서비스 세부 정보 페이지에서 자세한 서비스 활동 및 운영 상태 확인
애플리케이션을 계측할 때 Amazon CloudWatch Application Signals는 애플리케이션이 검색하는 모든 서비스를 매핑합니다. 서비스 세부 정보 페이지를 사용하여 단일 서비스에 대한 서비스 개요, 작업, 종속성, canary 및 클라이언트 요청을 확인합니다. 이러한 서비스 세부 정보 페이지를 보려면 다음을 수행합니다.
-
CloudWatch 콘솔
을 엽니다. -
왼쪽 탐색 창의 Application Signals 섹션에서 서비스를 선택합니다.
-
서비스, 상위 서비스 또는 종속성 테이블에서 서비스 이름을 선택합니다.
일정-방문 아래에는 서비스 이름 아래에 계정 레이블과 ID가 표시됩니다.
서비스 세부 정보 페이지는 다음 탭으로 구성되어 있습니다.
-
개요 - 이 탭을 사용하여 작업, 종속성, Synthetics 및 클라이언트 페이지 수를 비롯한 단일 서비스 개요를 확인합니다. 탭에는 전체 서비스, 상위 작업 및 종속성에 대한 주요 지표가 표시됩니다. 이러한 지표로, 해당 서비스의 모든 서비스 작업 전반에 걸친 지연 시간, 장애 및 오류에 대한 시계열 데이터가 포함됩니다.
-
서비스 작업 - 이 탭을 사용하여 서비스에서 직접 호출하는 작업 목록과 각 작업 상태를 측정하는 주요 지표가 포함된 대화형 그래프를 확인합니다. 그래프에서 데이터 포인트를 선택하여 해당 데이터 포인트와 연결된 트레이스, 로그 또는 지표에 대한 정보를 얻을 수 있습니다.
-
종속성 - 이 탭을 사용하여 서비스에서 직접 호출하는 종속성 목록과 종속성 지표 목록을 확인합니다.
-
Synthetics Canary - 이 탭을 사용하여 서비스에 대한 사용자 직접 호출을 시뮬레이션하는 Synthetics canary 목록과 해당 canary의 작동 방식에 대한 주요 성능 지표를 확인합니다.
-
클라이언트 페이지 - 이 탭을 사용하여 서비스를 직접 호출하는 클라이언트 페이지 목록 및 애플리케이션과 클라이언트의 상호 작용 품질을 측정하는 지표를 확인합니다.
-
관련 지표 - 이 탭을 사용하여 표준 지표, 런타임 지표, 서비스에 대한 사용자 지정 지표, 해당 작업 또는 종속성과 같은 관련 지표를 연관시킵니다.
서비스 개요 보기
서비스 개요 페이지를 사용하여 단일 위치에서 모든 서비스 작업에 대한 개요 수준의 지표 요약을 확인합니다. 애플리케이션과 상호 작용하는 모든 작업, 종속성, 클라이언트 페이지 및 Synthetics canary의 성능을 확인합니다. 이 정보를 사용하면 문제를 식별하고, 오류를 해결하며, 최적화 기회를 찾기 위해 집중할 부분을 결정하는 데 도움이 됩니다.
서비스 세부 정보의 링크를 선택하면 특정 서비스와 관련된 정보를 확인합니다. 예를 들어 Amazon EKS에 호스팅되는 서비스의 경우 서비스 세부 정보 페이지에 클러스터, 네임스페이스 및 워크로드 정보가 표시됩니다. Amazon ECS 또는 Amazon EC2에 호스팅되는 서비스의 경우 서비스 세부 정보 페이지에 환경 값이 표시됩니다.
서비스에서 개요 탭에는 다음이 요약되어 표시됩니다.
-
작업 - 이 탭을 사용하여 서비스 작업 상태를 확인합니다. 서비스 수준 목표(SLO)의 일부로 정의된 서비스 수준 지표(SLI)로 상태가 결정됩니다.
-
종속성 - 이 탭을 사용하여 애플리케이션에서 호출하는 서비스의 상위 종속성(장애 발생률로 나열됨) 및 서비스 종속성의 상태를 확인합니다. 서비스 수준 목표(SLO)의 일부로 정의된 서비스 수준 지표(SLI)로 상태가 결정됩니다.
-
Synthetics Canary - 이 탭을 사용하여 서비스와 연결된 엔드포인트 또는 API에 대한 시뮬레이션 직접 호출 결과와 실패한 canary 수를 확인합니다.
-
클라이언트 페이지 - 이 탭을 사용하여 비동기 JavaScript 및 XML(AJAX) 오류가 있는 클라이언트가 직접 호출한 상위 페이지를 확인합니다.
다음 그림은 서비스의 개요를 보여줍니다.

또한 개요 탭에는 모든 서비스에서 지연 시간이 가장 긴 종속성 그래프도 표시됩니다. 다음과 같이 p99, p90, p50 지연 시간 지표를 사용하여 총 서비스 지연 시간에 영향을 미치는 종속성을 신속하게 평가할 수 있습니다.

예를 들어, 이전 그래프는 고객-서비스 종속성에 대한 요청의 99%가 약 4,950밀리초 만에 완료되었음을 보여줍니다. 다른 종속성은 그보다 시간이 더 적게 걸렸습니다.
지연 시간별로 상위 4개 서비스 작업을 표시하는 그래프는 다음 이미지와 같이 해당 서비스에 대한 요청량, 가용성, 결함율 및 오류율을 보여줍니다.
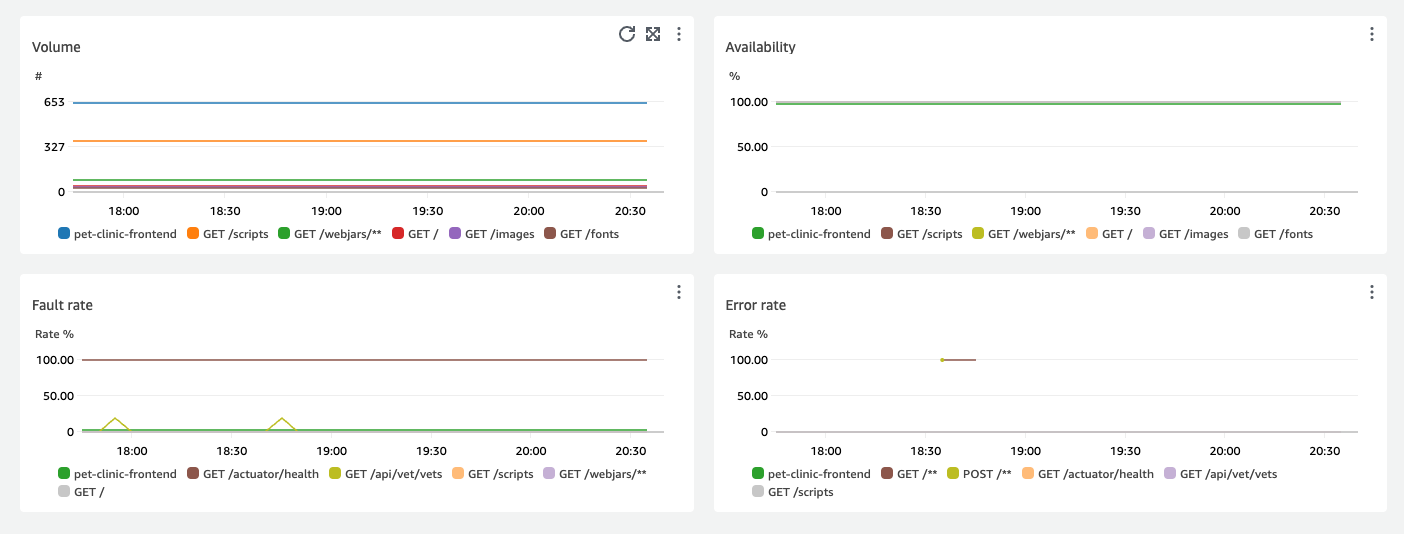
서비스 세부 정보 단원에는 계정 ID 및 계정 레이블을 포함한 서비스 세부 정보가 표시됩니다.
서비스 작업 보기
애플리케이션을 계측할 때 Application Signals는 애플리케이션이 직접 호출하는 모든 서비스 작업을 검색합니다. 서비스 작업 탭을 사용하여 서비스 작업과 선택한 작업의 성능을 측정하는 지표 집합이 포함된 테이블을 확인합니다. 이러한 지표로는 다음 이미지와 같이 SLI 상태, 종속성 수, 지연 시간, 볼륨, 장애, 오류 및 가용성이 포함됩니다.
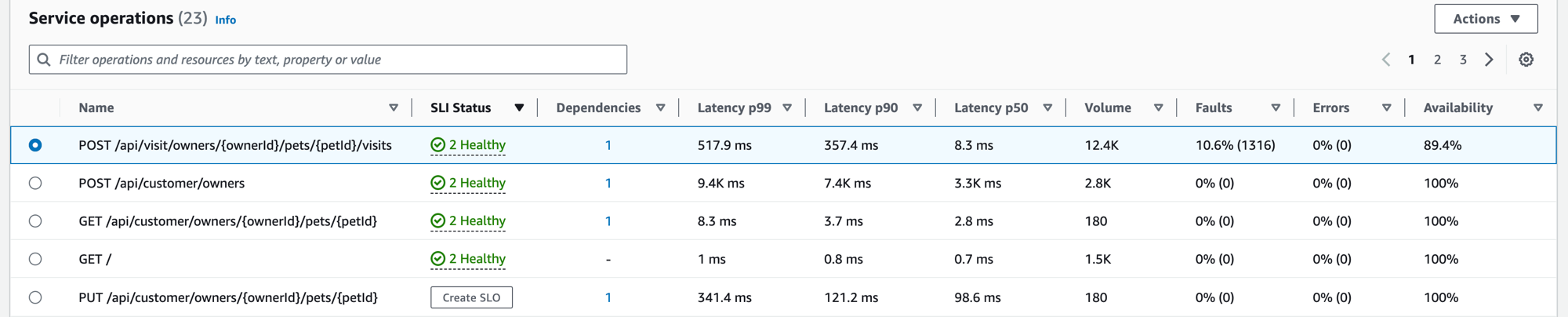
테이블을 필터링하여 필터 텍스트 상자에서 하나 이상의 속성을 선택해 서비스 작업을 더 쉽게 찾을 수 있습니다. 각 속성을 선택하면 필터 기준이 안내되며 필터 텍스트 상자 아래에 전체 필터가 표시됩니다. 언제든지 필터 지우기를 선택하여 테이블 필터를 제거할 수 있습니다.
다음 테이블과 같이 작업의 SLI 상태를 선택하여 비정상 SLI에 대한 링크와 해당 작업에 대한 모든 SLO를 볼 수 있는 링크가 포함된 팝업을 표시합니다.
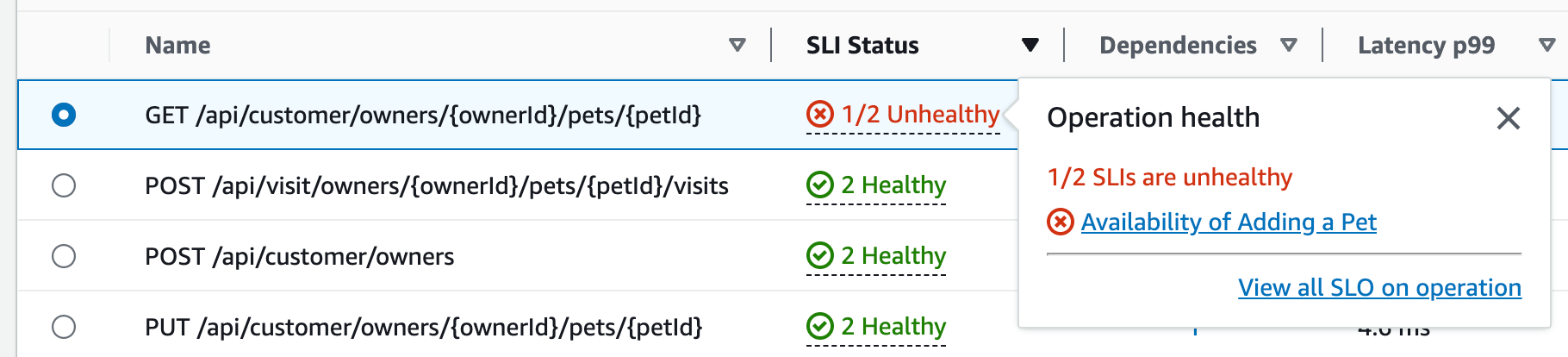
서비스 작업 테이블에는 SLI 상태, 정상 또는 비정상 SLI 수, 각 작업에 대한 총 SLO 수가 나열됩니다.
SLI를 사용하여 지연 시간, 가용성 및 서비스의 작업 상태를 측정하는 기타 작업 지표를 모니터링합니다. SLO를 사용하여 서비스 및 작업의 성능과 상태를 확인합니다.
SLO를 생성하려면 다음을 수행합니다.
-
작업에 SLO가 없는 경우 SLI 상태 열에서 SLO 생성 버튼을 선택합니다.
-
작업에 이미 SLO가 있는 경우 다음을 수행합니다.
-
작업 이름 옆의 라디오 버튼을 선택합니다.
-
테이블 오른쪽 상단의 작업 아래쪽 화살표에서 SLO 생성을 선택합니다.
-
자세한 내용은 서비스 수준 목표(SLO)를 참조하세요.
종속성 열에는 이 작업에서 직접적으로 호출하는 종속성 수가 표시됩니다. 이 숫자를 선택하여 선택한 작업으로 필터링된 종속성 탭을 엽니다.
서비스 작업 지표, 상관관계가 있는 트레이스 및 애플리케이션 로그 보기
Application Signals는 서비스 작업 지표를 AWS X-Ray 트레이스, CloudWatch Container Insights 및 애플리케이션 로그와 상관시킵니다. 이러한 지표를 사용하여 작업 상태 문제를 해결합니다. 지표를 그래픽 정보로 보려면 다음을 수행합니다.
-
서비스 작업 테이블에서 서비스 작업을 선택하여 테이블 위에서 볼륨 및 가용성, 지연 시간 및 장애 및 오류에 대한 지표가 포함된 선택한 작업 그래프 세트를 확인합니다.
-
그래프의 한 지점을 가리키면 추가 정보가 표시됩니다.
-
점을 선택하여 그래프에서 선택한 지점의 상관관계가 있는 트레이스, 지표 및 애플리케이션 로그를 보여주는 진단 창이 열립니다.
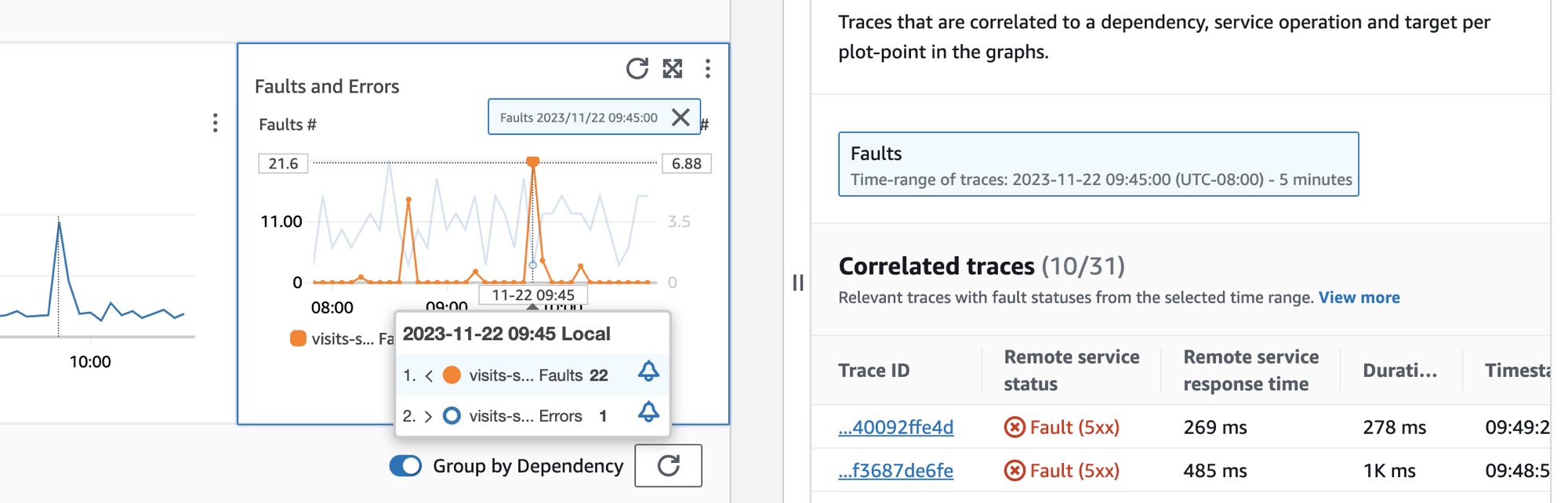
다음 이미지는 그래프에서 특정 지점을 가리키면 표시되는 도구 설명과 지점을 클릭하면 표시되는 진단 창을 보여줍니다. 도구 설명에는 결함 및 오류 그래프의 관련 데이터 요소에 관한 정보가 포함되어 있습니다. 창에는 선택한 지점과 관련된 상관관계가 있는 트레이스, 상위 기여자, 애플리케이션 로그가 포함되어 있습니다.
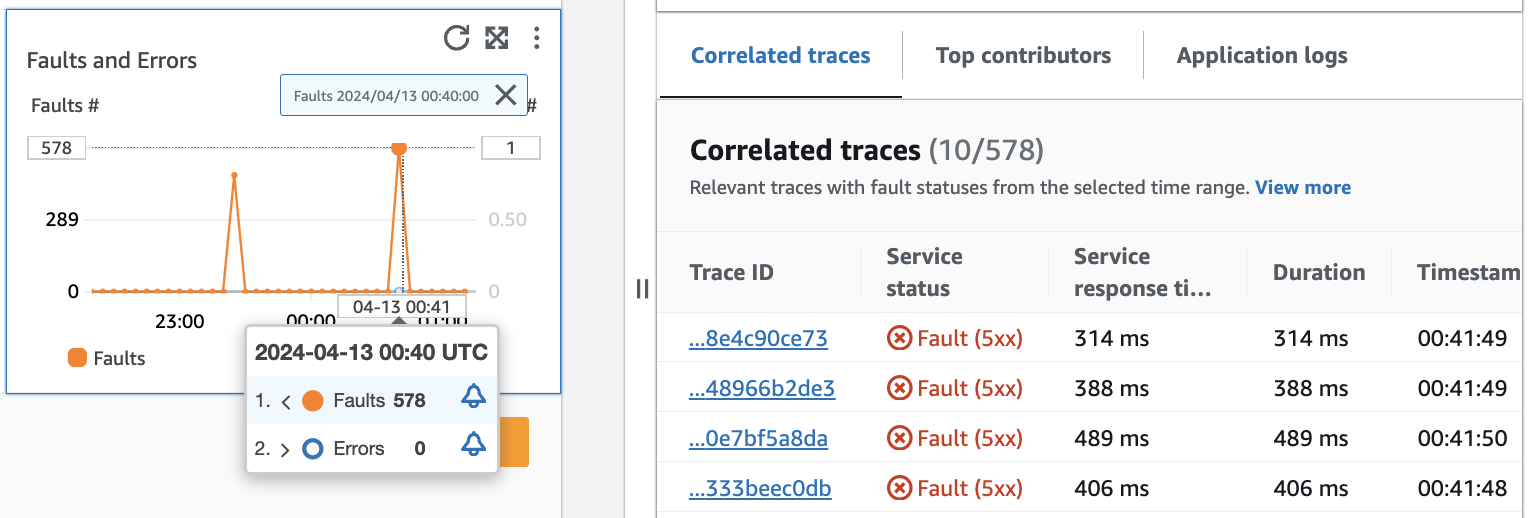
상관관계가 있는 트레이스
관련 트레이스를 살펴보고 트레이스와 관련된 근본적인 문제를 이해합니다. 상관관계가 있는 트레이스 또는 해당 트레이스와 연결된 모든 서비스 노드가 비슷하게 동작하는지 확인할 수 있습니다. 상관관계가 있는 트레이스를 검사하려면 상관관계가 있는 트레이스 테이블에서 트레이스 ID를 선택하고 선택한 트레이스의 X-Ray 트레이스 세부 정보 페이지를 엽니다. 트레이스 세부 정보 페이지에는 선택한 트레이스와 관련된 서비스 노드 맵과 트레이스 세그먼트의 타임라인이 포함되어 있습니다.
상위 기여자
지표에 대한 주요 입력 소스를 찾으려면 상위 기여자를 확인합니다. 기여자를 여러 구성 요소별로 그룹화하여 그룹 내 유사점을 찾고 트레이스 동작이 해당 그룹 사이에서 어떻게 다른지 파악합니다.
상위 기여자 탭에는 각 그룹의 직접 호출 볼륨, 가용성, 평균 지연 시간, 오류, 장애 지표가 제공됩니다. 다음 이미지 예제에서는 Amazon EKS 플랫폼에 배포된 애플리케이션의 지표 모음에 기여한 상위 기여자를 보여줍니다.
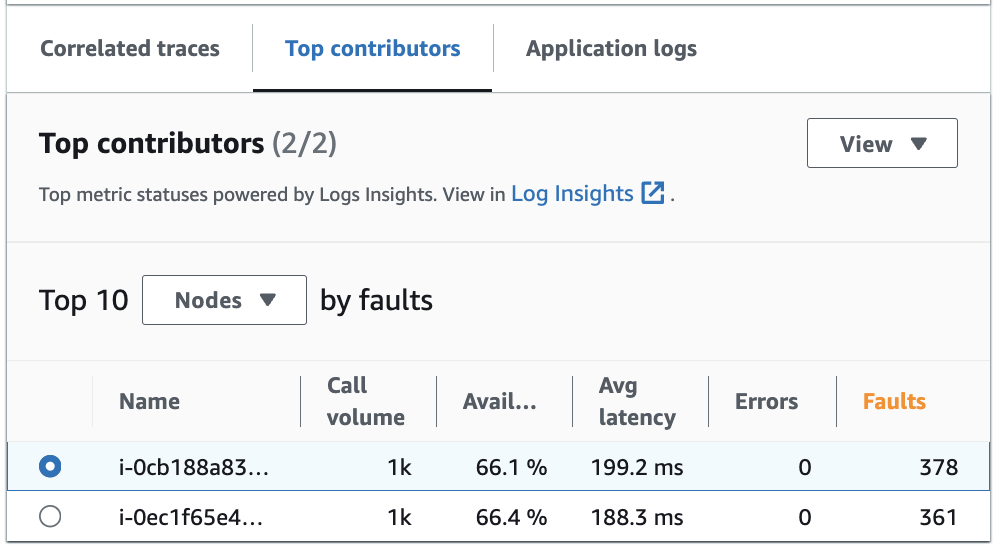
상위 기여자에는 다음 지표가 포함됩니다.
-
직접 호출 볼륨 - 직접 호출 볼륨을 사용하여 일정 기간 그룹에 대한 요청 수를 이해합니다.
-
가용성 - 가용성을 사용하여 그룹에서 장애가 감지되지 않은 시간의 비율을 확인합니다.
-
평균 지연 시간 - 지연 시간을 사용하여 조사 중인 요청이 이루어진 후 경과된 시간에 따라 일정 기간 그룹에 대해 요청이 실행된 평균 시간을 확인합니다. 15일 이내 이전에 이루어진 요청은 1분 간격으로 평가됩니다. 15~30일 이전에 이루어진 요청은 5분 간격으로 평가됩니다. 예를 들어 15일 전에 결함을 일으킨 요청을 조사하는 경우 호출량 지표는 5분 간격당 요청 수와 동일합니다.
-
오류 - 일정 기간 측정된 그룹당 오류 수.
-
장애 - 일정 기간 그룹당 결함 수.
Amazon EKS 또는 Kubernetes를 사용하는 상위 기여자
Amazon EKS 또는 Kubernetes에 배포된 애플리케이션의 경우 상위 기여자에 대한 정보를 사용하여 Node, Pod 및 PodTemplateHash로 그룹화된 작업 상태 지표를 확인합니다. 다음 정의가 적용됩니다.
-
포드는 스토리지와 리소스를 공유하는 하나 이상의 Docker 컨테이너 그룹입니다. 포드는 Kubernetes 플랫폼에 배포할 수 있는 가장 작은 단위입니다. 포드별로 그룹화하여 오류가 포드별 제한과 관련이 있는지 확인하세요.
-
노드는 포드를 실행하는 서버입니다. 노드별로 그룹화하여 오류가 노드별 제한과 관련이 있는지 확인하세요.
-
포드 템플릿 해시는 배포의 특정 버전을 찾는 데 사용됩니다. 포드 템플릿 해시별로 그룹화하여 오류가 특정 배포와 관련이 있는지 확인하세요.
Amazon EC2를 사용하는 상위 기여자
Amazon EKS에 배포된 애플리케이션의 경우 상위 기여자에 대한 정보를 사용하여 인스턴스 ID 및 Auto Scaling 그룹으로 그룹화된 작업 상태 지표를 확인합니다. 다음 정의가 적용됩니다.
-
인스턴스 ID는 서비스가 실행하는 Amazon EC2 인스턴스의 고유 식별자입니다. 인스턴스 ID별로 그룹화하여 오류가 특정 Amazon EC2 인스턴스와 관련이 있는지 확인합니다.
-
Auto Scaling 그룹은 애플리케이션 요청을 처리하는 데 필요한 리소스를 확장 또는 축소할 수 있는 Amazon EC2 인스턴스의 컬렉션입니다. 오류가 그룹 내 인스턴스로 범위가 제한되어 있는지 확인하려면 Auto Scaling 그룹으로 그룹화합니다.
사용자 지정 플랫폼을 사용하는 상위 기여자
사용자 지정 계측을 사용하여 배포된 애플리케이션의 경우 상위 기여자에 대한 정보를 사용하여 호스트 이름으로 그룹화된 작업 상태 지표를 확인합니다. 다음 정의가 적용됩니다.
-
호스트 이름은 네트워크에 연결된 엔드포인트 또는 Amazon EC2 인스턴스와 같은 디바이스를 식별합니다. 호스트 이름으로 그룹화하여 오류가 특정 물리적 또는 가상 디바이스와 관련이 있는지 확인합니다.
Log Insights 및 Container Insights에서 상위 기여자 보기
Log Insights에서 상위 기여자에 대한 지표를 생성하는 자동 쿼리를 보고 수정합니다. Container Insights에서 포드 또는 노드와 같은 특정 그룹별로 인프라 성능 지표를 봅니다. 리소스 사용량을 기준으로 클러스터, 노드 또는 워크로드를 정렬하고 최종 사용자 환경이 영향을 받기 전에 이상 현상을 신속하게 식별하거나 위험을 사전에 완화할 수 있습니다. 다음 이미지는 이러한 옵션을 선택하는 방법을 보여줍니다.
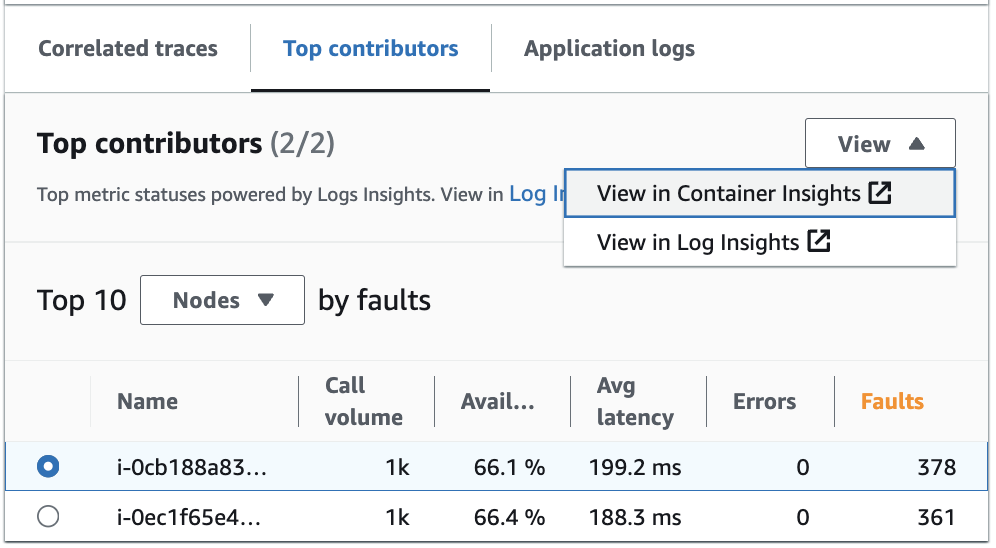
Container Insights에서는 Amazon EKS 또는 Amazon ECS 컨테이너에 대한 상위 기여자 그룹별 지표를 볼 수 있습니다. 예를 들어, 상위 기여자를 생성하기 위해 EKS 컨테이너를 포드별로 그룹화한 경우 Container Insights는 해당 포드에 대해 필터링된 지표와 통계를 보여줍니다.
Log Insights에서 다음 단계를 사용하여 상위 기여자 아래에서 지표를 생성하는 쿼리를 수정할 수 있습니다.
-
Log Insights에서 보기를 선택합니다. 열리는 Logs Insights 페이지에는 자동으로 생성되는 쿼리가 포함되어 있으며 다음 정보가 포함되어 있습니다.
-
로그 클러스터 그룹 이름.
-
CloudWatch를 사용하여 조사하고 있던 작업.
-
그래프에서 상호 작용한 작업 상태 지표의 집계.
로그 결과는 서비스 그래프에서 데이터 포인트를 선택하기 전 마지막 5분 동안의 데이터를 표시하도록 자동 필터링됩니다.
-
-
쿼리를 편집하려면 생성된 텍스트를 변경하는 내용으로 바꿉니다. 쿼리 생성기를 사용하여 새 쿼리를 생성하거나 기존 쿼리를 업데이트할 수도 있습니다.
애플리케이션 로그
애플리케이션 로그 탭의 쿼리를 사용하여 현재 로그 그룹 및 서비스에 대해 기록된 정보를 생성하고 타임스탬프를 삽입합니다. 로그 그룹은 애플리케이션을 구성할 때 정의할 수 있는 로그 스트림의 그룹입니다.
로그 그룹을 사용하여 다음을 비롯한 유사한 특성의 로그를 구성합니다.
-
특정 조직, 소스 또는 기능에서 로그를 캡처합니다.
-
특정 사용자가 액세스하는 로그를 캡처합니다.
-
특정 시간 동안 로그를 캡처합니다.
이러한 로그 스트림을 사용하여 특정 그룹 또는 기간을 추적합니다. 또한 이러한 로그 그룹에 대한 모니터링 규칙, 경보 및 알림을 설정할 수 있습니다. 로그 그룹에 대한 자세한 내용은 로그 그룹 및 로그 스트림 작업을 참조하세요.
애플리케이션 로그 쿼리는 로그, 반복 텍스트 패턴 및 로그 그룹에 대한 그래픽 시각화를 반환합니다.
쿼리를 실행하려면 Logs Insights에서 쿼리 실행을 선택하여 자동 생성된 쿼리를 실행하거나 쿼리를 수정합니다. 쿼리를 편집하려면 자동 생성된 텍스트를 변경 내용으로 바꿉니다. 쿼리 생성기를 사용하여 새 쿼리를 생성하거나 기존 쿼리를 업데이트할 수도 있습니다.
다음 이미지는 서비스 작업 그래프에서 선택한 지점을 기반으로 자동 생성되는 샘플 쿼리를 보여줍니다.
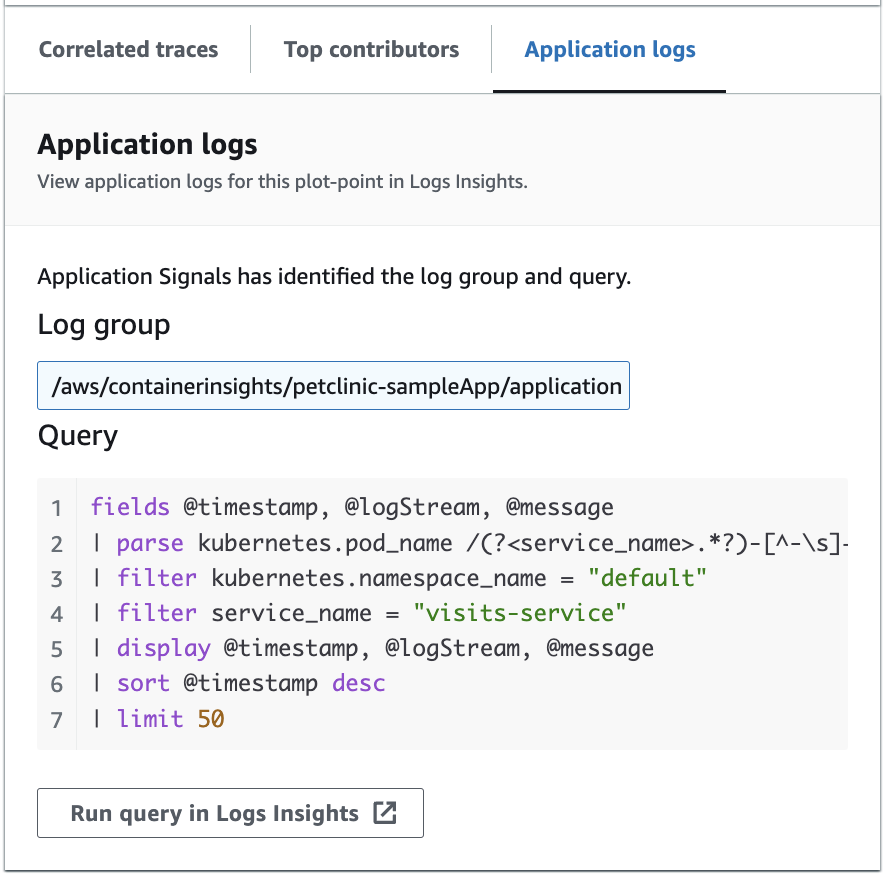
위 이미지에서 CloudWatch는 선택한 지점과 관련된 로그 그룹을 자동으로 감지하고, 이를 생성된 쿼리에 포함시켰습니다.
서비스 종속성 보기
종속성 테이블과 모든 서비스 작업 또는 단일 작업의 종속성에 대한 지표 세트를 표시하려면 종속성 탭을 선택합니다. 이 테이블에는 SLI 상태, 지연 시간, 호출 볼륨, 장애 발생률, 오류율 및 가용성에 대한 지표를 포함하여 Application Signals에서 검색한 종속성 목록이 포함되어 있습니다.
페이지 상단의 아래쪽 화살표에서 작업을 선택하여 해당 종속성을 보거나 모두를 선택하여 모든 작업에 대한 종속성을 확인합니다.
필터 텍스트 상자에서 하나 이상의 속성을 선택하여 원하는 항목을 더 쉽게 찾을 수 있도록 테이블을 필터링합니다. 각 속성을 선택하면 필터 기준이 안내되며 필터 텍스트 상자 아래에 전체 필터가 표시됩니다. 언제든지 필터 지우기를 선택하여 테이블 필터를 제거할 수 있습니다. 테이블의 오른쪽 상단에서 종속성별 그룹화를 선택하여 서비스 및 작업 이름별로 종속성을 그룹화합니다. 그룹화가 켜져 있는 경우 종속성 이름 옆에 있는 + 아이콘을 사용하여 종속성 그룹을 확장하거나 축소합니다.

종속성 열에는 종속성 서비스 이름이 표시되고, 원격 작업 열에는 서비스 작업 이름이 표시됩니다. SLI 상태 열에는 각 종속성에 대한 총 SLI 수와 함께 정상 또는 비정상 SLI 수가 표시됩니다. AWS 서비스를 호출할 때 대상 열에는 DynamoDB 테이블 또는 Amazon SNS 대기열과 같은 AWS 리소스가 표시됩니다.
종속성을 선택하려면 종속성 테이블에서 종속성 옆에 있는 옵션을 선택합니다. 호출 볼륨, 가용성, 결함 및 오류에 대한 세부 지표를 표시하는 그래프 세트가 표시됩니다. 그래프의 한 지점을 가리키면 자세한 정보가 포함된 팝업이 표시됩니다. 그래프에서 한 지점을 선택하면 그래프에서 선택한 지점에 대한 상관관계가 있는 트레이스를 보여주는 진단 창이 열립니다. 상관관계가 있는 트레이스 테이블에서 트레이스 ID를 선택하면 선택한 트레이스의 X-Ray 트레이스 세부 정보 페이지가 열립니다.
Synthetics canary 보기
Synthetics Canary 탭을 선택하여 Synthetics Canary 테이블과 테이블의 각 canary에 대한 지표 세트를 표시합니다. 테이블에는 성공률, 평균 기간, 실행 횟수 및 실패율에 대한 지표가 포함되어 있습니다. AWS X-Ray 추적이 활성화된 canary만 표시됩니다.
Synthetics canary 테이블의 필터 텍스트 상자를 사용하여 관심 있는 canary를 찾습니다. 생성한 각 필터는 필터 텍스트 상자 아래에 표시됩니다. 언제든지 필터 지우기를 선택하여 테이블 필터를 제거할 수 있습니다.
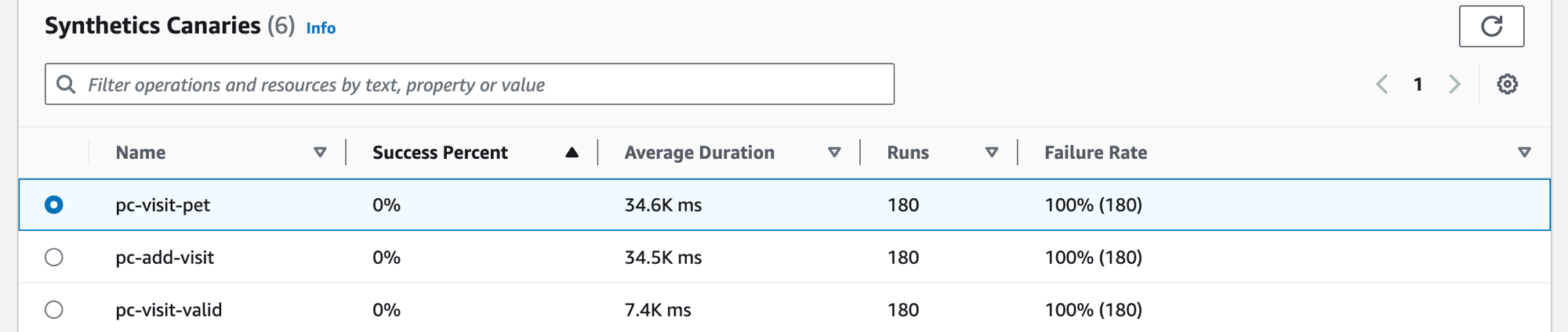
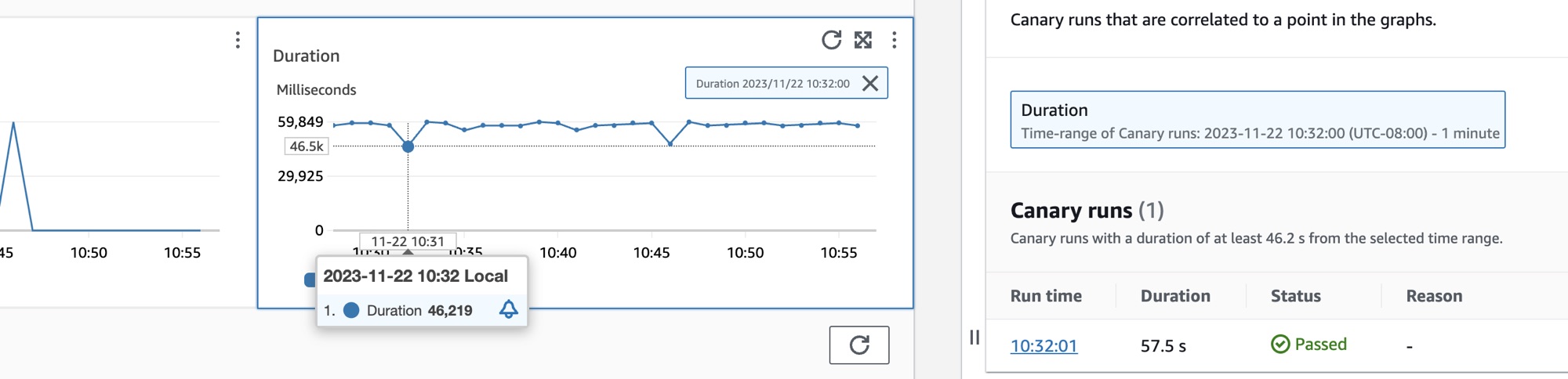
canary 이름 옆에 있는 라디오 버튼을 선택하여 성공률, 오류, 기간 등의 세부 지표가 그래프로 표시된 탭 세트를 확인합니다. 그래프의 한 지점을 가리키면 자세한 정보가 포함된 팝업이 표시됩니다. 그래프에서 하나의 포인트를 선택하여 선택한 포인트와 상관된 canary 실행을 보여주는 진단 창을 엽니다. canary 실행을 선택하고 실행 런타임을 선택하여 로그, HTTP 아카이브(HAR) 파일, 스크린샷, 문제 해결에 도움이 되는 제안 단계 등 선택한 canary 실행에 대한 아티팩트를 확인합니다. 자세히 알아보기를 선택하여 Canary 실행 옆에 있는 CloudWatch Synthetics Canaries 페이지를 엽니다.
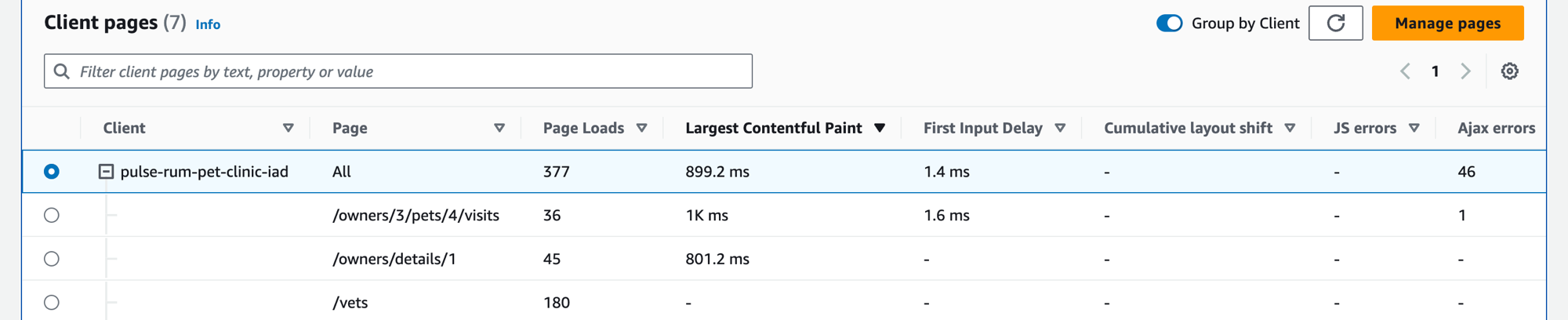
클라이언트 페이지 보기
클라이언트 페이지 탭을 선택하여 서비스를 직접 호출하는 클라이언트 웹 페이지 목록을 표시합니다. 선택한 클라이언트 페이지의 지표 세트를 사용하여 서비스 또는 애플리케이션과 상호 작용할 때 클라이언트의 경험 품질을 측정합니다. 이러한 지표로는 페이지 로드, 웹 바이탈, 오류가 포함됩니다.
테이블에 클라이언트 페이지를 표시하려면 X-Ray 추적을 위해 CloudWatch RUM 웹 클라이언트를 구성하고 클라이언트 페이지에 대한 Application Signals 지표를 켜야 합니다. 페이지 관리를 선택하여 Application Signals 지표에 대해 활성화된 페이지를 선택합니다.
필터 텍스트 상자를 사용하여 필터 텍스트 상자 아래에서 관심 있는 클라이언트 페이지 또는 애플리케이션 모니터를 찾습니다. 필터 지우기를 선택하여 테이블 필터를 제거합니다. 클라이언트별로 클라이언트 페이지를 그룹화하려면 클라이언트별로 그룹화를 선택합니다. 그룹화된 경우 클라이언트 이름 옆에 있는 + 아이콘을 선택하여 행을 확장하면 해당 클라이언트의 모든 페이지가 표시됩니다.
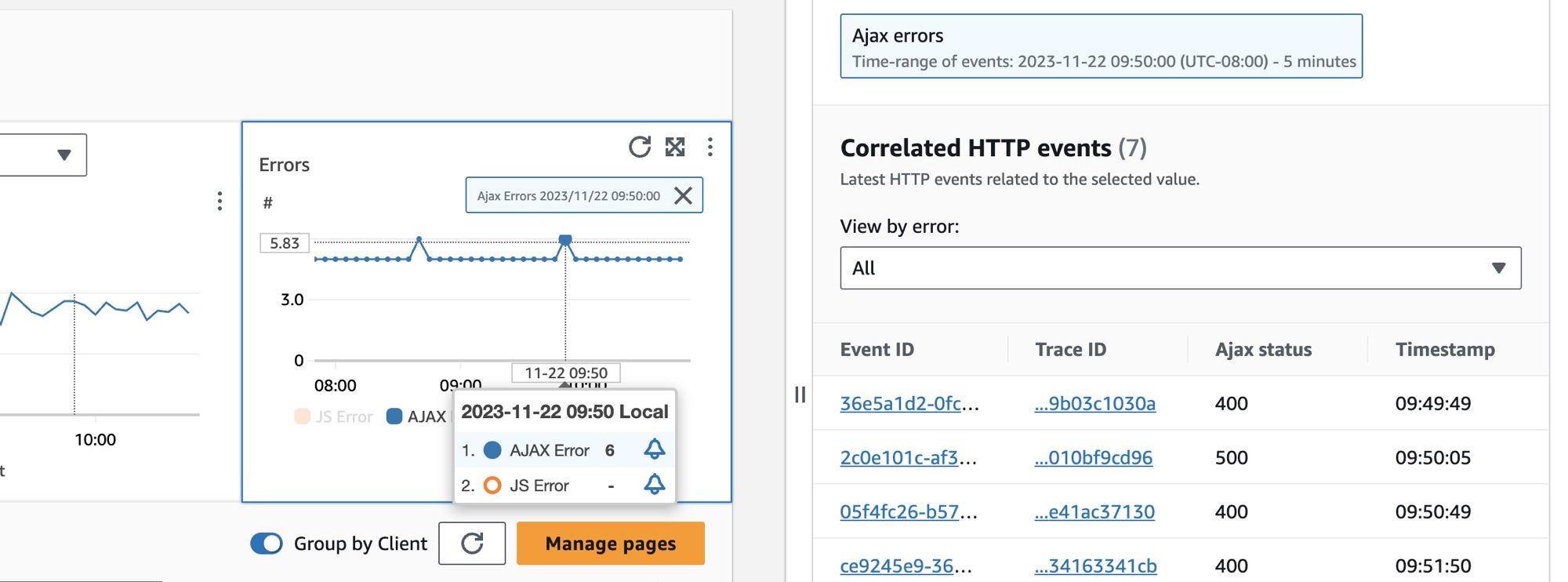
클라이언트 페이지를 선택하려면 클라이언트 페이지 테이블에서 클라이언트 페이지 옆에 있는 옵션을 선택합니다. 자세한 지표를 표시하는 그래프 세트가 표시됩니다. 그래프의 한 지점을 가리키면 자세한 정보가 포함된 팝업이 표시됩니다. 그래프에서 하나의 포인트를 선택하여 그래프에서 선택한 포인트와 상관된 성능 탐색 이벤트를 보여주는 진단 창을 엽니다. 선택한 이벤트에 대한 CloudWatch RUM 페이지 뷰를 열려면 탐색 이벤트 목록에서 이벤트 ID를 선택합니다.
참고
클라이언트 페이지 내에서 AJAX 오류를 보려면 CloudWatch RUM 웹 클라이언트 버전 1.15 이상을 사용합니다.
현재 서비스당 최대 100개의 작업, canary 및 클라이언트 페이지와 최대 250개의 종속성을 표시할 수 있습니다.
관련 지표 보기
관련 지표 탭을 사용하여 여러 지표를 시각화하고 상관관계 패턴을 식별하며 문제의 근본 원인을 확인합니다.
지표 테이블에는 세 가지 유형의 지표가 나와 있습니다.
표준 지표 - Application Signals는 검색된 서비스에서 표준 애플리케이션 지표를 수집합니다. 자세한 내용은 수집되는 표준 애플리케이션 지표를 참조하세요.
런타임 지표 - Application Signals는 AWS Distro for OpenTelemetry SDK를 사용하여 Java 및 Python 애플리케이션에서 OpenTelemetry 호환 지표를 자동으로 수집합니다. 자세한 내용은 런타임 지표를 참조하세요.
사용자 지정 지표 - Application Signals를 사용하면 애플리케이션에서 사용자 지정 지표를 생성할 수 있습니다. 자세한 내용은 Application Signals에서 사용자 지정 지표 섹션을 참조하세요.
서비스 개요, 서비스 작업, 종속성, Synthetics 카나리 또는 RUM 탭에서 관련 지표 탭에 액세스할 수 있습니다.

-
왼쪽 탐색 패널은 모든 작업 및 종속성을 선택하지 않은 상태로 시작함
-
그래프는 처음에 오류 발생률이 가장 높은 작업의 결함 지표를 표시함
상관관계 분석을 시작하기 전에 서비스 작업 또는 종속성에서 데이터 포인트가 표시되는지 확인합니다. 상관관계를 분석하려면 다음을 수행합니다.
서비스 작업 또는 종속성 페이지를 여세요.
그래프에서 데이터 포인트를 선택하세요.
오른쪽 패널에서 다른 지표와 연관을 선택하세요.
열리는 관련 지표 탭에 다음이 표시됩니다.
왼쪽 탐색에서 선택한 작업 또는 종속성
지표 찾아보기 테이블에 그래프로 표시된 선택한 지표
데이터 포인트를 선택할 때 연관된 스팬
여러 지표를 그래프로 표시하려면 관련 지표 탭의 찾아보기 보기에서 하나 이상의 지표를 선택합니다. 그래프로 표시된 모든 지표를 보려면 그래프로 표시된 지표를 선택합니다.
지표를 필터링하려면 왼쪽 패널 필터를 사용하여 특정 작업 또는 종속성에 초점을 맞추고 테이블 헤더 필터 막대를 사용하여 이름, 유형 또는 기타 속성별로 검색합니다. 이러한 필터링 옵션을 사용하면 패턴을 감지하고 문제를 보다 효율적으로 해결할 수 있습니다.
관련 지표를 자세히 분석하려면 관련 지표 탭에서 데이터 포인트를 선택합니다. 다음을 확인할 수 있습니다.
상위 기여자 - CloudWatch Logs Insights 쿼리를 실행하여 지표를 분석합니다. 이러한 쿼리는 다음에 대한 자세한 분석을 위해 키 속성이 포함된 확장 지표 형식(EMF) 레코드를 처리합니다.
지연 시간 측정
결함 발생
서비스 가용성 지표
다음 지표는 상위 기여자를 지원하지 않습니다.
OTEL 지표
서버 측 스팬 지표
RED 지표 및 클라이언트 측 스팬 지표에 대한 상위 기여자를 볼 수 있습니다.
상관관계가 있는 스팬 - 상관관계가 있는 스팬 섹션은 서비스 작업 탭과 일관되게 작동합니다. 관련 추적 및 지표를 식별하는 데 도움이 되도록 상관관계 메커니즘은 다음과 같이 작동합니다.
지표 이름과 스팬 속성 비교
선택한 기간에 일치하는 패턴 식별
관련 트레이스 정보 표시
지표 및 스팬을 함께 효과적으로 분석하려면 다양한 지표 유형의 상관관계를 이해해야 합니다. 다음은 주요 제한 사항입니다.
OTEL 지표는 독립된 이름 지정 시스템을 사용하기 때문에 스팬과 상관관계가 없습니다.
서버 또는 클라이언트 측 스팬 지표를 스팬과 연관시키는 방법:
구성에 서비스 차원 필드 포함
이 서비스 차원이 없으면 이러한 지표를 스팬과 연관시킬 수 없습니다.
로그 애플리케이션 - 로그 애플리케이션에 대한 자세한 내용은 애플리케이션 로그를 참조하세요.
