翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
モデルプロバイダーの設定
注記
このセクションは、使用を予定している言語モデルおよび埋め込みモデルがすでにデプロイされていることを前提としています。が提供するモデルの場合 AWS、SageMaker AI エンドポイントの ARN または Amazon Bedrock へのアクセスが既に必要です。他のモデルプロバイダーを使用する場合は、モデルへのリクエストを認証および承認するための API キーが必要になります。
Jupyter AI は幅広いモデルプロバイダーと言語モデルをサポートしています。サポートされるモデル
Jupyter AI の設定は、チャット UI とマジックコマンドのどちらを使用するかによって異なります。
チャット UI でモデルプロバイダーを設定する
注記
同じ手順で多数の LLM と埋め込みモデルを設定できます。ただし、言語モデルを少なくとも 1 つは設定する必要があります。
チャット UI を設定するには
-
JupyterLab で、左側のナビゲーションパネルのチャットアイコン (
 ) を選択して、チャットインターフェイスに移動します。
) を選択して、チャットインターフェイスに移動します。 -
左ペインの右上隅にある設定アイコン (
 ) を選択します。Jupyter AI の設定パネルが開きます。
) を選択します。Jupyter AI の設定パネルが開きます。 -
サービスプロバイダーの各フィールドを入力します。
-
JumpStart または Amazon Bedrock が提供するモデルの場合
-
言語モデルドロップダウンリストで、JumpStart でデプロイされるモデルの場合は
sagemaker-endpointを、Amazon Bedrock で管理されるモデルの場合はbedrockを選択します。 -
パラメータは、モデルが SageMaker AI にデプロイされているか Amazon Bedrock にデプロイされているかによって異なります。
-
JumpStart でデプロイされたモデルの場合:
-
エンドポイント名にエンドポイントの名前を入力し、次にモデル AWS リージョン がリージョン名にデプロイされる を入力します。SageMaker AI エンドポイントの ARN を取得するには、 に移動https://console.aws.amazon.com/sagemaker/
し、左側のメニューで推論とエンドポイントを選択します。 -
使用するモデルのリクエストスキーマの JSON と、モデルの出力を解析するためのレスポンスパスを貼り付けます。
注記
さまざまな JumpStart 基盤モデルのリクエストとレスポンスの形式を、ノートブックのサンプル
で確認できます。各ノートブックの名前に、サンプルで紹介するモデルの名前が使用されます。
-
-
Amazon Bedrock によって管理されるモデルの場合: システムに認証情報を保存する AWS AWS プロファイルを追加し (オプション)、次にモデルがリージョン名 AWS リージョン にデプロイされる を追加します。
-
-
(オプション) アクセス可能な埋め込みモデルを選択します。埋め込みモデルは、テキスト生成モデルがローカルドキュメントのコンテキスト内で質問に回答するために必要な追加情報をローカルドキュメントから取得するために使用します。
-
[変更を保存] を選択し、左ペインの左上隅にある左矢印アイコン (
 ) に移動します。Jupyter AI チャット UI が開きます。モデルの操作を開始できます。
) に移動します。Jupyter AI チャット UI が開きます。モデルの操作を開始できます。
-
-
サードパーティープロバイダーによりホストされるモデルの場合
-
[言語モデル] ドロップダウンリストで、プロバイダー ID を選択します。各プロバイダーの情報 (ID など) を、Jupyter AI のモデルプロバイダーの一覧
で確認してください。 -
(オプション) アクセス可能な埋め込みモデルを選択します。埋め込みモデルは、テキスト生成モデルがローカルドキュメントのコンテキスト内で質問に回答するために必要な追加情報をローカルドキュメントから取得するために使用します。
-
モデルの API キーを挿入します。
-
[変更を保存] を選択し、左ペインの左上隅にある左矢印アイコン (
) に移動します。Jupyter AI チャット UI が開きます。モデルの操作を開始できます。
-
-
次のスナップショットは、JumpStart によって提供され、SageMaker AI にデプロイされた Flan-t5-small モデルを呼び出すように設定されたチャット UI 設定パネルを示しています。
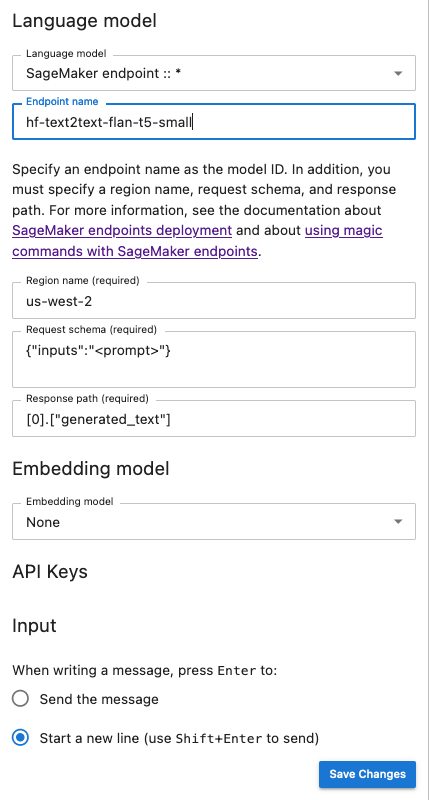
追加のモデルパラメータとカスタムパラメータをリクエストに渡す
例えば、ユーザー契約の承認のためにカスタマイズされた属性を使用する、他のモデルのパラメータ (温度やレスポンスの長さなど) の調整に使用するなど、モデルに追加のパラメータが必要になる場合があります。これらは JupyterLab アプリケーションの最初の設定オプションとして、ライフサイクル設定を使用して設定することをお勧めします。ライフサイクル設定を作成してドメインにアタッチする方法、または SageMaker AI コンソール
次の JSON スキーマを使用して、追加のパラメータ を設定します:
{ "AiExtension": { "model_parameters": { "<provider_id>:<model_id>": { Dictionary of model parameters which is unpacked and passed as-is to the provider.} } } } }
次のスクリプトは、JupyterLab アプリケーションの LCC を作成する際に使用する JSON 設定ファイルの例です。Amazon Bedrock にデプロイされた AI21 Labs Jurassic-2 モデルの最大長を設定しています。モデルが生成するレスポンスの長さを大きくすると、モデルのレスポンスがシステムによって切り捨てられるのを防ぐことができます。
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:ai21.j2-mid-v1": {"model_kwargs": {"maxTokens": 200}}}}}' # equivalent to %%ai bedrock:ai21.j2-mid-v1 -m {"model_kwargs":{"maxTokens":200}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
次のスクリプトは、JupyterLab アプリケーション LCC の作成に必要な JSON 設定ファイルの例です。Amazon Bedrock にデプロイされる Anthropic Claude モデルに追加のモデルパラメータを設定しています。
#!/bin/bash set -eux mkdir -p /home/sagemaker-user/.jupyter json='{"AiExtension": {"model_parameters": {"bedrock:anthropic.claude-v2":{"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":25 0,"max_tokens_to_sample":2}}}}}' # equivalent to %%ai bedrock:anthropic.claude-v2 -m {"model_kwargs":{"temperature":0.1,"top_p":0.5,"top_k":250,"max_tokens_to_sample":2000}} # File path file_path="/home/sagemaker-user/.jupyter/jupyter_jupyter_ai_config.json" #jupyter --paths # Write JSON to file echo "$json" > "$file_path" # Confirmation message echo "JSON written to $file_path" restart-jupyter-server # Waiting for 30 seconds to make sure the Jupyter Server is up and running sleep 30
LCC をドメイン (ユーザープロファイル) にアタッチしたら、LCC をスペースに追加して JupyterLab アプリケーションを起動します。この LCC で設定ファイルを更新するには、ターミナルで more ~/.jupyter/jupyter_jupyter_ai_config.json を実行します。ファイルの内容が、LCC に渡される JSON ファイルの内容に一致している必要があります。
ノートブックでモデルプロバイダーを設定する
JupyterLab または Studio Classic ノートブックで Jupyter AI を経由し、%%ai および %ai のマジックコマンドを使用してモデルを呼び出すには
-
モデルプロバイダーに固有のクライアントライブラリを、ノートブック環境にインストールします。例えば、OpenAI モデルを使用する場合は、
openaiクライアントライブラリをインストールします。各プロバイダーで必要となるクライアントライブラリのリストについては、Jupyter AI のモデルプロバイダーのリストで、Python パッケージの列を参照してください。 注記
でホストされているモデルの場合 AWS、
boto3は JupyterLab で使用される SageMaker AI ディストリビューションイメージ、または Studio Classic で使用されるデータサイエンスイメージにインストール済みです。 -
-
によってホストされるモデルの場合 AWS
実行ロールに、JumpStart が提供するモデルの SageMaker AI エンドポイントを呼び出すアクセス許可があるか、Amazon Bedrock にアクセスできることを確認します。
-
サードパーティープロバイダーによりホストされるモデルの場合
ノートブック環境で環境変数を使用し、プロバイダーの API キーをエクスポートします。以下のマジックコマンドを使用できます。コマンドの
provider_API_keyを環境変数に置き換えてください。環境変数については、プロバイダーの Jupyter AI のモデルプロバイダーのリストで、環境変数の列を参照してください。 %env provider_API_key=your_API_key
-
