翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
カスタム言語モデルの作成
カスタム言語モデルを作成する前に、次のことを行う必要があります。
-
データの準備 データはプレーンテキスト形式で保存し、特殊文字は使用できません。
-
データを Amazon S3 バケットにアップロードします。トレーニングデータとチューニングデータ用に別々のフォルダーを作成することをおすすめします。
-
Amazon Transcribe が Amazon S3 バケットにアクセスできることを確認します。データを使用するには、アクセス許可を持つ IAM ロールを指定する必要があります。
データの準備
すべてのデータを 1 つのファイルにコンパイルすることも、複数のファイルとして保存することもできます。チューニングデータを含める場合は、トレーニングデータとは別のファイルに保存する必要があります。
トレーニングやチューニングデータに使用するテキストファイルはいくつ使ってもかまいません。100,000 語のファイルを 1 つアップロードしても、10,000 語のファイルを 10 個アップロードするのと同じ結果になります。都合の良い方法でテキストデータを準備してください。
すべてのデータファイルが次の基準を満たしていることを確認します。
-
すべて作成したいモデルと同じ言語である必要があります。例えば、米国英語 (
en-US) の音声を書き起こすカスタム言語モデルを作成したい場合、すべてのテキストデータが米国英語である必要があります。 -
UTF-8 エンコーディングのプレーンテキスト形式です。
-
HTML タグなどの特殊文字や書式は含まれません。
-
これらのデータを合計したサイズは、トレーニングデータで最大 2 GB、チューニングデータで最大 200 MB です。
これらの基準のいずれかが満たされない場合、モデルは動作しません。
データのアップロード
データをアップロードする前に、トレーニングデータ用の新しいフォルダを作成します。チューニングデータを使用する場合は、別のフォルダーを作成します。
バケットの URI は以下のようになります。
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
トレーニングデータとチューニングデータを適切なバケットにアップロードします。
後日、これらのバケットにさらにデータを追加できます。ただし、追加した場合は、新しいデータを使用してモデルを再作成する必要があります。既存のモデルを新しいデータで更新することはできません。
データへのアクセスを許可する
カスタム言語モデルを作成するには、 Amazon S3 バケットへのアクセス許可を持つ IAM ロールを指定する必要があります。トレーニングデータを配置した Amazon S3 バケットにアクセスできるロールがまだない場合は、作成する必要があります。ロールを作成した後、ロールにアクセス許可を付与するポリシーをアタッチできます。ポリシーをユーザーにアタッチしないください。
エンドポイントポリシーの例については、「Amazon Transcribe アイデンティティベースのポリシーの例」を参照してください。
新しい IAM ID を作成する方法については、IAM 「ID (ユーザー、ユーザーグループ、ロール)」を参照してください。
キーポリシーの詳細については、以下を参照してください。
カスタム言語モデルの作成
カスタム言語モデルを作成するときは、ベースモデルを選択する必要があります。2 つのベースモデルのオプションがあります。
-
NarrowBand: サンプルレートが 16,000 Hz 未満の音声にこのオプションを使用します。このモデルタイプは、通常 8,000 Hz で録音された電話での会話に使用されます。 -
WideBand: サンプルレートが 16,000 Hz 以上の音声にこのオプションを使用します。
カスタム言語モデルは AWS Management Console、 AWS CLI、、または AWS SDKs.;以下の例を参照してください。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで [カスタム言語モデル] を選択します。カスタム言語モデル のページが開き、既存のカスタム言語モデルを表示したり、新しいカスタム言語モデルをトレーニングしたりできます。
-
新しいモデルをトレーニングするには、モデルのトレーニングを選択します。
これにより、モデルのトレーニングページに移動します。名前を追加し、言語を指定し、モデルに使用するベースモデルを選択します。次に、そのパスをトレーニングに追加し、オプションでチューニングデータも追加します。データにアクセスするためのアクセス許可を持つ IAM ロールを含める必要があります。
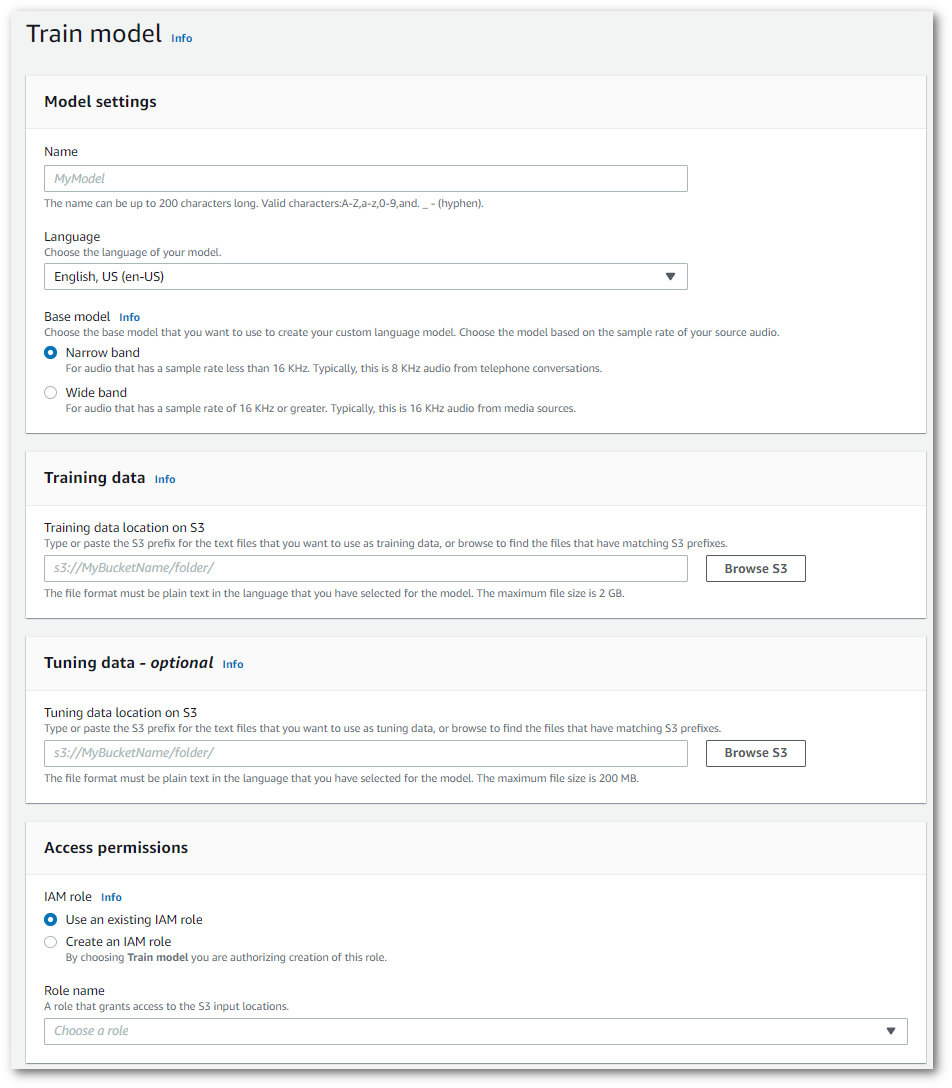
-
すべてのフィールドを完了したら、ページ下部にある [モデルのトレーニング] を選択します。
この例では、create-language-modelCreateLanguageModel」および「LanguageModel」を参照してください。
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
ここでは、create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
ファイル my-first-language-model.json には、次のリクエストボディが含まれています。
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
この例では AWS SDK for Python (Boto3) 、 を使用して create_language_model CreateLanguageModel」および「LanguageModel」を参照してください。
機能固有の例、シナリオ例、クロスサービス例など、 AWS SDKsSDK を使用した Amazon Transcribe のコード例 AWS SDKs「」の章を参照してください。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
カスタム言語モデルの更新
Amazon Transcribe は、カスタム言語モデルで使用できるベースモデルを継続的に更新します。これらの更新を活用するには、6~12 か月ごとに新しいカスタム言語モデルのトレーニングを行うことをおすすめします。
カスタム言語モデルが最新のベースモデルを使用しているかどうかを確認するには、 AWS CLI または AWS SDK を使用してDescribeLanguageModelリクエストを実行し、レスポンスで UpgradeAvailabilityフィールドを見つけます。
UpgradeAvailability が true の場合、モデルはベースモデルの最新バージョンを実行していないことになります。カスタム言語モデルで最新のベースモデルを使用するには、カスタム言語モデルを新規に作成する必要があります。カスタム言語モデルはアップグレードできません。
