create.shという名前であると想定します) をInstanceGroups.LifeCycleConfig.OnCreateに指定する必要があります。注記
HyperPod コンソール UI で [クラスターを作成] 送信フォームを使用する場合、コンソールはユーザーに代わって
CreateClusterリクエストの入力と送信を管理し、CreateClusterAPI をバックエンドで実行します。この場合、create_cluster.jsonを作成する必要はありません。代わりに、[クラスターを作成] 送信フォームに正しいクラスター設定情報を指定してください。 -
on_create.sh– インスタンスグループごとに、コマンドを実行するエントリポイントシェルスクリプトon_create.shを提供して、ソフトウェアパッケージをインストールするスクリプトを実行し、Slurm のある HyperPod クラスター環境を設定する必要があります。Slurm を設定するために HyperPod が必要とするprovisioning_parameters.jsonと、ソフトウェアパッケージをインストールするための一連のライフサイクルスクリプトの 2 つを準備する必要があります。このスクリプトは、on_create.shのサンプルスクリプトに示すように、以下のファイルを検索して実行するよう記述する必要があります。 注記
ライフサイクルスクリプトのセット全体を、
create_cluster.jsonで指定した S3 の場所にアップロードしてください。さらに、provisioning_parameters.jsonを同じ場所に配置する必要もあります。-
provisioning_parameters.json– これは HyperPod で Slurm ノードをプロビジョニングするための設定フォーム です。on_create.shスクリプトはこの JSON ファイルを見つけ、そのパスを識別するための環境変数を定義します。この JSON ファイルを使用して、通信する Slurm 用 Amazon FSx for Lustre などの Slurm ノードとストレージオプションを設定できます。provisioning_parameters.jsonでは、create_cluster.jsonで指定した名前を使用して HyperPod クラスターインスタンスグループを、設定方法に基づいて Slurm ノードに適切に割り当ててください。次の図は、HyperPod インスタンスグループが Slurm ノードに割り当てられるよう 2 つの JSON 設定ファイル
create_cluster.jsonおよびprovisioning_parameters.jsonを記述する方法の例を示しています。この例では、コントローラー (管理) ノード、ログインノード (オプション)、コンピューティング (ワーカー) ノードの 3 つの Slurm ノードを設定するケースを想定しています。ヒント
これらの 2 つの JSON ファイルを検証するため、HyperPod サービスチームは検証スクリプト
validate-config.pyを用意しています。詳細については、「HyperPod で Slurm クラスターを作成する前に JSON 設定ファイルを検証する」を参照してください。 
図: HyperPod クラスター作成用の
create_cluster.jsonと Slurm 設定用のprovisiong_params.jsonの直接比較。create_cluster.jsonのインスタンスグループの数は、Slurm ノードとして設定するノードの数と一致する必要があります。図の例のケースでは、3 つのインスタンスグループの HyperPod クラスターに 3 つの Slurm ノードが設定されます。HyperPod クラスターインスタンスグループは、インスタンスグループ名を適切に指定して Slurm ノードに割り当てる必要があります。 -
resource_config.json– クラスターの作成時、lifecycle_script.pyスクリプトは HyperPod からのresource_config.jsonファイルを期待するよう記述されます。このファイルには、インスタンスタイプや IP アドレスなど、クラスターに関する情報が含まれています。CreateClusterAPI を実行すると、HyperPod はcreate_cluster.jsonファイルに基づいて/opt/ml/config/resource_config.jsonにリソース設定ファイルを作成します。ファイルパスは、SAGEMAKER_RESOURCE_CONFIG_PATHという名前の環境変数に保存されます。重要
resource_config.jsonファイルは、HyperPod プラットフォームによって自動生成されるため、作成する必要はありません。次のコードは、前のステップでcreate_cluster.jsonに基づいてクラスターの作成から作成されるresource_config.jsonの例を示しており、バックエンドで何が行われ、自動生成されたresource_config.jsonがどのようになるかを理解するのに役立ちます。{ "ClusterConfig": { "ClusterArn": "arn:aws:sagemaker:us-west-2:111122223333:cluster/abcde01234yz", "ClusterName": "your-hyperpod-cluster" }, "InstanceGroups": [ { "Name": "controller-machine", "InstanceType": "ml.c5.xlarge", "Instances": [ { "InstanceName": "controller-machine-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "login-group", "InstanceType": "ml.m5.xlarge", "Instances": [ { "InstanceName": "login-group-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] }, { "Name": "compute-nodes", "InstanceType": "ml.trn1.32xlarge", "Instances": [ { "InstanceName": "compute-nodes-1", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-2", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-3", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" }, { "InstanceName": "compute-nodes-4", "AgentIpAddress": "111.222.333.444", "CustomerIpAddress": "111.222.333.444", "InstanceId": "i-12345abcedfg67890" } ] } ] } -
lifecycle_script.py– これは、プロビジョニング中に HyperPod クラスターで Slurm を設定するライフサイクルスクリプトをまとめて実行するメイン Python スクリプトです。このスクリプトは、on_create.shで指定または識別されたパスからprovisioning_parameters.jsonおよびresource_config.jsonを読み取り、関連情報を各ライフサイクルスクリプトに渡してから、ライフサイクルスクリプトを順番に実行します。ライフサイクルスクリプトは、Slurm の設定、ユーザーの作成、Conda または Docker のインストールなど、クラスターの作成中にソフトウェアパッケージをインストールしたり、必要な設定やカスタム設定をセットアップしたりするためにカスタマイズできる高い柔軟性を持つスクリプトのセットです。サンプル
lifecycle_script.pyスクリプトは、Slurm デーモン ( start_slurm.sh) の起動、Amazon FSx for Lustre ( mount_fsx.sh) のマウント、MariaDB アカウンティング ( setup_mariadb_accounting.sh) と RDS アカウンティング ( setup_rds_accounting.sh) の設定など、リポジトリで他の基本ライフサイクルスクリプトを実行する準備ができています。さらに、スクリプトを追加して、同じディレクトリにパッケージ化し、コード行を lifecycle_script.pyに追加して、HyperPod がスクリプトを実行可能にすることもできます。基本ライフサイクルスクリプトの詳細については、Awsome Distributed Training GitHub リポジトリ の「3.1 Lifecycle scripts」も参照してください。 注記
HyperPod はクラスターの各インスタンスで SageMaker HyperPod DLAMI を実行します。AMI には、AMI と HyperPod の機能の互換性に準拠したソフトウェアパッケージがプリインストールされています。プリインストールされたパッケージのいずれかを再インストールする場合、互換性のあるパッケージをインストールしなければならず、一部の HyperPod 機能が正常に動作しない場合がある点に注意してください。
デフォルトのセットアップに加えて、以下のソフトウェアをインストールするための他のスクリプトが
utilsフォルダに用意されています。 lifecycle_script.pyファイルは、インストールスクリプトを実行するためのコード行を含める準備が既に整っているため、以下の項目を参照して行を検索し、コメントを解除してアクティブ化してください。-
次のコード行は、Docker
、Enroot 、および Pyxis をインストールするためのものです。これらのパッケージは、Slurm クラスターで Docker コンテナを実行するために必要です。 このインストールステップを有効にするには、
config.pyファイルで enable_docker_enroot_pyxisパラメータをTrueに設定します。# Install Docker/Enroot/Pyxis if Config.enable_docker_enroot_pyxis: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_enroot_pyxis.sh").run(node_type) -
HyperPod クラスターを Amazon Managed Service for Prometheus および Amazon Managed Grafana と統合して、HyperPod クラスターとクラスターノードに関するメトリクスを Amazon Managed Grafana ダッシュボードにエクスポートできます。メトリクスをエクスポートし、Amazon Managed Grafana で Slurm ダッシュボード
、NVIDIA DCGM Exporter ダッシュボード 、および EFA Metrics ダッシュボード を使用するには、Prometheus の Slurm エクスポーター 、NVIDIA DCGM エクスポーター 、および EFA ノードエクスポーター をインストールする必要があります。エクスポーターパッケージのインストールと Amazon Managed Grafana ワークスペースでの Grafana ダッシュボードの使用の詳細については、「SageMaker HyperPod クラスターリソースのモニタリング」を参照してください。 このインストールステップを有効にするには、
config.pyファイルで enable_observabilityパラメータをTrueに設定します。# Install metric exporting software and Prometheus for observability if Config.enable_observability: if node_type == SlurmNodeType.COMPUTE_NODE: ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_dcgm_exporter.sh").run() ExecuteBashScript("./utils/install_efa_node_exporter.sh").run() if node_type == SlurmNodeType.HEAD_NODE: wait_for_scontrol() ExecuteBashScript("./utils/install_docker.sh").run() ExecuteBashScript("./utils/install_slurm_exporter.sh").run() ExecuteBashScript("./utils/install_prometheus.sh").run()
-
-
-
ステップ 2 のすべての設定ファイルとセットアップスクリプトを、ステップ 1 の
CreateClusterリクエストで指定した S3 バケットにアップロードしてください。例えば、create_cluster.jsonに以下のものがあるとします。"LifeCycleConfig": { "SourceS3URI": "s3://sagemaker-hyperpod-lifecycle/src", "OnCreate": "on_create.sh" }その場合、
"s3://sagemaker-hyperpod-lifecycle/src"には、on_create.sh、lifecycle_script.py、provisioning_parameters.json、および他のすべてのセットアップスクリプトが含まれています。次のように、ローカルフォルダにファイルを準備したとします。└── lifecycle_files // your local folder ├── provisioning_parameters.json ├── on_create.sh ├── lifecycle_script.py └── ... // more setup scrips to be fed into lifecycle_script.pyファイルをアップロードするには、次のように S3 コマンドを使用します。
aws s3 cp --recursive./lifecycle_scriptss3://sagemaker-hyperpod-lifecycle/src
