翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
有害な音声検出機能の使用
バッチ文字起こしでの有害な音声の検出機能の使用
有害な音声の検出とバッチ文字起こしを組み合わせて使用する方法については、以下の例を参照してください。
-
AWS マネジメントコンソール
にサインインします。 -
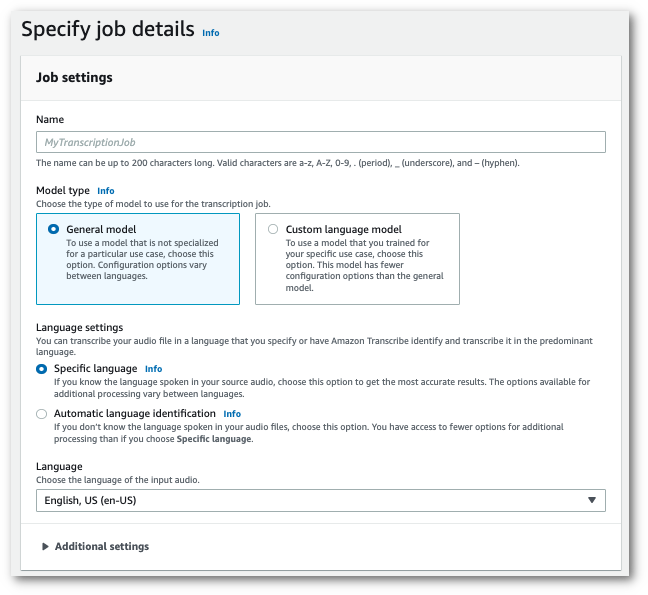
ナビゲーションペインで、[文字起こしジョブ] を選択後、[ジョブの作成] (右上) を選択します。これにより、「ジョブの詳細を指定」ページが開きます。
-
「ジョブの詳細を指定」ページでは、必要に応じて PII リダクションを有効にすることもできます。記載されている他のオプションは有害性検出には対応していません。[次へ] を選択します。これにより、ジョブの設定 - オプションページへ移動します。音声設定パネルで、[有害性検出] を選択します。
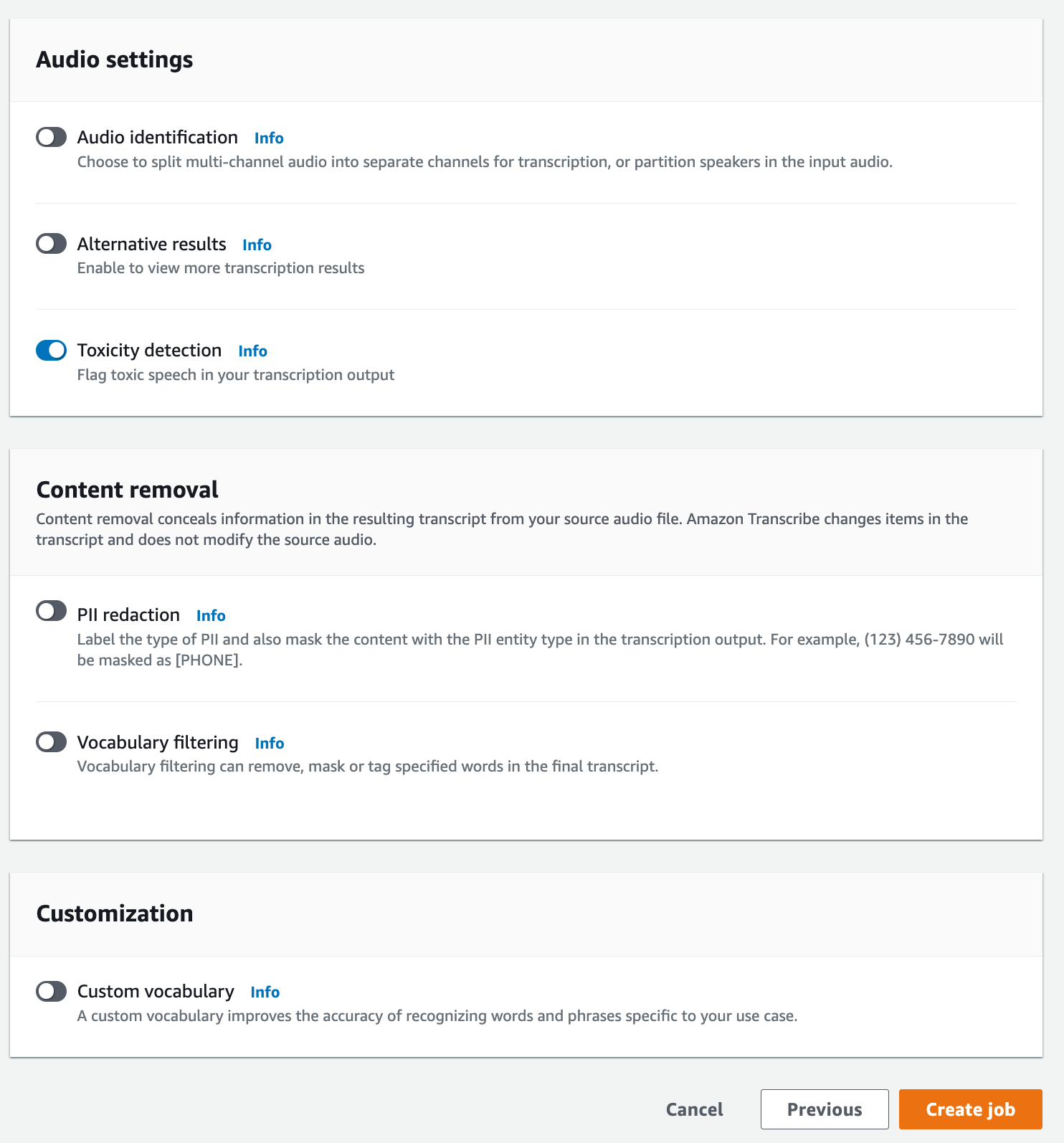
-
[ジョブの作成] を選択して、文字起こしジョブを実行します。
-
文字起こしジョブが完了すると、文字起こしジョブの詳細ページにあるダウンロードドロップダウンメニューから、トランスクリプトをダウンロードできます。
この例では、start-transcription-jobToxicityDetection パラメータを使用します。詳細については、「StartTranscriptionJob」および「ToxicityDetection」を参照してください。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/\ --language-code en-US \ --toxicity-detection ToxicityCategories=ALL
別の例として、start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-jsonfile://filepath/my-first-toxicity-job.json
ファイル my-first-toxicity-job.json には、次のリクエストボディが入含まれています。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "ToxicityDetection": [ { "ToxicityCategories": [ "ALL" ] } ] }
この例では AWS SDK for Python (Boto3) 、 を使用して start_transcription_jobToxicityDetectionの を有効にします。詳細については、「StartTranscriptionJob」および「ToxicityDetection」を参照してください。
機能固有の例、シナリオ例、クロスサービス例など、 AWS SDKsSDK を使用した Amazon Transcribe のコード例 AWS SDKs「」の章を参照してください。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', ToxicityDetection = [ { 'ToxicityCategories': ['ALL'] } ] ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
出力の例
有害な音声にはタグが付けられ、文字起こし出力で分類されます。有害な音声の各インスタンスは分類され、信頼スコア (0~1 の値) が割り当てられます。信頼値が大きいほど、コンテンツが指定されたカテゴリ内の有害な音声である可能性が高くなります。
以下は、分類された有害な音声とそれに関連する信頼スコアを示す JSON 形式の出力例です。
{ "jobName": "my-toxicity-job", "accountId": "111122223333", "results": { "transcripts": [...], "items":[...], "toxicity_detection": [ { "text": "What the * are you doing man? That's why I didn't want to play with your * . man it was a no, no I'm not calming down * man. I well I spent I spent too much * money on this game.", "toxicity": 0.7638, "categories": { "profanity": 0.9913, "hate_speech": 0.0382, "sexual": 0.0016, "insult": 0.6572, "violence_or_threat": 0.0024, "graphic": 0.0013, "harassment_or_abuse": 0.0249 }, "start_time": 8.92, "end_time": 21.45 }, Items removed for brevity { "text": "What? Who? What the * did you just say to me? What's your address? What is your * address? I will pull up right now on your * * man. Take your * back to , tired of this **.", "toxicity": 0.9816, "categories": { "profanity": 0.9865, "hate_speech": 0.9123, "sexual": 0.0037, "insult": 0.5447, "violence_or_threat": 0.5078, "graphic": 0.0037, "harassment_or_abuse": 0.0613 }, "start_time": 43.459, "end_time": 54.639 }, ] }, ... "status": "COMPLETED" }
