分散システムの可用性
分散システムは、ソフトウェアコンポーネントとハードウェアコンポーネントの両方で構成されています。一部のソフトウェアコンポーネントは、それ自体が別の分散システムである可能性があります。基盤となるハードウェアコンポーネントとソフトウェアコンポーネントの両方の可能性は、結果として得られるワークロードの可用性に影響します。
MTBF と MTTR を使った可用性の計算は、ハードウェアシステムが基礎になっています。ただし、分散システムの障害の原因は、ハードウェアの一部で発生する障害の原因とは大きく異なります。メーカーがハードウェアコンポーネントが摩耗するまでの平均時間を一貫して計算できる場合、同じテストを分散システムのソフトウェアコンポーネントに適用することはできません。通常、ハードウェアは障害率の「バスタブ」曲線を描き、ソフトウェアは新しいリリースごとに追加される不具合によって時差曲線を描きます (「ソフトウェアの信頼性
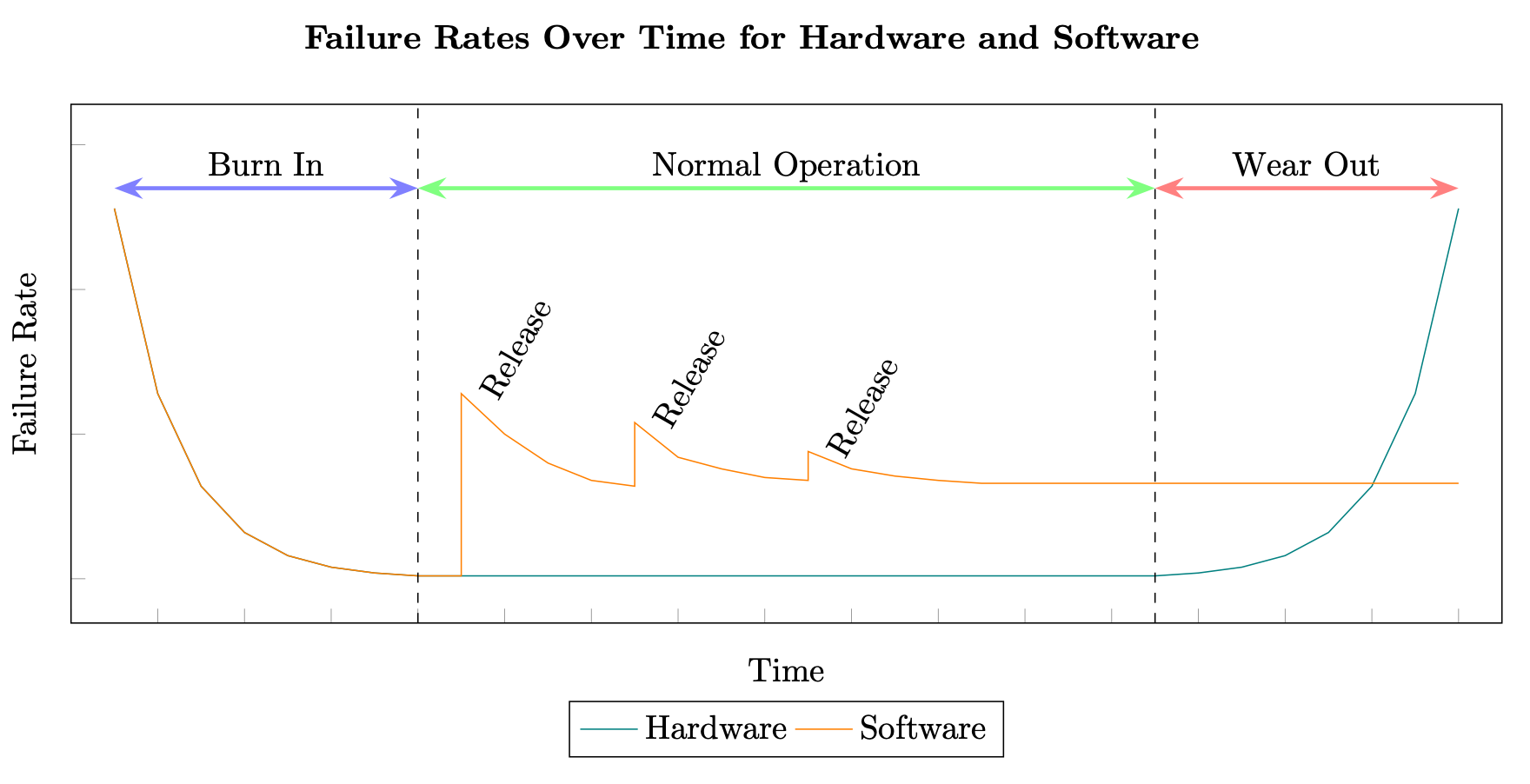
ハードウェアとソフトウェアの障害率
さらに、分散システムのソフトウェアは通常、ハードウェアよりも指数関数的に高い速度で変化します。例えば、標準的な磁気ハードドライブの年間平均故障率 (AFR) は 0.93% で、実際には HDD の場合、摩耗期に達するまでに少なくとも 3 ~ 5 年の寿命があり、それよりも長い可能性があります (2020 年 Backblaze社のハードドライブのデータと統計
ハードウェアには「計画的陳腐化」という概念もあります。つまり、ハードウェアには寿命が組み込まれているため、一定期間が経過すると交換する必要があります。(「Great Lightbulb Conspiracy
つまり、MTBF や MTTR の数値を取得するためにハードウェアで使用されるテストモデルや予測モデルは、ソフトウェアには適用されないということです。1970 年代以降、この問題を解決するためのモデル構築が何百回も試みられてきましたが、それらはすべて、一般的に予測モデリングと推定モデリングの 2 つのカテゴリに分類されます。(ソフトウェア信頼性モデルのリスト
したがって、分散システムの前向きな MTBF と MTTR の計算、つまり前向きな可用性の計算は、必ず何らかの予測または予測から導き出されます。これらは予測モデリング、確率的シミュレーション、履歴分析、または厳密なテストによって生成される場合がありますが、これらの計算によって稼働時間やダウンタイムが保証されるわけではありません。
過去に分散システムに障害が発生した理由は 2 度と発生しない可能性があります。将来的に発生する障害の理由は異なる可能性が高く、おそらくは不明です。また、将来の障害に備えて必要な回復メカニズムは、過去に使用されていたものとは異なり、かかる時間も大きく異なる場合があります。
また、MTBF と MTTR は平均値です。平均値と実際に表示される値には多少の差異があります (標準偏差 σ はこの変動を測定します)。したがって、実際の運用環境では、ワークロードの障害から回復までの時間が短くなったり長くなる可能性があります。
とは言え、分散システムを構成するソフトウェアコンポーネントの可用性は依然として重要です。ソフトウェアはさまざまな理由で障害を起こす可能性があり (次のセクションで詳しく説明します)、ワークロードの可用性に影響を与えます。したがって、可用性の高い分散システムでは、ハードウェアおよび外部ソフトウェアサブシステムと同様に、ソフトウェアコンポーネントの可用性の計算、測定、および向上に重点を置く必要があります。
ルール 2
ワークロード内のソフトウェアの可用性は、ワークロード全体の可用性にとって重要な要素であり、他のコンポーネントと同様に重視する必要があります。
MTBF と MTTR は分散システムでは予測が難しいものの、それでも可用性を向上させるための重要な分析情報が得られることに注意する必要があります。障害の頻度を減らす (MTBF を高くする) ことと、障害発生後の回復までの時間を短くする (MTTR を短くする) ことの両方が、経験的な可用性の向上につながります。
分散システムにおける障害の種類
分散システムで一般的に可用性に影響するバグには、ボーアバグとハイゼンバグ (「A Conversation with Bruce Lindsay」ACM Queue vol. 2、no. 8 – November 2004
ボーアバグは、繰り返し発生するソフトウェアの問題です。同じ入力が与えられると、バグは常に同じ誤った出力を生成します (決定論的なボーアの原子模型のように、確実かつ簡単に検出できます)。この種のバグが発生するのは、ワークロードが本番環境に移行する頃までは稀です。
ハイゼンバグは一時的なバグです。つまり、特定の稀な状況でのみ発生するバグです。これらの条件は通常、ハードウェア (例えば、一時的なデバイス障害やレジスタサイズなどのハードウェア実装の仕様)、コンパイラの最適化と言語の実装、制限条件 (例えば、一時的にストレージが不足している)、競合条件 (例えば、マルチスレッドオペレーションにセマフォを使用しない) などに関連しています。
ハイゼンバグは本番環境のバグの大部分を占めており、見つけにくく、観察やデバッグを試みると動作が変わったり、消失するように見えるため、見つけるのが困難です。ただし、プログラムを再起動すると、動作環境が若干異なり、ハイゼンバグの原因となった状況が解消されるため、失敗した動作が成功する可能性があります。
したがって、本番環境でのほとんどの障害は一時的なものであり、動作を再試行しても再び障害が発生する可能性はほとんどありません。回復力を高めるには、分散システムがハイゼンバグに対する耐障害性を備えている必要があります。これを実現する方法については、「分散システムの MTBF の増加」のセクションで説明します。
