AWS CLI성능 개선 도우미에 대한 예시
다음 섹션에서 성능 개선 도우미의 AWS Command Line Interface(AWS CLI)에 대해 자세히 알아보고 AWS CLI 예제를 사용하세요.
주제
성능 개선 도우미에 대한 AWS CLI의 기본 제공 도움말
AWS CLI를 사용해 성능 개선 도우미 데이터를 볼 수 있습니다. 명령줄에 다음과 같이 입력하여 성능 개선 도우미용 AWS CLI 명령에 대한 도움말을 볼 수 있습니다.
aws pi help
AWS CLI가 설치되어 있지 않은 경우 설치에 대한 자세한 내용은 AWS CLI 사용 설명서의 AWS CLI 설치를 참조하세요.
카운터 지표 검색
다음 스크린샷은 AWS Management Console에 표시되는 카운터 지표 차트 2개를 나타낸 것입니다.
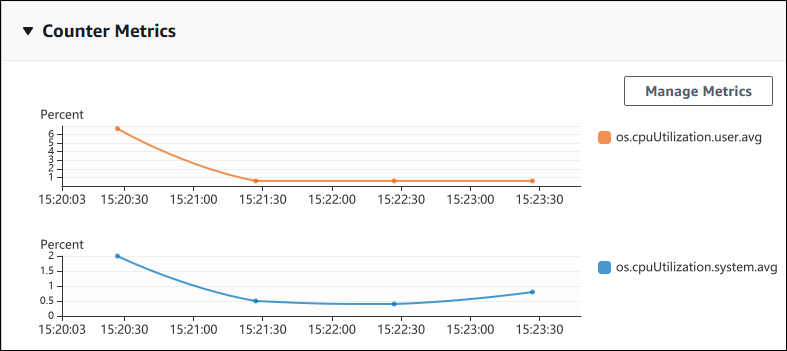
다음 예에서는 카운터 지표 차트 2개를 생성하기 위해 AWS Management Console이 사용하는 것과 동일한 데이터를 수집하는 방법을 보여줍니다.
대상 LinuxmacOS, 또는Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
Windows의 경우:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries '[{"Metric": "os.cpuUtilization.user.avg" }, {"Metric": "os.cpuUtilization.idle.avg"}]'
--metrics-query 옵션에 대해 파일을 지정하면 명령이 더 쉽게 읽히도록 할 수 있습니다. 다음 예에서는 옵션에 대해 query.json이라는 파일을 사용합니다. 이 파일의 콘텐츠는 다음과 같습니다.
[ { "Metric": "os.cpuUtilization.user.avg" }, { "Metric": "os.cpuUtilization.idle.avg" } ]
다음 명령을 실행하여 파일을 사용합니다.
대상 LinuxmacOS, 또는Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Windows의 경우:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
앞의 예에서는 옵션에 다음 값을 지정합니다.
-
--service-type– Amazon RDS용RDS -
--identifier– DB 인스턴스에 대한 리소스 ID입니다. -
--start-time및--end-time– 쿼리할 기간에 대한 ISO 8601DateTime값으로서, 지원되는 형식은 여러 가지입니다
다음과 같이 1시간 범위로 쿼리합니다:
-
--period-in-seconds– 1분당 쿼리에 대한60 -
--metric-queries– 쿼리 2개의 배열, 각 쿼리는 지표 1개에만 해당됨.지표 이름에는 지표를 유용한 범주로 분류하기 위해 점이 사용되고, 마지막 요소는 함수입니다. 예시에서 함수는 각 쿼리에 대해
avg입니다. Amazon CloudWatch와 마찬가지로 지원되는 함수는min,max,total및avg입니다.
응답은 다음과 비슷합니다.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { "Metric": "os.cpuUtilization.user.avg" //Metric1 }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 4.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 4.0 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 10.0 } //... 60 datapoints for the os.cpuUtilization.user.avg metric ] }, { "Key": { "Metric": "os.cpuUtilization.idle.avg" //Metric2 }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 12.0 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 13.5 }, //... 60 datapoints for the os.cpuUtilization.idle.avg metric ] } ] //end of MetricList } //end of response
응답에는 Identifier, AlignedStartTime 및 AlignedEndTime이 있습니다. --period-in-seconds 값이 60인 경우 시작 및 종료 시간은 분 단위로 맞춰져 있습니다. --period-in-seconds 값이 3600인 경우 시작 및 종료 시간은 시간 단위로 맞춰져 있습니다.
응답의 MetricList에는 다수의 항목이 있는데, 각각 Key 및 DataPoints 항목이 포함되어 있습니다. 각 DataPoint에는 Timestamp 및 Value이 있습니다. 쿼리는 1시간에 걸친 분당 데이터에 대한 것이므로 각 Datapoints 목록에는 Timestamp1/Minute1, Timestamp2/Minute2 등에서 최대 Timestamp60/Minute60까지 60개의 데이터 포인트가 있습니다.
쿼리는 두 가지 카운터 지표에 대한 것이므로 MetricList 응답에는 두 개의 요소가 있습니다.
상위 대기 이벤트에 대한 DB 평균 로드 검색
다음 예는 AWS Management Console에서 누적 영역 선 그래프를 생성하는 데 사용하는 것과 동일한 쿼리입니다. 이 예에서는 최상위 7개 대기 이벤트에 따라 구분된 로드의 마지막 한 시간 db.load.avg를 검색합니다. 명령은 카운터 지표 검색의 명령과 동일합니다. 그러나 query.json 파일의 컨텐츠는 다음과 같습니다.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 7 } } ]
다음 명령을 실행합니다.
대상 LinuxmacOS, 또는Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Windows의 경우:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
이 예시에서는 최상위 7개 대기 이벤트의 db.load.avg 및 GroupBy에 대한 지표를 지정합니다. 이 예의 유효 값에 대한 자세한 내용은 성능 개선 도우미 API 참조의 DimensionGroup 단원을 참조하십시오.
응답은 다음과 비슷합니다.
{ "Identifier": "db-XXX", "AlignedStartTime": 1540857600.0, "AlignedEndTime": 1540861200.0, "MetricList": [ { //A list of key/datapoints "Key": { //A Metric with no dimensions. This is the total db.load.avg "Metric": "db.load.avg" }, "DataPoints": [ //Each list of datapoints has the same timestamps and same number of items { "Timestamp": 1540857660.0, //Minute1 "Value": 0.5166666666666667 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.38333333333333336 }, { "Timestamp": 1540857780.0, //Minute 3 "Value": 0.26666666666666666 } //... 60 datapoints for the total db.load.avg key ] }, { "Key": { //Another key. This is db.load.avg broken down by CPU "Metric": "db.load.avg", "Dimensions": { "db.wait_event.name": "CPU", "db.wait_event.type": "CPU" } }, "DataPoints": [ { "Timestamp": 1540857660.0, //Minute1 "Value": 0.35 }, { "Timestamp": 1540857720.0, //Minute2 "Value": 0.15 }, //... 60 datapoints for the CPU key ] }, //... In total we have 8 key/datapoints entries, 1) total, 2-8) Top Wait Events ] //end of MetricList } //end of response
이 응답에는 MetricList에 항목이 8개 있습니다. 총 db.load.avg에는 항목이 1개 있고, 최상위 7개 대기 이벤트 중 하나에 따라 구분된 db.load.avg에 각각에 대해서는 항목이 7개 있습니다. 첫 번째 예시와 달리 그룹화 차원이 있었기 때문에 지표에 대한 각 그룹화에는 키가 1개 있어야 합니다. 기본 카운터 지표 사용 사례처럼 각 지표에 키가 한 개만 있을 수는 없습니다.
상위 SQL에 대한 DB 평균 로드 검색
다음 예에서는 최상위 10개 SQL 문을 기준으로 db.wait_events를 그룹화합니다. SQL 문에는 두 가지 그룹이 있습니다.
-
db.sql– 와 같은 SQL 문select * from customers where customer_id = 123 -
db.sql_tokenized– 와 같은 토큰화된 SQL 문select * from customers where customer_id = ?
데이터베이스 성능 분석 시 파라미터만 다른 SQL 문은 하나의 로직 항목으로 간주하는 것이 도움이 될 수 있습니다. 따라서 쿼리 시에는 db.sql_tokenized를 사용할 수 있습니다. 그러나 특히 설명 계획에 관심이 있는 경우에는 때로 파라미터가 있는 전체 SQL 문을 검토하고 db.sql로 그룹화를 쿼리하는 것이 유용합니다. 토큰화된 SQL과 전체 SQL 간에는 상위-하위 관계가 있는데, 여러 개의 전체 SQL(하위)은 토큰화된 동일한 SQL(상위) 아래에 그룹화됩니다.
이 예의 명령은 상위 대기 이벤트에 대한 DB 평균 로드 검색의 명령과 유사합니다. 그러나 query.json 파일의 컨텐츠는 다음과 같습니다.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Limit": 10 } } ]
다음 예에는 db.sql_tokenized가 사용됩니다.
대상 LinuxmacOS, 또는Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-29T00:00:00Z\ --end-time2018-10-30T00:00:00Z\ --period-in-seconds3600\ --metric-queries file://query.json
Windows의 경우:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-29T00:00:00Z^ --end-time2018-10-30T00:00:00Z^ --period-in-seconds3600^ --metric-queries file://query.json
이 예에서는 24시간 동안 쿼리를 실행하는데 1시간은 초 단위로 구성됩니다.
이 예시에서는 최상위 7개 대기 이벤트의 db.load.avg 및 GroupBy에 대한 지표를 지정합니다. 이 예의 유효 값에 대한 자세한 내용은 성능 개선 도우미 API 참조의 DimensionGroup 단원을 참조하십시오.
응답은 다음과 비슷합니다.
{ "AlignedStartTime": 1540771200.0, "AlignedEndTime": 1540857600.0, "Identifier": "db-XXX", "MetricList": [ //11 entries in the MetricList { "Key": { //First key is total "Metric": "db.load.avg" } "DataPoints": [ //Each DataPoints list has 24 per-hour Timestamps and a value { "Value": 1.6964980544747081, "Timestamp": 1540774800.0 }, //... 24 datapoints ] }, { "Key": { //Next key is the top tokenized SQL "Dimensions": { "db.sql_tokenized.statement": "INSERT INTO authors (id,name,email) VALUES\n( nextval(?) ,?,?)", "db.sql_tokenized.db_id": "pi-2372568224", "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" }, "Metric": "db.load.avg" }, "DataPoints": [ //... 24 datapoints ] }, // In total 11 entries, 10 Keys of top tokenized SQL, 1 total key ] //End of MetricList } //End of response
이 응답은 MetricList에 11개의 항목이 있는데(전체 1개, 최상위 토큰화 SQL 10개) 각 항목에는 시간당 DataPoints가 24개입니다.
토큰화된 SQL의 경우 각 차원 목록에 3개의 항목이 있습니다.
-
db.sql_tokenized.statement– 토큰화된 SQL 문입니다. -
db.sql_tokenized.db_id– SQL 참조에 사용되는 기본 데이터베이스 ID 또는 기본 데이터베이스 ID를 사용할 수 없는 경우 성능 개선 도우미가 생성하는 합성 ID입니다. 이 예에서는pi-2372568224합성 ID를 반환합니다. -
db.sql_tokenized.id– 성능 개선 도우미 내부의 쿼리에 대한 ID입니다.AWS Management Console에서는 이 ID를 지원 ID라고 합니다. ID는 AWS Support에서 데이터베이스 문제를 해결하기 위해 조사할 수 있는 데이터이기 때문에 이 이름이 지정됩니다. AWS는 데이터의 보안 및 개인 정보를 매우 중요하게 취급하며, 거의 모든 데이터는 AWS KMS 키로 암호화되어 저장됩니다. 그러므로 AWS 내부의 어느 누구도 이 데이터를 볼 수 없습니다. 앞의 예에서
tokenized.statement와tokenized.db_id모두 암호화되어 저장됩니다. 데이터베이스 관련 문제가 있는 경우 AWS Support가 지원 ID를 참조하여 도움을 드릴 수 있습니다.
쿼리 시 Group에서 GroupBy을 지정하면 편리할 수 있습니다. 그러나 반환되는 데이터에 대한 더 세분화된 제어를 위해서는 차원 목록을 지정하십시오. 예를 들어 db.sql_tokenized.statement만 필요한 경우에는 query.json file에 Dimensions 속성을 추가할 수 있습니다.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.sql_tokenized", "Dimensions":["db.sql_tokenized.statement"], "Limit": 10 } } ]
SQL을 기준으로 필터링된 DB 평균 로드 검색
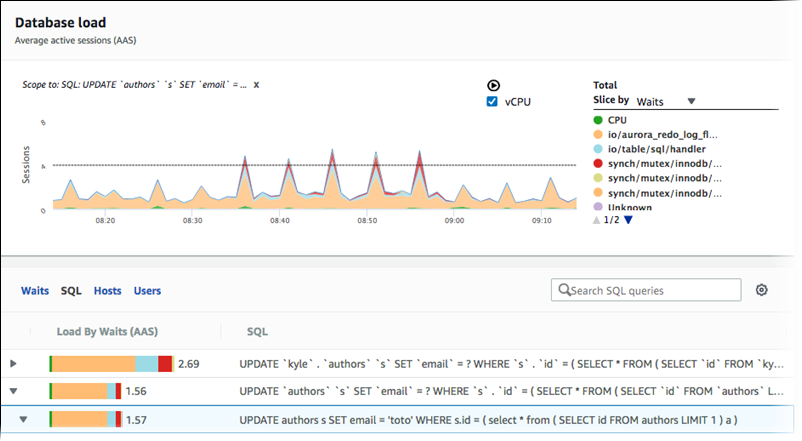
앞의 이미지에서는 특정 쿼리가 선택되어 있고 상위 평균 활성 세션 누적 영역 선 그래프는 이 쿼리로 범위가 지정되어 있습니다. 쿼리가 여전히 최상위 7개 전체 대기 이벤트에 대한 것이라 하더라도 응답의 값은 필터링됩니다. 필터로 인해 특정 필터의 짝이 되는 세션만 고려합니다.
이 예에서 해당되는 API 쿼리는 상위 SQL에 대한 DB 평균 로드 검색 단원의 명령과 유사합니다. 그러나 query.json 파일의 컨텐츠는 다음과 같습니다.
[ { "Metric": "db.load.avg", "GroupBy": { "Group": "db.wait_event", "Limit": 5 }, "Filter": { "db.sql_tokenized.id": "AKIAIOSFODNN7EXAMPLE" } } ]
대상 LinuxmacOS, 또는Unix:
aws pi get-resource-metrics \ --service-type RDS \ --identifier db-ID\ --start-time2018-10-30T00:00:00Z\ --end-time2018-10-30T01:00:00Z\ --period-in-seconds60\ --metric-queries file://query.json
Windows의 경우:
aws pi get-resource-metrics ^ --service-type RDS ^ --identifier db-ID^ --start-time2018-10-30T00:00:00Z^ --end-time2018-10-30T01:00:00Z^ --period-in-seconds60^ --metric-queries file://query.json
응답은 다음과 비슷합니다.
{ "Identifier": "db-XXX", "AlignedStartTime": 1556215200.0, "MetricList": [ { "Key": { "Metric": "db.load.avg" }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.4878117913832196 }, { "Timestamp": 1556222400.0, "Value": 1.192823803967328 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/aurora_redo_log_flush" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 1.1360544217687074 }, { "Timestamp": 1556222400.0, "Value": 1.058051341890315 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "io", "db.wait_event.name": "wait/io/table/sql/handler" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.16241496598639457 }, { "Timestamp": 1556222400.0, "Value": 0.05163360560093349 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/aurora_lock_thread_slot_futex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.11479591836734694 }, { "Timestamp": 1556222400.0, "Value": 0.013127187864644107 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "CPU", "db.wait_event.name": "CPU" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.05215419501133787 }, { "Timestamp": 1556222400.0, "Value": 0.05805134189031505 } ] }, { "Key": { "Metric": "db.load.avg", "Dimensions": { "db.wait_event.type": "synch", "db.wait_event.name": "wait/synch/mutex/innodb/lock_wait_mutex" } }, "DataPoints": [ { "Timestamp": 1556218800.0, "Value": 0.017573696145124718 }, { "Timestamp": 1556222400.0, "Value": 0.002333722287047841 } ] } ], "AlignedEndTime": 1556222400.0 } //end of response
이 응답에서 모든 값은 query.json 파일에 지정된 토큰화된 SQL AKIAIOSFODNN7EXAMPLE의 기여에 따라 필터링됩니다. 키는 필터링된 SQL에 영향을 미친 상위 5개 대기 이벤트이므로 필터가 없는 쿼리와는 다른 순서를 따를 수 있습니다.
SQL 문의 전체 텍스트 검색
다음 예제에서는 DB 인스턴스 db-10BCD2EFGHIJ3KL4M5NO6PQRS5에 대한 SQL 문의 전체 텍스트를 검색합니다. --group은 db.sql이고 --group-identifier는 db.sql.id입니다. 이 예제에서 my-sql-id는 pi
get-resource-metrics 또는 pi describe-dimension-keys를 호출하여 검색된 SQL ID를 나타냅니다.
다음 명령을 실행합니다.
대상 LinuxmacOS, 또는Unix:
aws pi get-dimension-key-details \ --service-type RDS \ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 \ --group db.sql \ --group-identifiermy-sql-id\ --requested-dimensions statement
Windows의 경우:
aws pi get-dimension-key-details ^ --service-type RDS ^ --identifier db-10BCD2EFGHIJ3KL4M5NO6PQRS5 ^ --group db.sql ^ --group-identifiermy-sql-id^ --requested-dimensions statement
이 예제에서는 차원 세부 정보를 사용할 수 있습니다. 따라서 성능 개선 도우미는 잘리지 않은 SQL 문의 전체 텍스트를 검색합니다.
{ "Dimensions":[ { "Value": "SELECT e.last_name, d.department_name FROM employees e, departments d WHERE e.department_id=d.department_id", "Dimension": "db.sql.statement", "Status": "AVAILABLE" }, ... ] }
특정 기간에 대한 성과 분석 보고서 생성
다음 예시에서는 db-loadtest-0 데이터베이스에 대해 1682969503 시작 시간과 1682979503 종료 시간을 사용하여 성능 분석 보고서를 생성합니다.
aws pi create-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --start-time 1682969503 \ --end-time 1682979503 \ --region us-west-2
응답은 보고서의 고유 식별자인 report-0234d3ed98e28fb17입니다.
{ "AnalysisReportId": "report-0234d3ed98e28fb17" }
성능 분석 보고서 검색
다음 예시에서는 report-0d99cc91c4422ee61 보고서에 대한 분석 보고서 세부 정보를 검색합니다.
aws pi get-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
응답은 보고서 상태, ID, 시간 세부 정보, 인사이트를 제공합니다.
{ "AnalysisReport": { "Status": "Succeeded", "ServiceType": "RDS", "Identifier": "db-loadtest-0", "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61", "EndTime": 1680587086.584, "CreateTime": 1680587087.139, "Insights": [ ... (Condensed for space) ] } }
DB 인스턴스에 대한 모든 성능 분석 보고서 나열
다음 예시에서는 db-loadtest-0 데이터베이스에 대해 사용 가능한 모든 성능 분석 보고서를 나열합니다.
aws pi list-performance-analysis-reports \ --service-type RDS \ --identifier db-loadtest-0 \ --region us-west-2
응답에는 보고서 ID, 상태 및 기간 세부 정보와 함께 모든 보고서가 나열됩니다.
{ "AnalysisReports": [ { "Status": "Succeeded", "EndTime": 1680587086.584, "CreationTime": 1680587087.139, "StartTime": 1680583486.584, "AnalysisReportId": "report-0d99cc91c4422ee61" }, { "Status": "Succeeded", "EndTime": 1681491137.914, "CreationTime": 1681491145.973, "StartTime": 1681487537.914, "AnalysisReportId": "report-002633115cc002233" }, { "Status": "Succeeded", "EndTime": 1681493499.849, "CreationTime": 1681493507.762, "StartTime": 1681489899.849, "AnalysisReportId": "report-043b1e006b47246f9" }, { "Status": "InProgress", "EndTime": 1682979503.0, "CreationTime": 1682979618.994, "StartTime": 1682969503.0, "AnalysisReportId": "report-01ad15f9b88bcbd56" } ] }
성능 분석 보고서 삭제
다음 예시에서는 db-loadtest-0 데이터베이스에 대한 분석 보고서를 삭제합니다.
aws pi delete-performance-analysis-report \ --service-type RDS \ --identifier db-loadtest-0 \ --analysis-report-id report-0d99cc91c4422ee61 \ --region us-west-2
성능 분석 보고서에 태그 추가
다음 예시에서는 report-01ad15f9b88bcbd56 보고서에 키 name 및 값 test-tag로 태그를 추가합니다.
aws pi tag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tags Key=name,Value=test-tag \ --region us-west-2
성능 분석 보고서에 대한 모든 태그 나열
다음 예시에서는 report-01ad15f9b88bcbd56 보고서에 대한 태그를 모두 나열합니다.
aws pi list-tags-for-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --region us-west-2
응답에는 보고서에 추가된 모든 태그의 값과 키가 나열됩니다.
{ "Tags": [ { "Value": "test-tag", "Key": "name" } ] }
성능 분석 보고서에서 태그 삭제
다음 예시에서는 report-01ad15f9b88bcbd56 보고서에서 name 태그를 삭제합니다.
aws pi untag-resource \ --service-type RDS \ --resource-arn arn:aws:pi:us-west-2:356798100956:perf-reports/RDS/db-loadtest-0/report-01ad15f9b88bcbd56 \ --tag-keys name \ --region us-west-2
태그가 삭제된 후 list-tags-for-resource API를 호출하면 이 태그를 나열하지 않습니다.
