翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
カスタムワーカータスクテンプレートの作成
カスタムラベル付けジョブを作成するには、ワーカータスクテンプレートを更新し、マニフェストファイルの入力データをテンプレートで使用される変数にマッピングし、出力データを Amazon S3 にマッピングする必要があります。Liquid オートメーションを使用する高度な機能の詳細については、「Liquid を使用してオートメーションを追加する」を参照してください。
以降のセクションで、各手順について説明します。
ワーカータスクテンプレート
ワーカータスクテンプレートは、Ground Truth でワーカーのユーザーインターフェイス (UI) をカスタマイズするために使用するファイルです。ワーカータスクテンプレートは、HTML、CSS、JavaScript、Liquid テンプレート言語
次のトピックでは、ワーカータスクテンプレートを作成する方法について説明します。Ground Truth ワーカータスクテンプレートの例のリポジトリは、GitHub
SageMaker AI コンソールでのベースワーカータスクテンプレートの使用
Ground Truth コンソールのテンプレートエディタを使用して、テンプレートの作成を開始できます。このエディタには、事前に設計された多数のベーステンプレートが含まれています。HTML および Crowd HTML Element コードの自動入力をサポートしています。
Ground Truth カスタムテンプレートエディタにアクセスするには、次の手順を実行します。
-
「ラベル付けジョブの作成 (コンソール)」の手順に従います。
-
次に、カスタムをラベル付けジョブのタスクタイプに選択します。
-
[次へ] を選択すると、[カスタムラベル付けタスクの設定] セクションのテンプレートエディタと基本テンプレートにアクセスできます。
-
(オプション) [Templates] (テンプレート) のドロップダウンメニューから基本テンプレートを選択します。テンプレートを最初から作成する場合は、ドロップダウンメニューから [Custom] (カスタム) を選択して、最小スケルトンのテンプレートを使用します。
次のセクションでは、コンソールでローカルに開発されたテンプレートを視覚化する方法について説明します。
ワーカータスクテンプレートをローカルで視覚化する
コンソールを使用して、受信したデータをテンプレートがどのように処理するかをテストする必要があります。テンプレートの HTML 要素とカスタム要素がどのように表示されるかをテストするには、ブラウザを使用します。
注記
変数は解析されません。コンテンツをローカルで表示するときに、変数をサンプルコンテンツに置き換える必要があります。
次のコードスニペットの例は、カスタムな HTML 要素を描画するために必要なコードを読み込みます。これは、テンプレートのルックアンドフィールをコンソールではなく任意のエディタで開発する場合に使用します。
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
シンプルな HTML タスクのサンプルの作成
これで、ベースとなるワーカータスクテンプレートが作成されました。このトピックで、シンプルな HTML ベースのタスクテンプレートを作成していきます。
以下は、入力マニフェストファイルの入力例です。
{ "source": "This train is really late.", "labels": [ "angry" , "sad", "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }
HTML タスクテンプレートで、入力マニフェストファイルの変数をテンプレートにマッピングする必要があります。サンプル入力マニフェストの変数は、task.input.source、task.input.labels、および task.input.header の構文を使用してマッピングされます。
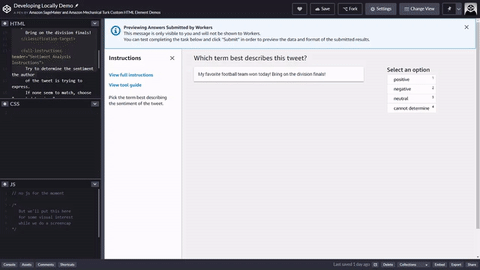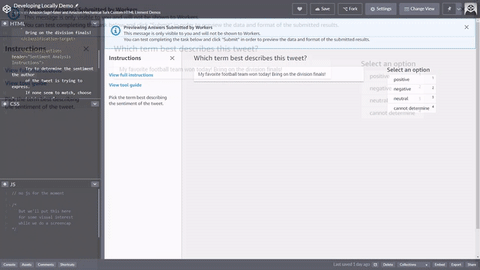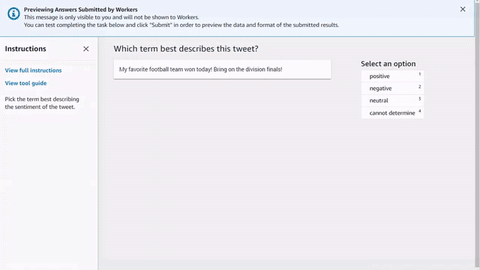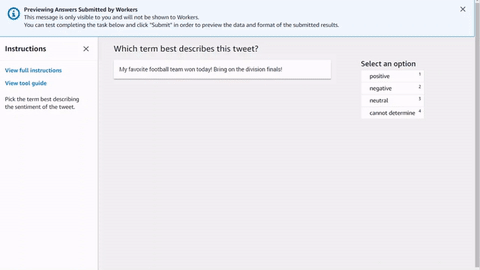
以下は、ツイートを分析するシンプルな HTML ワーカータスクテンプレートの例です。すべてのタスクは <crowd-form> </crowd-form> 要素で開始および終了します。標準の HTML <form> 要素と同様に、すべてのフォームコードはそれらの間に記述します。Ground Truth は、注釈前 Lambda を実装しない限り、テンプレートで指定されたコンテキストから直接ワーカーのタスクを生成します。Ground Truth または 前注釈 Lambda によって返される taskInput オブジェクトは、テンプレートの task.input オブジェクトです。
シンプルなツイート分析タスクでは、<crowd-classifier> 要素を使用します。以下の属性は必須です。
name - 出力変数の名前。ワーカー注釈は、出力マニフェストでこの変数名に保存されます。
categories - JSON 形式の配列による考えられる回答。
header - 注釈ツールのタイトル。
<crowd-classifier> 要素には、少なくとも次の 3 つの子要素が必要です。
<classification-target> - 上記の
categories属性に指定されたオプションに基づいてワーカーが分類するテキスト。<full-instructions> - ツールの [詳細な手順の表示] リンクから表示できる手順。これを空白のままにすることはできますが、より良い結果を得るための適切な手順を提供することをお勧めします。
<short-instructions> - ツールのサイドバーに表示される、タスクのより簡単な説明。これを空白のままにすることはできますが、より良い結果を得るための適切な手順を提供することをお勧めします。
このツールのシンプルなバージョンを下に示します。変数 {{ task.input.source }} により、入力マニフェストファイルのソースデータが指定されます。{{ task.input.labels | to_json }} は配列を JSON 表現に変換するための変数フィルターの例です。categories 属性は JSON である必要があります。
例 サンプル入力マニフェスト のJSON で crowd-classifier を使用する例
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="tweetFeeling"categories="='{{ task.input.labels | to_json }}'" header="{{ task.input.header }}'" > <classification-target>{{ task.input.source }}</classification-target> <full-instructions header="Sentiment Analysis Instructions"> Try to determine the sentiment the author of the tweet is trying to express. If none seem to match, choose "cannot determine." </full-instructions> <short-instructions> Pick the term that best describes the sentiment of the tweet. </short-instructions> </crowd-classifier> </crowd-form>
Ground Truth ラベル付けジョブ作成ワークフローでコードをエディタにコピーアンドペーストしてツールをプレビューするか、CodePen でこのコードのデモ
入力データ、外部アセット、タスクテンプレート
以下のセクションでは、外部アセットの使用、入力データ形式の要件、注釈前 Lambda 関数の使用を検討するタイミングについて説明します。
入力データ形式の要件
入力マニフェストファイルを作成してカスタムな Ground Truth ラベル付けジョブで使用するする場合、データを Amazon S3 に保存する必要があります。入力マニフェストファイルも、カスタム Ground Truth ラベル付けジョブを実行するのと同じ AWS リージョン に保存する必要があります。さらに、カスタムラベル付けジョブの Ground Truth での実行に使用する IAM サービスロールへのアクセスが可能な任意の Amazon S3 バケットに保存できます。
入力マニフェストファイルは、改行区切りの JSON または JSON 行形式を使用する必要があります。各行は、標準の改行 \n や \r\n で区切られています。各行も、有効な JSON オブジェクトである必要があります。
さらに、マニフェストファイルの各 JSON オブジェクトには、source-ref または source のいずれかのキーが含まれている必要があります。キーの値は、次のように解釈されます。
-
source-ref- オブジェクトのソースは、値に指定された Amazon S3 オブジェクトです。オブジェクトがイメージなどのバイナリオブジェクトである場合、この値を使用します。 -
source- オブジェクトのソースが値です。オブジェクトがテキスト値の場合は、この値を使用します。
入力マニフェストファイルの書式化の詳細については、「入力マニフェストファイル」を参照してください。
注釈前の Lambda 関数
オプションで、注釈前 Lambda 関数を指定して、ラベル付けの前に入力マニフェストファイルからデータをどのように処理するかを管理できます。isHumanAnnotationRequired キーと値のペアを指定した場合は、注釈前の Lambda 関数を使用する必要があります。Ground Truth が注釈前 Lambda 関数を JSON 形式のリクエストに送信すると、次のスキーマが使用されます。
例 source-ref キーと値のペアで識別されるデータオブジェクト
{ "version": "2018-10-16", "labelingJobArn":arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source-ref":s3://input-data-bucket/data-object-file-name} }
例 source キーと値のペアで識別されるデータオブジェクト
{ "version": "2018-10-16", "labelingJobArn" :arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source":Sue purchased 10 shares of the stock on April 10th, 2020} }
isHumanAnnotationRequired を使用する場合に予想される Lambda 関数からのレスポンスを次に示します。
{ "taskInput":{ "source": "This train is really late.", "labels": [ "angry" , "sad" , "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }, "isHumanAnnotationRequired":False}
外部アセットの使用
Amazon SageMaker Ground Truth カスタムテンプレートを使用すると、外部スクリプトやスタイルシートを埋め込むことができます。例えば、次のコードブロックは、https://www.example.com/my-enhancement-styles.css にあるスタイルシートをテンプレートに追加する方法を示しています。
<script src="https://www.example.com/my-enhancment-script.js"></script> <link rel="stylesheet" type="text/css" href="https://www.example.com/my-enhancement-styles.css">
エラーが発生した場合は、元のサーバーがアセットを含む正しい MIME タイプとエンコードヘッダーを送信していることを確認します。
例えば、リモートスクリプト用の MIME とエンコードタイプは application/javascript;CHARSET=UTF-8 です。
リモートスタイルシート用の MIME と エンコードタイプは text/css;CHARSET=UTF-8 です。
出力データとタスクテンプレート
以下のセクションでは、カスタムラベル付けジョブからの出力データと、注釈後の Lambda 関数の使用を検討するタイミングについて説明します。
出力データ
カスタムラベル付けジョブが完了すると、ラベル付けジョブの作成時に指定された Amazon S3 バケットにデータが保存されます。データは output.manifest ファイルに保存されます。
注記
labelAttributeName はプレースホルダー変数です。出力では、ラベル付けジョブの名前、またはラベル付けジョブの作成時に指定したラベル属性名のいずれかになります。
-
sourceまたはsource-ref– 文字列またはワーカーにラベル付けを要求する S3 URI。 -
labelAttributeName– 注釈後の Lambda 関数から統合されたラベルコンテンツを含むディクショナリ。注釈後の Lambda 関数が指定されていない場合、このディクショナリは空になります。 -
labelAttributeName-metadata– Ground Truth によって追加されたカスタムラベル付けジョブのメタデータ。 -
worker-response-ref– データが保存されるバケットの S3 URI。注釈後の Lambda 関数が指定されている場合、このキーと値のペアは存在しません。
この例の JSON オブジェクトは読みやすい形式になっています。実際の出力ファイルでは、JSON オブジェクトは 1 行で記述されます。
{ "source" : "This train is really late.", "labelAttributeName" : {}, "labelAttributeName-metadata": { # These key values pairs are added by Ground Truth "job_name": "test-labeling-job", "type": "groundTruth/custom", "human-annotated": "yes", "creation_date": "2021-03-08T23:06:49.111000", "worker-response-ref": "s3://amzn-s3-demo-bucket/test-labeling-job/annotations/worker-response/iteration-1/0/2021-03-08_23:06:49.json" } }
注釈後 Lambda を使用してワーカーの結果を統合する
デフォルトでは、Ground Truth は Amazon S3 で未処理のワーカーレスポンスを保存します。レスポンスの処理方法を細かく制御するには、[後注釈 Lambda 関数] を指定します。例えば、複数のワーカーが同じデータオブジェクトにラベル付けしている場合、後注釈 Lambda 関数を使用して注釈を統合できます。後注釈 Lambda 関数の作成の詳細については、「後注釈 Lambda」を参照してください。
後注釈 Lambda 関数を使用する場合は、CreateLabelingJob リクエストの AnnotationConsolidationConfig で指定する必要があります。
注釈の統合の仕組みの詳細については、「注釈統合」を参照してください。
