翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
カスタムボキャブラリーフィルターを使用する
カスタムボキャブラリーフィルターを作成したら、それを文字起こしリクエストに含めることができます。例については、次のセクションを参照してください。
リクエストに含めるカスタムボキャブラリーフィルターの言語は、メディアに指定する言語コードと一致する必要があります。言語識別を使用して複数の言語オプションを指定する場合、指定した言語ごとに 1 つのカスタム語彙フィルターを含めることができます。カスタムボキャブラリーフィルターの言語がオーディオで指定された言語と一致しない場合、フィルターはトランスクリプションに適用されず、警告やエラーもありません。
バッチトランスクリプションでのカスタムボキャブラリーフィルターの使用
バッチトランスクリプションでカスタムボキャブラリーフィルターを使用するには、次の例を参照してください。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで、次にジョブの作成を選択します。ジョブの作成(右上)を選択します。これにより、ジョブの詳細を指定 ページが開きます。
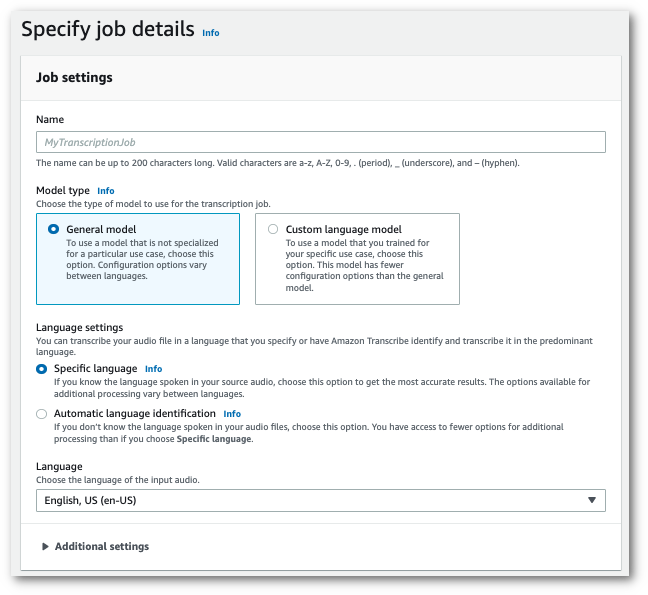
ジョブに名前を付け、入力メディアを指定します。オプションで他のフィールドを追加して、[次へ] を選択します。
-
[ジョブの設定] ページのコンテンツ削除パネルで、[語彙フィルター] をオンに切り替えます。
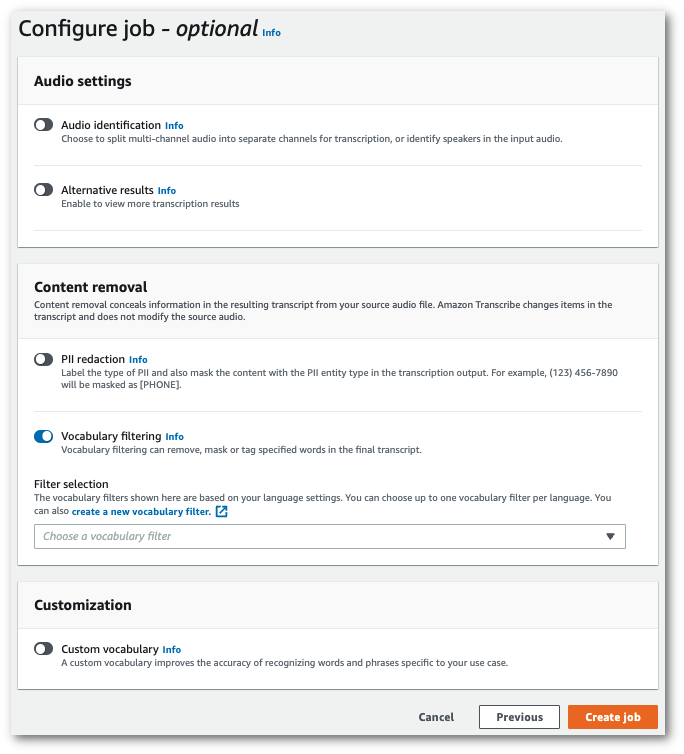
-
ドロップダウンメニューからカスタムボキャブラリーフィルターを選択し、フィルター方法を指定します。
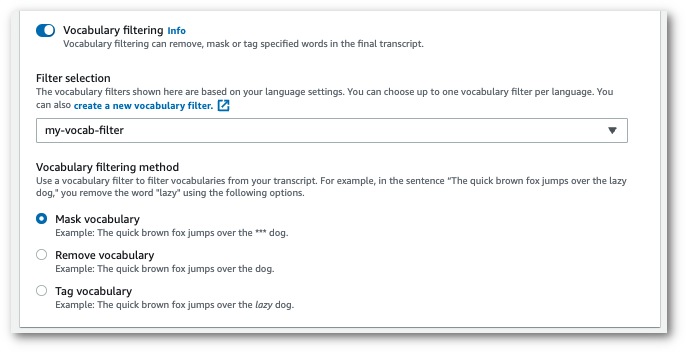
-
ジョブの作成を選択し、書き起こします。
この例では、start-transcription-jobSettingsVocabularyFilterNameVocabularyFilterMethodコマンドとパラメーターをおよびサブパラメーターと共に使用しています。詳細については、StartTranscriptionJobおよびSettingsを参照してください。
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac\ --output-bucket-nameDOC-EXAMPLE-BUCKET\ --output-keymy-output-files/ \ --language-codeen-US\ --settings VocabularyFilterName=my-first-vocabulary-filter,VocabularyFilterMethod=mask
別の例彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙 start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-vocabulary-filter-job.json
ファイル my-first-vocabulary-filter-job.json には次のリクエストボディが含まれます。
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" }, "OutputBucketName": "DOC-EXAMPLE-BUCKET", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "Settings": { "VocabularyFilterName": "my-first-vocabulary-filter", "VocabularyFilterMethod": "mask" } }
この例では、AWS SDK for Python (Boto3) transstart_transcription_jobSettings引数で、使用します。詳細については、StartTranscriptionJobおよびSettingsを参照してください。
機能固有、シナリオ、サービス間の例など、AWS SDK を使用するその他の例については、を使用した Amazon Transcribe のコード例 AWS SDKsこの章を参照してください。
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-transcription-job" job_uri = "s3://DOC-EXAMPLE-BUCKET/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'DOC-EXAMPLE-BUCKET', OutputKey = 'my-output-files/', LanguageCode = 'en-US', Settings = { 'VocabularyFilterName': 'my-first-vocabulary-filter', 'VocabularyFilterMethod': 'mask' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
ストリーミングトランスクリプションでのカスタムボキャブラリーフィルターの使用
ストリーミング文字起こしでカスタムボキャブラリーフィルターを使用するには、次の例を参照してください。
-
AWS Management Console
にサインインします。 -
ナビゲーションペインで、[リアルタイム文字起こし] を選択します。コンテンツ削除設定にスクロールして、最小化されている場合はこのフィールドを展開します。
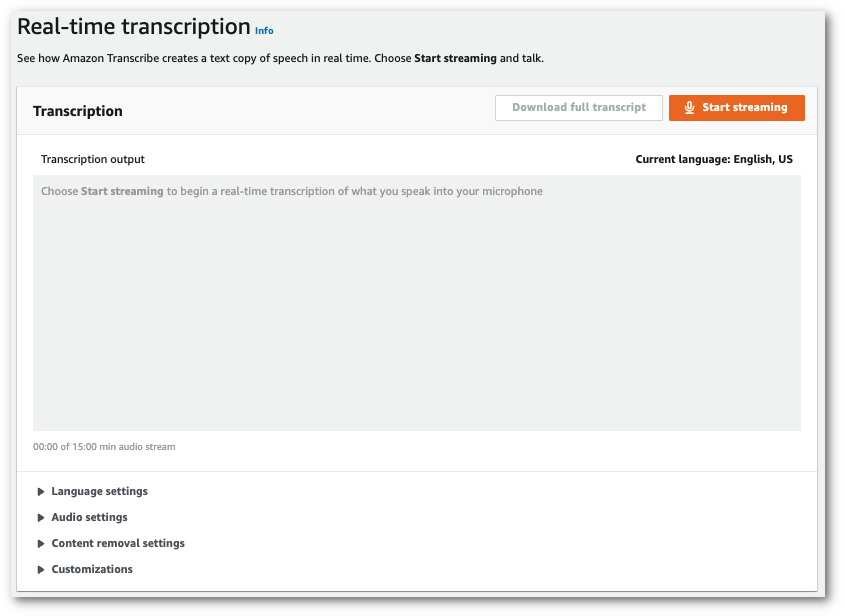
-
語彙フィルタリングをオンに切り替えます。ドロップダウンメニューからカスタムボキャブラリフィルターを選択し、フィルター方法を指定します。
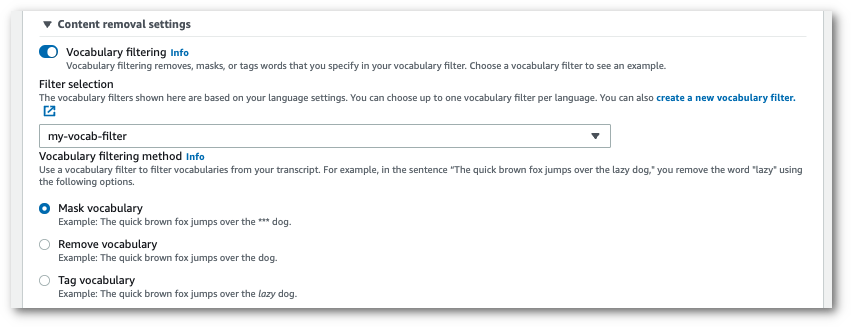
ストリームに適用するその他の設定を含めます。
-
これで、ストリームを書き起こす準備ができました。[ストリーミングを開始] を選択し、話し始めます。ディクテーションを終了するには、「ストリーミングを停止」を選択します。
この例では、カスタム語彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙彙 HTTP/2 ストリーミングを使用する際の詳細についてはAmazon Transcribe、を参照してくださいHTTP/2 ストリームのセットアップ。固有のパラメータとヘッダーの詳細についてはAmazon Transcribe、を参照してくださいStartStreamTranscription。
POST /stream-transcription HTTP/2 host: transcribestreaming.us-west-2.amazonaws.com X-Amz-Target: com.amazonaws.transcribe.Transcribe.StartStreamTranscriptionContent-Type: application/vnd.amazon.eventstream X-Amz-Content-Sha256:stringX-Amz-Date:20220208T235959Z Authorization: AWS4-HMAC-SHA256 Credential=access-key/20220208/us-west-2/transcribe/aws4_request, SignedHeaders=content-type;host;x-amz-content-sha256;x-amz-date;x-amz-target;x-amz-security-token, Signature=stringx-amzn-transcribe-language-code:en-USx-amzn-transcribe-media-encoding:flacx-amzn-transcribe-sample-rate:16000x-amzn-transcribe-vocabulary-filter-name:my-first-vocabulary-filterx-amzn-transcribe-vocabulary-filter-method:masktransfer-encoding: chunked
パラメータの定義は API リファレンスにあります。すべてのAWS API オペレーションに共通するパラメータは、「共通パラメータ」セクションに記載されています。
この例では、 WebSocket カスタムボキャブラリフィルターをストリームに適用する署名付き URL を作成します。読みやすくするために、改行が追加されています。 WebSocket でのストリームの使用の詳細についてはAmazon Transcribe、を参照してください WebSocket ストリームのセットアップ。パラメータの詳細については、「StartStreamTranscription」を参照してください。
GET wss://transcribestreaming.us-west-2.amazonaws.com:8443/stream-transcription-websocket? &X-Amz-Algorithm=AWS4-HMAC-SHA256 &X-Amz-Credential=AKIAIOSFODNN7EXAMPLE%2F20220208%2Fus-west-2%2Ftranscribe%2Faws4_request &X-Amz-Date=20220208T235959Z &X-Amz-Expires=300&X-Amz-Security-Token=security-token&X-Amz-Signature=string&X-Amz-SignedHeaders=content-type%3Bhost%3Bx-amz-date &language-code=en-US&media-encoding=flac&sample-rate=16000&vocabulary-filter-name=my-first-vocabulary-filter&vocabulary-filter-method=mask
パラメータの定義は API リファレンスにあります。すべてのAWS API オペレーションに共通するパラメータは、「共通パラメータ」セクションに記載されています。
