翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
UNLOAD の概念
構文
UNLOAD (SELECT statement) TO 's3://bucket-name/folder' WITH ( option = expression [, ...] )
ここで、 optionは です。
{ partitioned_by = ARRAY[ col_name[,…] ] | format = [ '{ CSV | PARQUET }' ] | compression = [ '{ GZIP | NONE }' ] | encryption = [ '{ SSE_KMS | SSE_S3 }' ] | kms_key = '<string>' | field_delimiter ='<character>' | escaped_by = '<character>' | include_header = ['{true, false}'] | max_file_size = '<value>' | }
パラメータ
- SELECT ステートメント
-
LiveAnalytics テーブルの 1 つ以上の Timestream からデータを選択および取得するために使用されるクエリステートメント。
(SELECT column 1, column 2, column 3 from database.table where measure_name = "ABC" and timestamp between ago (1d) and now() ) - TO 句
-
TO 's3://bucket-name/folder'or
TO 's3://access-point-alias/folder'UNLOADステートメントのTO句は、クエリ結果の出力先を指定します。Timestream for LiveAnalytics が出力ファイルオブジェクトを書き込む Amazon S3 上のフォルダの場所を持つ Amazon S3 access-point-aliasスを含むフルパスを指定する必要があります。 Amazon S3 S3 バケットは、同じ アカウントおよび同じリージョンで所有されている必要があります。クエリ結果セットに加えて、Timestream for LiveAnalytics はマニフェストファイルとメタデータファイルを指定された宛先フォルダに書き込みます。 - PARTITIONED_BY 句
-
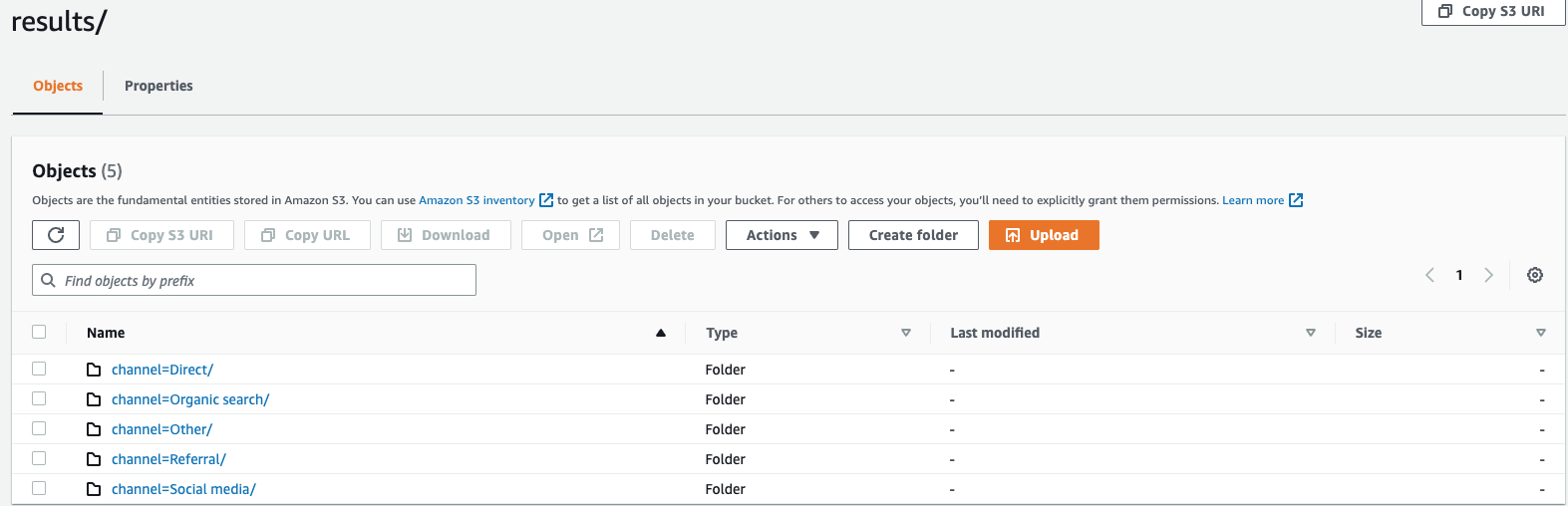
partitioned_by = ARRAY [col_name[,…] , (default: none)partitioned_by句は、データを詳細なレベルでグループ化して分析するためのクエリで使用されます。クエリ結果を S3 バケットにエクスポートする場合、SELECT クエリの 1 つ以上の列に基づいてデータをパーティション化することを選択できます。データをパーティション化する場合、エクスポートされたデータはパーティション列に基づいてサブセットに分割され、各サブセットは個別のフォルダに保存されます。エクスポートされたデータを含む結果フォルダ内に、サブフォルダfolder/results/partition column = partition value/が自動的に作成されます。ただし、パーティション化された列は出力ファイルに含まれないことに注意してください。partitioned_byは構文の必須句ではありません。パーティショニングなしでデータをエクスポートする場合は、構文で 句を除外できます。ウェブサイトのクリックストリームデータをモニタリングしていて、トラフィックのチャネルが 、
direct、、Organic Search、OtherのSocial Media5 つあるとしますReferral。データをエクスポートするときは、列 を使用してデータをパーティション化することを選択できますChannel。データフォルダ 内にはs3://bucketname/results、それぞれのチャネル名を持つフォルダが 5 つあります。例えば、このフォルダs3://bucketname/results/channel=Social Media/.内には、Social Mediaチャネルを介してウェブサイトに送信されたすべての顧客のデータがあります。同様に、残りのチャネルには他のフォルダがあります。Channel 列でパーティション分割されたエクスポートされたデータ
- FORMAT
-
format = [ '{ CSV | PARQUET }' , default: CSVS3 バケットに書き込まれるクエリ結果の形式を指定するキーワード。データは、デフォルトの区切り文字としてカンマ (,) を使用してカンマ区切り値 (CSV) としてエクスポートすることも、分析用の効率的なオープン列ストレージ形式である Apache Parquet 形式でエクスポートすることもできます。
- 圧縮
-
compression = [ '{ GZIP | NONE }' ], default: GZIPエクスポートされたデータは、圧縮アルゴリズム GZIP を使用して圧縮することも、
NONEオプションを指定して圧縮解除することもできます。 - 暗号化
-
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3Amazon S3 の出力ファイルは、選択した暗号化オプションを使用して暗号化されます。データに加えて、マニフェストファイルとメタデータファイルは、選択した暗号化オプションに基づいて暗号化されます。現在、SSE_S3 および SSE_KMS 暗号化をサポートしています。SSE_S3 は、256 ビットのアドバンスト暗号化標準 (AES) 暗号化を使用してデータを暗号化する Amazon S3 によるサーバー側の暗号化です。SSE_KMS は、カスタマーマネージドキーを使用してデータを暗号化するためのサーバー側の暗号化です。
- KMS_KEY
-
kms_key = '<string>'KMS キーは、エクスポートされたクエリ結果を暗号化するためのユーザー定義キーです。KMS キーは AWS Key Management Service (AWS KMS) によって安全に管理され、Amazon S3 のデータファイルの暗号化に使用されます。
- FIELD_DELIMITER
-
field_delimiter ='<character>' , default: (,)CSV 形式でデータをエクスポートする場合、このフィールドでは、パイプ文字 (|)、カンマ (,)、タブ (/t) など、出力ファイルのフィールドを区切るために使用される 1 つの ASCII 文字を指定します。CSV ファイルのデフォルトの区切り文字はコンマ文字です。データ内の値に選択した区切り文字が含まれている場合、区切り文字は引用符で囲まれます。たとえば、データ内の値に が含まれている場合
Time,stream、この値はエクスポートされたデータ"Time,stream"で として引用符で囲まれます。Timestream for LiveAnalytics で使用される引用文字は二重引用符 (") です。CSV にヘッダーを含める
FIELD_DELIMITER場合は、キャリッジリターン文字 (ASCII 13、16 進数0D、テキスト「\r」) または改行文字 (ASCII 10、16 進数 0A、テキスト「\n」) を として指定しないでください。これにより、結果の CSV 出力で多くのパーサーがヘッダーを正しく解析できなくなるためです。 - ESCAPED_BY
-
escaped_by = '<character>', default: (\)CSV 形式でデータをエクスポートする場合、このフィールドでは、S3 バケットに書き込まれたデータファイルでエスケープ文字として扱う文字を指定します。エスケープは、次のシナリオで発生します。
-
値自体に引用文字 (") が含まれている場合、エスケープ文字を使用してエスケープされます。例えば、値が で
Time"stream、(\) が設定されたエスケープ文字である場合、 としてエスケープされますTime\"stream。 -
値に設定されたエスケープ文字が含まれている場合、エスケープされます。例えば、値が の場合
Time\stream、 としてエスケープされますTime\\stream。
注記
エクスポートされた出力に配列、行、時系列などの複雑なデータ型が含まれている場合、JSON 文字列としてシリアル化されます。次に例を示します。
データ型 実際の値 CSV 形式で値をエスケープする方法 [シリアル化された JSON 文字列〕 配列
[ 23,24,25 ]"[23,24,25]"行
( x=23.0, y=hello )"{\"x\":23.0,\"y\":\"hello\"}"時系列
[ ( time=1970-01-01 00:00:00.000000010, value=100.0 ),( time=1970-01-01 00:00:00.000000012, value=120.0 ) ]"[{\"time\":\"1970-01-01 00:00:00.000000010Z\",\"value\":100.0},{\"time\":\"1970-01-01 00:00:00.000000012Z\",\"value\":120.0}]" -
- INCLUDE_HEADER
-
include_header = 'true' , default: 'false'CSV 形式でデータをエクスポートする場合、このフィールドでは、エクスポートされた CSV データファイルの最初の行として列名を含めることができます。
使用できる値は「true」と「false」で、デフォルト値は「false」です。
escaped_byや などのテキスト変換オプションは、ヘッダーにもfield_delimiter適用されます。注記
ヘッダーを含める場合は、キャリッジリターン文字 (ASCII 13、16 進数 0D、テキスト '\r') または改行文字 (ASCII 10、16 進数 0A、テキスト '\n') を として選択しないことが重要です。これにより
FIELD_DELIMITER、多くのパーサーが結果の CSV 出力でヘッダーを正しく解析できなくなるためです。 - MAX_FILE_SIZE
-
max_file_size = 'X[MB|GB]' , default: '78GB'このフィールドは、
UNLOADステートメントが Amazon S3 で作成するファイルの最大サイズを指定します。UNLOADステートメントは複数のファイルを作成できますが、Amazon S3 に書き込まれる各ファイルの最大サイズは、このフィールドで指定されているサイズとほぼ同じになります。フィールドの値は 16 MB から 78 GB の間でなければなりません。などの整数、
12GBまたは0.5GBや などの小数で指定できます24.7MB。デフォルト値は 78 GB です。実際のファイルサイズはファイルが書き込まれるときに概算されるため、実際の最大サイズは指定した数と完全に等しくない場合があります。
S3 バケットに書き込まれる内容
正常に実行された UNLOAD クエリごとに、Timestream for LiveAnalytics はクエリ結果、メタデータファイル、マニフェストファイルを S3 バケットに書き込みます。データをパーティション化している場合は、すべてのパーティションフォルダが結果フォルダにあります。マニフェストファイルには、UNLOAD コマンドによって書き込まれたファイルのリストが含まれています。メタデータファイルには、書き込まれたデータの特性、プロパティ、属性を記述する情報が含まれています。
エクスポートされたファイル名は何ですか?
エクスポートされたファイル名には 2 つのコンポーネントが含まれており、最初のコンポーネントは queryID、2 番目のコンポーネントは一意の識別子です。
CSV ファイル
S3://bucket_name/results/<queryid>_<UUID>.csv S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.csv
圧縮 CSV ファイル
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.gz
Parquet ファイル
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.parquet
メタデータファイルとマニフェストファイル
S3://bucket_name/<queryid>_<UUID>_manifest.json S3://bucket_name/<queryid>_<UUID>_metadata.json
CSV 形式のデータはファイルレベルで保存されるため、S3 にエクスポートするときにデータを圧縮すると、ファイルの拡張子は「.gz」になります。ただし、Parquet のデータは列レベルで圧縮されるため、エクスポート中にデータを圧縮しても、ファイルには .parquet 拡張子が付きます。
各ファイルにはどのような情報が含まれていますか?
マニフェストファイル
マニフェストファイルは、UNLOAD 実行でエクスポートされるファイルのリストに関する情報を提供します。マニフェストファイルは、 というファイル名で指定された S3 バケットで使用できますs3://<bucket_name>/<queryid>_<UUID>_manifest.json。マニフェストファイルには、結果フォルダ内のファイルの URL、各ファイルのレコード数とサイズ、およびクエリメタデータ (クエリのために S3 にエクスポートされた合計バイト数と合計行数) が含まれます。
{ "result_files": [ { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 32295, "row_count": 10 } }, { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 62295, "row_count": 20 } }, ], "query_metadata": { "content_length_in_bytes": 94590, "total_row_count": 30, "result_format": "CSV", "result_version": "Amazon Timestream version 1.0.0" }, "author": { "name": "Amazon Timestream", "manifest_file_version": "1.0" } }
メタデータ
メタデータファイルは、列名、列タイプ、スキーマなどのデータセットに関する追加情報を提供します。メタデータファイルは、ファイル名が S3://bucket_name/<queryid>_<UUID>_metadata.json の指定された S3 バケットで使用できます。
メタデータファイルの例を次に示します。
{ "ColumnInfo": [ { "Name": "hostname", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "region", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_name", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "cpu_utilization", "Type": { "TimeSeriesMeasureValueColumnInfo": { "Type": { "ScalarType": "DOUBLE" } } } } ], "Author": { "Name": "Amazon Timestream", "MetadataFileVersion": "1.0" } }
メタデータファイルで共有される列情報は、クエリのクエリ API レスポンスでColumnInfo送信されるのと同じ構造ですSELECT。
結果
結果フォルダには、エクスポートしたデータが Apache Parquet 形式または CSV 形式で含まれます。
例
UNLOAD クエリ API を使用して次のようなクエリを送信すると、
UNLOAD(SELECT user_id, ip_address, event, session_id, measure_name, time, query, quantity, product_id, channel FROM sample_clickstream.sample_shopping WHERE time BETWEEN ago(2d) AND now()) TO 's3://my_timestream_unloads/withoutpartition/' WITH ( format='CSV', compression='GZIP')
UNLOAD クエリレスポンスには 1 行 x 3 列が含まれます。これら 3 つの列は次のとおりです。
-
BIGINT 型の行 - エクスポートされた行数を示します
-
metadataFile of type VARCHAR - エクスポートされたメタデータファイルの S3 URI
-
manifestFile of type VARCHAR - エクスポートされたマニフェストファイルの S3 URI
クエリ API から次のレスポンスが返されます。
{ "Rows": [ { "Data": [ { "ScalarValue": "20" # No of rows in output across all files }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_metadata.json" #Metadata file }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_manifest.json" #Manifest file } ] } ], "ColumnInfo": [ { "Name": "rows", "Type": { "ScalarType": "BIGINT" } }, { "Name": "metadataFile", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "manifestFile", "Type": { "ScalarType": "VARCHAR" } } ], "QueryId": "AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY", "QueryStatus": { "ProgressPercentage": 100.0, "CumulativeBytesScanned": 1000, "CumulativeBytesMetered": 10000000 } }
データ型
UNLOAD ステートメントは、「」およびサポートされているデータ型「」を除く「」で説明されている LiveAnalytics のクエリ言語の Timestream time のすべてのデータ型をサポートしますunknown。
