Amazon Aurora Global Database에서 전환 또는 장애 조치 사용
Aurora 글로벌 데이터베이스는 Aurora DB 클러스터를 통해 단일 AWS 리전에서 제공되는 표준 고가용성보다 더 많은 비즈니스 연속성 및 재해 복구(BCDR) 보호 기능을 제공합니다. Aurora 글로벌 데이터베이스를 사용하면 실제 리전 간 재해나 전체 서비스 수준 중단에 신속하게 대비하고 복구할 수 있습니다. 재해 복구는 일반적으로 다음 2가지 비즈니스 목표에 따라 이루어집니다.
-
Recovery Time Objective(RTO) – 재해 또는 서비스 중단이 발생한 후 시스템이 정상 작동 상태로 돌아가는 데 걸리는 시간입니다. 즉 RTO는 가동 중지 시간을 측정합니다. Aurora 글로벌 데이터베이스의 경우, RTO는 분 단위가 될 수 있습니다.
Recovery Point Objective(RPO) – 재해 또는 서비스 중단이 발생한 후 손실될 수 있는 데이터의 양(시간 단위로 측정)입니다. 이러한 데이터 손실은 일반적으로 비동기식 복제 지연으로 인해 발생합니다. Aurora 글로벌 데이터베이스의 경우, RPO는 일반적으로 초 단위로 측정됩니다. Aurora PostgreSQL–기반 전역 데이터베이스를 사용하면,
rds.global_db_rpo파라미터를 사용하여 RPO에 대한 상한선을 설정하고 추적할 수 있지만, 이렇게 하면 기본 클러스터 라이터 노드에서의 트랜잭션 처리에 영향을 줄 수 있습니다. 자세한 내용은 Aurora PostgreSQL–기반 전역 데이터베이스에 대한 RPO 관리 단원을 참조하세요.
Aurora 글로벌 데이터베이스를 전환하거나 장애 조치하려면 글로벌 데이터베이스의 보조 리전 중 하나에 있는 DB 클러스터를 기본 DB 클러스터로 승격시켜야 합니다. '리전별 중단'이라는 용어는 다양한 장애 시나리오를 설명하는 데 자주 사용됩니다. 최악의 시나리오로는 수백 제곱마일에 영향을 미치는 치명적인 이벤트가 발생하여 광범위한 중단이 발생하는 경우를 예로 들 수 있습니다. 그러나 대부분의 중단은 훨씬 더 국소적으로 발생하므로 클라우드 서비스 또는 고객 시스템의 극히 일부에만 영향을 미칩니다. 중단의 전체 범위를 고려하여 리전 간 장애 조치가 적절한 솔루션인지 확인하고 상황에 적합한 장애 조치 방법을 선택합니다. 장애 조치 또는 전환 접근 방식을 사용해야 하는지 여부는 다음의 특정 중단 시나리오에 따라 달라집니다.
장애 조치 – 이 접근 방식을 사용하면 예상치 못한 중단으로부터 서비스를 복구할 수 있습니다. 이 접근 방식을 사용하면 리전 간 장애 조치를 Aurora 글로벌 데이터베이스의 보조 DB 클러스터 중 하나에 수행합니다. 이 접근 방식의 RPO는 일반적으로 초 단위로 측정되는 0을 제외한 값입니다. 데이터 손실량은 장애 시점에 AWS 리전 전반에서 발생하는 Aurora 글로벌 데이터베이스 복제 지연 시간에 따라 달라집니다. 자세한 내용은 계획되지 않은 중단으로부터 Amazon Aurora Global Database 복구 단원을 참조하세요.
전환 – 이 작업의 이전 명칭은 '계획된 관리형 장애 조치'입니다. 이 접근 방식은 운영 유지 관리 및 기타 계획된 운영 절차 등 제어된 시나리오에서 사용합니다. 이 기능은 다른 변경 작업을 수행하기 전에 보조 DB 클러스터를 기본 DB 클러스터와 동기화하므로 RPO는 0입니다(데이터 손실 없음). 자세한 내용은 Amazon Aurora Global Database에서 전환 수행을 참조하십시오.
참고
헤드리스 보조 Aurora DB 클러스터로 전환하거나 장애 조치하려면 먼저 DB 인스턴스를 추가해야 합니다. 헤드리스 DB 클러스터에 관해 자세히 알아보려면 보조 리전에 헤드리스 Aurora DB 클러스터 생성 단원을 참조하세요.
주제
계획되지 않은 중단으로부터 Amazon Aurora Global Database 복구
매우 드문 경우지만, Aurora 글로벌 데이터베이스의 기본 AWS 리전에서 예상치 못한 중단이 발생할 수 있습니다. 이럴 경우, 기본 Aurora DB 클러스터와 해당 라이터 노드를 사용할 수 없으며 기본 클러스터와 보조 클러스터 간의 복제가 중단됩니다. 가동 중지 시간(RTO)과 데이터 손실(RPO)을 둘 다 최소화하기 위해 신속하게 리전 간 장애 조치를 수행할 수 있습니다.
재해 복구 상황에서 장애 조치를 수행하는 방법은 다음과 같이 2가지입니다.
관리형 장애 조치 - 이는 재해 복구를 수행할 때 권장하는 방법입니다. 이 방법을 사용하는 경우 Aurora는 기존의 기본 리전을 다시 사용할 수 있게 될 때 자동으로 글로벌 데이터베이스에 보조 리전으로 이를 다시 추가합니다. 따라서 글로벌 클러스터의 기존 토폴로지가 계속 유지됩니다. 이 방법을 사용하는 방법을 알아보려면 Aurora 글로벌 데이터베이스에서 계획된 관리형 장애 조치 수행 단원을 참조하세요.
수동 장애 조치 – 이 대체 방법은 가령 기본 리전과 보조 리전이 비호환 엔진 버전을 실행 중인 관계로 관리형 장애 조치를 사용할 수 없을 때 사용할 수 있습니다. 이 방법을 사용하는 방법을 알아보려면 Aurora 글로벌 데이터베이스에서 수동 장애 조치 수행 단원을 참조하세요.
중요
두 장애 조치 방법을 사용할 경우, 장애 조치 이벤트가 발생하기 전에 선택한 보조 리전에 쓰기 트랜잭션 데이터가 복제되지 않으면 해당 데이터가 손실될 수 있습니다. 하지만 선택한 보조 DB 클러스터의 DB 인스턴스를 기본 라이터 DB 인스턴스로 승격시키는 복구 프로세스는 데이터가 트랜잭션 형태로 일관된 상태를 유지하도록 보장해 줍니다.
Aurora 글로벌 데이터베이스에서 계획된 관리형 장애 조치 수행
이 접근 방식은 실제 리전별 재해 이벤트 또는 전체 서비스 수준 중단이 발생하는 경우 비즈니스 연속성을 유지하기 위해 개발되었습니다.
관리형 장애 조치 중에, Aurora 글로벌 데이터베이스의 기존 복제 토폴로지가 유지되는 동안 기본 클러스터는 선택한 보조 리전으로 장애 조치됩니다. 선택한 보조 클러스터에서는 읽기 전용 노드 중 하나가 전체 라이터 상태로 승격됩니다. 이 단계를 통해 클러스터는 기본 클러스터의 역할을 맡게 됩니다. 클러스터가 새 역할을 맡는 동안에는 데이터베이스를 일시적으로 사용할 수 없습니다. 이 보조 클러스터가 새 기본 클러스터가 되면 기존 기본 클러스터에서 선택한 보조 클러스터로 복제되지 않은 데이터는 누락됩니다.
참고
기본 및 보조 DB 클러스터에 있는 메이저, 마이너, 패치 수준 엔진 버전이 동일한 경우 Aurora 글로벌 데이터베이스에서 관리형 리전 간 데이터베이스 장애 조치만 수행할 수 있습니다. 하지만 패치 수준은 마이너 엔진 버전에 따라 다를 수 있습니다. 자세한 내용은 관리형 리전 간 전환 및 장애 조치를 위한 패치 수준 호환성 단원을 참조하십시오. 엔진 버전이 호환되지 않는 경우 Aurora 글로벌 데이터베이스에서 수동 장애 조치 수행에 나온 단계에 따라 수동으로 장애 조치를 수행할 수 있습니다.
데이터 손실을 최소화하려면 이 기능을 사용하기 전에 다음을 수행하는 것이 좋습니다.
애플리케이션을 오프라인으로 전환하여 쓰기가 Aurora 전역 데이터베이스의 기본 클러스터로 전송되는 경우를 방지합니다.
Aurora 전역 데이터베이스의 모든 보조 Aurora DB 클러스터에 대한 지연 시간을 확인합니다. 복제 지연이 가장 적게 소요되는 보조 리전을 선택하면 현재 장애가 발생한 기본 리전에서 데이터 손실을 최소화할 수 있습니다. 모든 Aurora PostgreSQL 기반 글로벌 데이터베이스 및 엔진 버전 3.04.0 이상 또는 2.12.0 이상으로 시작하는 Aurora MySQL 기반 글로벌 데이터베이스의 경우 Amazon CloudWatch를 사용하여 모든 보조 DB 클러스터에 대한
AuroraGlobalDBRPOLag지표를 확인하세요. 하위 마이너 버전의 Aurora MySQL 기반 글로벌 데이터베이스의 경우에는AuroraGlobalDBReplicationLag지표를 확인하세요. 이 지표를 통해 보조 DB 클러스터가 기본 DB 클러스터에 비해 얼마나 뒤처져 있는지(밀리초 단위) 알 수 있습니다.CloudWatch의 Aurora 지표에 대한 자세한 내용은 Amazon Aurora에 대한 클러스터 수준 지표 단원을 참조하세요.
관리형 장애 조치 중에, 선택한 보조 DB 클러스터가 기본 DB 클러스터처럼 새 역할로 승격됩니다. 하지만 기본 DB 클러스터의 다양한 구성 옵션은 상속되지 않습니다. 구성이 일치하지 않으면 성능 문제, 워크로드 비호환성, 기타 비정상적인 동작이 발생할 수 있습니다. 이러한 문제를 방지하려면, 다음에 대해 Aurora 전역 데이터베이스 클러스터 간의 차이점을 해결하는 것이 좋습니다.
필요한 경우 새 기본 클러스터에 대한 DB 클러스터 파라미터 그룹 Aurora구성 – Aurora 전역 데이터베이스의 각 Aurora 클러스터에 대해 Aurora DB 클러스터 파라미터 그룹을 개별적으로 구성할 수 있습니다. 즉, 보조 DB 클러스터가 기본 클러스터 역할을 맡도록 승격되면 보조 클러스터의 파라미터 그룹이 기본 클러스터와 다르게 구성될 수 있습니다. 그런 경우, 승격된 보조 DB 클러스터의 파라미터 그룹을 기본 클러스터의 설정에 맞게 수정합니다. 자세한 방법은 Aurora 글로벌 데이터베이스에 대한 파라미터 수정 단원을 참조하십시오.
Amazon CloudWatch Events 및 경보 등의 모니터링 도구 및 옵션 구성 – 승격된 DB 클러스터를 전역 데이터베이스에 필요한 것과 동일한 로깅 기능, 경보 등으로 구성합니다. 파라미터 그룹과 마찬가지로, 이러한 기능에 대한 구성은 장애 조치 프로세스 중에 기본 클러스터에서 상속되지 않습니다. 복제 지연과 같은 일부 CloudWatch 지표는 보조 리전에서만 사용할 수 있습니다. 따라서 장애 조치로 인해 해당 지표를 보고 경보를 설정하는 방법이 달라짐에 따라 사전 정의된 대시보드를 변경해야 할 수도 있습니다. Aurora DB 클러스터 및 모니터링에 대한 자세한 내용은 Amazon Aurora 모니터링 개요를 참조하세요.
다른 AWS 서비스와의 통합 구성 - Aurora Global Database가 AWS Secrets Manager, AWS Identity and Access Management, Amazon S3 및 AWS Lambda와 같은 AWS 서비스와 통합되는 경우, 요구 사항에 맞게 구성되어 있는지 확인해야 합니다. Aurora 전역 데이터베이스를 IAM, Amazon S3, Lambda과(와) 통합하는 방법에 대한 자세한 내용은 다른 AWS 서비스와 함께 Amazon Aurora Global Database 사용 섹션을 참조하세요. Secrets Manager에 대한 자세한 내용은 AWS 리전에 걸쳐 AWS Secrets Manager에서 비밀 복제를 자동화하는 방법
을 참조하세요.
일반적으로 선택한 보조 클러스터는 몇 분 이내에 기본 역할을 맡게 됩니다. 새 기본 리전의 라이터 노드를 사용할 수 있게 되면 애플리케이션을 노드에 연결하고 워크로드를 재개할 수 있습니다. Aurora에서 새 기본 클러스터가 승격되고 난 후, 모든 추가 보조 리전 클러스터가 자동으로 재구축됩니다.
Aurora 글로벌 데이터베이스는 비동기식 복제를 사용하므로 보조 리전마다 복제 지연 시간이 다를 수 있습니다. Aurora는 이러한 보조 리전을 재구축하여 새로운 기본 리전 클러스터와 정확히 동일한 시점의 데이터를 확보하도록 지원합니다. 전체 재구축 작업에 소요되는 시간은 스토리지 볼륨의 크기와 리전 간 거리에 따라 몇 분에서 몇 시간이 걸릴 수 있습니다. 보조 리전 클러스터의 재구축이 새 기본 리전에서 완료되면 읽기 권한으로 액세스할 수 있습니다.
새 기본 라이터가 승격되어 사용 가능해지면 새 기본 리전의 클러스터에서 Aurora 글로벌 데이터베이스의 읽기 및 쓰기 작업을 처리할 수 있습니다. 애플리케이션의 엔드포인트를 변경하여 새 엔드포인트를 사용할 수 있는지 확인하세요. Aurora 전역 데이터베이스를 생성할 때 제공된 이름을 수락한 경우, 애플리케이션에 있는 승격된 클러스터의 엔드포인트 문자열에서 -ro을(를) 제거하여 엔드포인트를 변경할 수 있습니다.
예를 들어, 보조 클러스터의 엔드포인트 my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com은(는) 해당 클러스터가 기본 클러스터로 승격될 때 my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com이(가) 됩니다.
RDS 프록시를 사용하는 경우, 애플리케이션의 쓰기 작업을 새 기본 클러스터와 연결된 프록시의 적절한 읽기/쓰기 엔드포인트로 리디렉션해야 합니다. 이 프록시 엔드포인트는 기본 엔드포인트이거나 사용자 지정 읽기/쓰기 엔드포인트일 수 있습니다. 자세한 정보는 RDS 프록시 엔드포인트가 글로벌 데이터베이스에서 작동하는 방식 섹션을 참조하세요.
글로벌 데이터베이스 클러스터의 기존 토폴로지를 복원하기 위해 Aurora는 기존 기본 리전의 가용성을 모니터링합니다. 해당 리전이 정상이고 다시 사용 가능한 상태가 되면 Aurora는 자동으로 글로벌 클러스터에 보조 리전으로 다시 추가합니다. Aurora는 장애가 발생하는 시점에 기존 스토리지 볼륨의 스냅샷을 만들고자 시도한 후, 기존 기본 리전에 새 스토리지 볼륨을 생성합니다. 이렇게 하면 누락된 데이터를 복구하는 데 사용할 수 있습니다. 이 작업이 성공하면 Aurora는 AWS Management Console의 스냅샷 섹션에 'rds:unplanned-global-failover-name-of-old-primary-DB-cluster-timestamp'라는 이름으로 이 스냅샷을 저장합니다. 또한 이 스냅샷은 DescribeDBClusterSnapshots API 작업에서 반환된 정보에 나열되어 있으니 해당 위치에서 확인할 수 있습니다.
참고
기존 스토리지 볼륨의 스냅샷은 시스템 스냅샷으로, 기존 기본 클러스터에 구성된 백업 보존 기간이 적용됩니다. 보존 기간 이후에도 이 스냅샷을 보존하려면 스냅샷을 복사하여 수동 스냅샷으로 저장할 수 있습니다. 요금 등 스냅샷 복사에 대해 자세히 알아보려면 DB 클러스터 스냅샷 복사 단원을 참조하세요.
기존 토폴로지가 복원된 후 비즈니스 및 워크로드에 가장 적합한 시점에 전환 작업을 수행하여 글로벌 데이터베이스를 기존의 기본 리전으로 페일백할 수 있습니다. 이렇게 하려면 Amazon Aurora Global Database에서 전환 수행 단원의 절차를 따르세요.
AWS Management Console, AWS CLI 또는 RDS API를 사용하여 Aurora Global Database를 장애 조치할 수 있습니다.
Aurora 글로벌 데이터베이스에서 관리형 장애 조치를 수행하는 방법
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. 데이터베이스를 선택하고 장애 조치할 Aurora 전역 데이터베이스를 찾습니다.
작업 메뉴에서 글로벌 데이터베이스 전환 또는 장애 조치를 선택합니다.
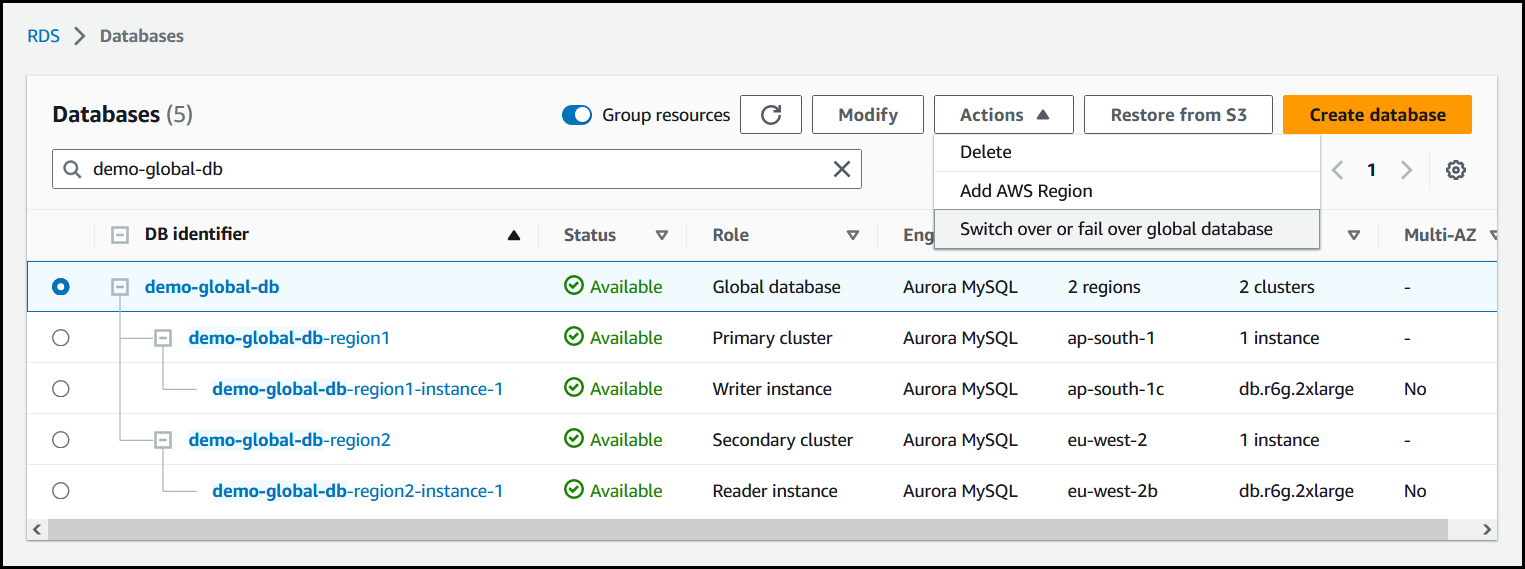
장애 조치(데이터 손실 허용)를 선택합니다.
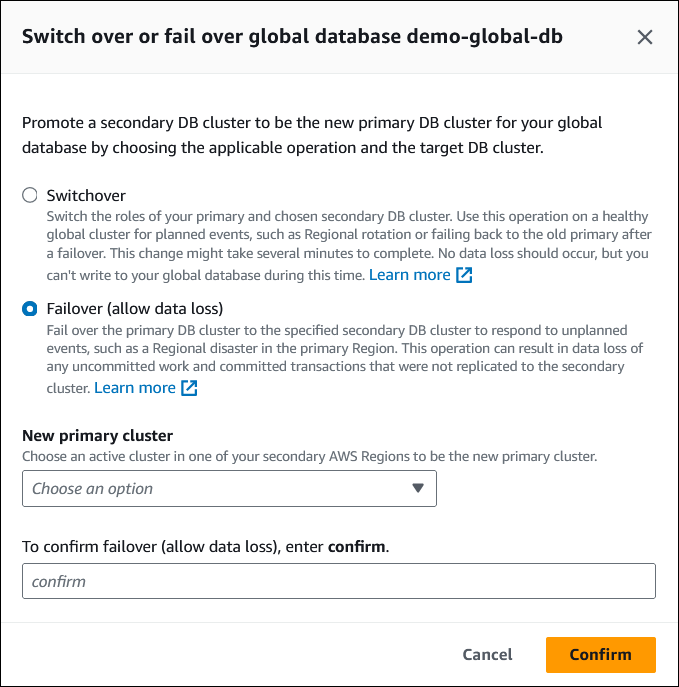
새 기본 클러스터에서 보조 AWS 리전 중 하나의 활성 클러스터를 새 기본 클러스터로 선택합니다.
confirm을 입력한 후 확인을 선택합니다.
장애 조치가 완료되면 다음 이미지와 같이 데이터베이스 목록에서 Aurora DB 클러스터와 해당 클러스터의 현재 상태를 확인할 수 있습니다.
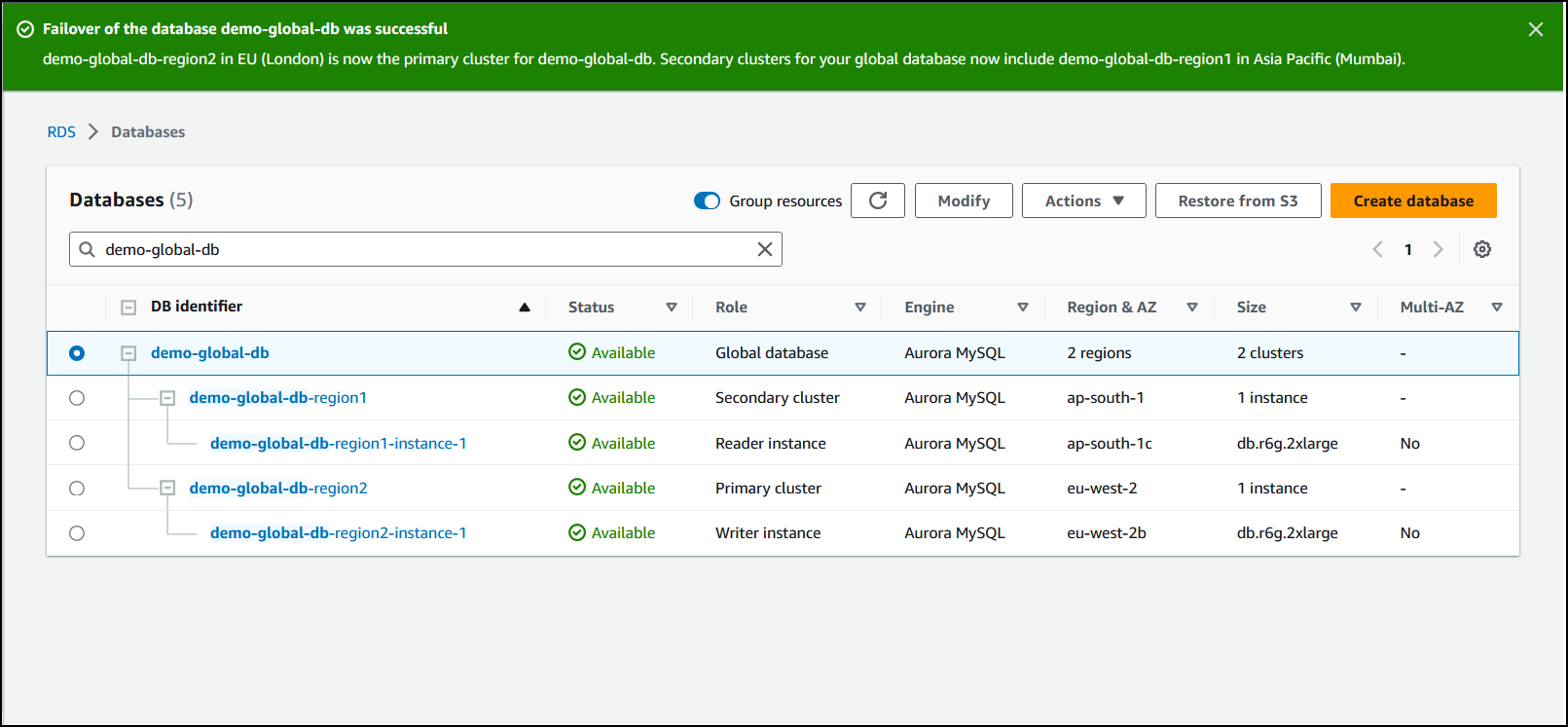
Aurora 글로벌 데이터베이스에서 관리형 장애 조치를 수행하는 방법
failover-global-cluster CLI 명령을 사용하여 Aurora 전역 데이터베이스를 장애 조치합니다. 명령을 사용하여 다음 파라미터에 대한 값을 전달합니다.
-
--region– Aurora 글로벌 데이터베이스의 새 기본 클러스터로 사용하려는 보조 DB 클러스터가 실행 중인 AWS 리전을 지정합니다. --global-cluster-identifier– Aurora 전역 데이터베이스의 이름을 지정합니다.--target-db-cluster-identifier– Aurora 글로벌 데이터베이스의 새 기본 클러스터로 승격시킬 Aurora DB 클러스터의 Amazon 리소스 이름(ARN)을 지정합니다.--allow-data-loss– 명시적으로 전환 작업이 아닌 장애 조치 작업으로 설정합니다. 비동기식 복제 구성 요소에서 모든 복제된 데이터가 보조 리전으로 전송되는 작업이 완료되지 않으면 장애 조치 작업으로 인해 일부 데이터가 손실될 수 있습니다.
대상 LinuxmacOS, 또는Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Windows의 경우:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Aurora 전역 데이터베이스를 장애 조치하려면 FailoverGlobalCluster API 작업을 실행합니다.
Aurora 글로벌 데이터베이스에서 수동 장애 조치 수행
일부 시나리오에서는 관리형 장애 조치 프로세스를 사용하지 못할 수 있습니다. 일례로 기본 및 보조 DB 클러스터가 호환되는 엔진 버전을 실행하지 않는 경우를 들 수 있습니다. 이 경우 본 수동 프로세스에 따라 글로벌 데이터베이스를 대상 보조 리전으로 장애 조치할 수 있습니다.
작은 정보
이 프로세스를 사용하기 전에 프로세스를 이해하는 것이 좋습니다. 리전 전반의 문제의 첫 신호가 나타날 때 신속하게 진행할 수 있도록 계획을 세우세요. Amazon CloudWatch를 정기적으로 사용하여 보조 클러스터의 지연 시간을 추적하면 복제 작업 지연이 최소한으로 발생하는 보조 리전을 식별하는 데 대비할 수 있습니다. 계획을 테스트하여 절차가 완전하고 정확한지 여부와 직원이 실제로 이러한 일이 발생하기 전에 재해 복구 장애 조치를 수행할 수 있도록 교육을 받았는지 확인합니다.
기본 리전에서 계획되지 않은 중단이 발생한 후 수동으로 보조 클러스터로 장애 조치하는 방법
-
중단 시 AWS 리전의 기본 Aurora DB 클러스터에 대한 DML 문 및 기타 쓰기 작업을 중지합니다.
-
보조 AWS 리전에서 새 기본 DB 클러스터로 사용할 Aurora DB 클러스터를 식별합니다. Aurora 글로벌 데이터베이스에 2개 이상의 보조 AWS 리전이 있는 경우, 복제 지연 시간이 가장 적은 보조 클러스터를 선택합니다.
선택한 보조 DB 클러스터를 Aurora 전역 데이터베이스에서 분리합니다.
Aurora 전역 데이터베이스에서 보조 DB 클러스터를 제거하면 기본 클러스터에서 이 보조 클로스터로의 복제가 즉시 중지되고 전체 읽기/쓰기 기능이 있는 프로비저닝된 독립형 Aurora DB 클러스터로 승격됩니다. 중단 시 리전의 기본 클러스터와 연결된 다른 보조 Aurora DB 클러스터는 계속 사용할 수 있으며 애플리케이션의 호출을 수락할 수 있습니다. 클러스터는 리소스도 소비합니다. Aurora 전역 데이터베이스를 다시 생성하므로, 다음 단계에서 새 Aurora 전역 데이터베이스를 생성하기 전에 다른 보조 DB 클러스터를 제거하세요. 이렇게 하면 Aurora 전역 데이터베이스의 DB 클러스터 간의 데이터 불일치(브레인 분할 문제)를 피할 수 있습니다.
분리 단계에 대한 자세한 내용은 Amazon Aurora 글로벌 데이터베이스에서 클러스터 제거 단원을 참조하세요.
-
새로운 엔드포인트를 사용하여 현재의 이 독립형 Aurora DB 클러스터로 모든 쓰기 작업을 전송하도록 애플리케이션을 재구성합니다. Aurora 전역 데이터베이스를 생성할 때 제공된 이름을 수락한 경우, 애플리케이션에 있는 클러스터의 엔드포인트 문자열에서
-ro을(를) 제거하여 엔드포인트를 변경할 수 있습니다.예를 들어, 보조 클러스터의 엔드포인트
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com은(는) 해당 클러스터가my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com전역 데이터베이스에서 분리될 때 Aurora이(가) 됩니다.이 Aurora DB 클러스터는 다음 단계에서 리전을 추가하기 시작하면 새 Aurora 전역 데이터베이스의 기본 클러스터가 됩니다.
RDS 프록시를 사용하는 경우, 애플리케이션의 쓰기 작업을 새 기본 클러스터와 연결된 프록시의 적절한 읽기/쓰기 엔드포인트로 리디렉션해야 합니다. 이 프록시 엔드포인트는 기본 엔드포인트이거나 사용자 지정 읽기/쓰기 엔드포인트일 수 있습니다. 자세한 정보는 RDS 프록시 엔드포인트가 글로벌 데이터베이스에서 작동하는 방식 섹션을 참조하세요.
-
DB 클러스터에 AWS 리전을 추가합니다. 이렇게 하면 기본 클러스터에서 보조 클러스터로의 복제 프로세스가 시작됩니다. 리전을 추가하는 자세한 단계는 Amazon Aurora Global Database에 AWS 리전 추가 단원을 참조하세요.
-
필요에 따라 더 많은 AWS 리전를 추가하여 애플리케이션을 지원하는 데 필요한 토폴로지를 다시 생성합니다.
애플리케이션 쓰기가 이러한 변경 전, 중, 후에 올바른 Aurora DB 클러스터로 전송되는지 확인합니다. 이렇게 하면 Aurora 전역 데이터베이스의 DB 클러스터 간의 데이터 불일치(브레인 분할 문제)를 피할 수 있습니다.
AWS 리전에서의 중단에 대한 응답으로 재구성한 경우, 중단이 해결된 후 AWS 리전을 기본으로 되돌릴 수 있습니다. 이렇게 하려면 새 글로벌 데이터베이스에 이전 AWS 리전을 추가한 다음, 전환 프로세스를 사용하여 해당 역할을 전환합니다. Aurora 글로벌 데이터베이스에서는 전환을 지원하는 Aurora PostgreSQL 또는 Aurora MySQL 버전을 사용해야 합니다. 자세한 내용은 Amazon Aurora Global Database에서 전환 수행 단원을 참조하십시오.
Amazon Aurora Global Database에서 전환 수행
참고
전환의 이전 명칭은 '계획된 관리형 장애 조치'입니다.
전환을 사용하면 기본 클러스터의 리전을 정기적으로 변경할 수 있습니다. 이 접근 방식은 운영 유지 관리 및 기타 계획된 운영 절차 등 제어된 시나리오를 대상으로 개발되었습니다.
전환은 일반적으로 3가지의 경우에 사용됩니다.
특정 산업에서 필요로 하는 '리전별 순환' 요구 사항을 살펴봅니다. 예를 들어 금융 서비스 규정에 따라 재해 복구 절차가 정기적으로 실행되도록 보장하려면 Tier-0 시스템을 몇 개월 동안 다른 리전으로 전환해야 할 수 있습니다.
여러 리전의 'follow-the-sun' 애플리케이션을 살펴봅니다. 각기 다른 시간대 전반에서 업무 시간을 기준으로 여러 리전별로 지연 시간이 짧은 쓰기 기능을 제공하고자 하는 기업을 예로 들 수 있습니다.
데이터 손실 제로의 방법이며, 장애 조치 후 기존의 기본 리전으로 페일백하는 데 유용합니다.
참고
전환은 정상적인 Aurora 글로벌 데이터베이스에서 사용하도록 개발되었습니다. 예상치 못한 중단이 발생한 상태에서 복구하려면 계획되지 않은 중단으로부터 Amazon Aurora Global Database 복구 단원에 나온 적절한 절차를 따르세요.
전환을 수행하려면 대상 보조 DB 클러스터에서는 엔진 버전에 따라 패치 수준을 비롯해 정확히 동일한 엔진 버전을 실행해야 합니다. 자세한 내용은 관리형 리전 간 전환 및 장애 조치를 위한 패치 수준 호환성 단원을 참조하십시오. 전환을 시작하기 전에 글로벌 클러스터의 엔진 버전을 확인하여 관리형 리전 간 전환을 지원하는지 확인하고 필요한 경우 업그레이드합니다.
전환 중에, Aurora에서는 글로벌 데이터베이스의 기존 복제 토폴로지가 유지되는 동안 기본 클러스터를 선택한 보조 리전으로 전환합니다. Aurora는 모든 보조 리전 클러스터가 기본 리전 클러스터와 완전히 동기화될 때까지 기다린 다음, 전환 프로세스를 시작합니다. 그러면 기본 리전의 DB 클러스터가 읽기 전용 상태가 되고, 선택한 보조 클러스터는 읽기 전용 노드 중 하나를 전체 라이터 상태로 승격시킵니다. 이 노드를 라이터로 승격시키면 보조 클러스터가 기본 클러스터의 역할을 맡을 수 있습니다. 프로세스 시작 시 모든 보조 클러스터가 기본 클러스터와 동기화되었으므로, 새로운 기본 클러스터는 데이터 손실 없이 Aurora 전역 데이터베이스에 대한 작업을 계속합니다. 기본 클러스터와 선택한 보조 클러스터가 새 역할을 맡으므로 데이터베이스를 잠시 사용할 수 없습니다.
애플리케이션 가용성을 최적화하려면 이 기능을 사용하기 전에 다음 작업을 수행하는 것이 좋습니다.
-
사용량이 적은 시간이나 기본 DB 클러스터에 대한 쓰기가 최소인 시간에 이 작업을 수행합니다.
애플리케이션을 오프라인으로 전환하여 쓰기가 Aurora 전역 데이터베이스의 기본 클러스터로 전송되는 경우를 방지합니다.
Aurora 전역 데이터베이스의 모든 보조 Aurora DB 클러스터에 대한 지연 시간을 확인합니다. 모든 Aurora PostgreSQL 기반 글로벌 데이터베이스 및 엔진 버전 3.04.0 이상 또는 2.12.0 이상으로 시작하는 Aurora MySQL 기반 글로벌 데이터베이스의 경우 Amazon CloudWatch를 사용하여 모든 보조 DB 클러스터에 대한
AuroraGlobalDBRPOLag지표를 확인하세요. 하위 마이너 버전의 Aurora MySQL 기반 글로벌 데이터베이스의 경우에는AuroraGlobalDBReplicationLag지표를 확인하세요. 이 지표를 통해 보조 DB 클러스터가 기본 DB 클러스터에 비해 얼마나 뒤처져 있는지(밀리초 단위) 알 수 있습니다. 이 값은 Aurora가 전환을 완료하는 데 걸리는 시간에 직접적으로 비례합니다. 따라서 지연 값이 클수록 전환 시간이 더 오래 걸립니다.CloudWatch의 Aurora 지표에 대한 자세한 내용은 Amazon Aurora에 대한 클러스터 수준 지표 단원을 참조하세요.
전환 중에, 선택한 보조 DB 클러스터가 기본 DB 클러스터처럼 새 역할로 승격됩니다. 하지만 기본 DB 클러스터의 다양한 구성 옵션은 상속되지 않습니다. 구성이 일치하지 않으면 성능 문제, 워크로드 비호환성, 기타 비정상적인 동작이 발생할 수 있습니다. 이러한 문제를 방지하려면, 다음에 대해 Aurora 전역 데이터베이스 클러스터 간의 차이점을 해결하는 것이 좋습니다.
필요한 경우 새 기본 클러스터에 대한 DB 클러스터 파라미터 그룹 Aurora구성 – Aurora 전역 데이터베이스의 각 Aurora 클러스터에 대해 Aurora DB 클러스터 파라미터 그룹을 개별적으로 구성할 수 있습니다. 즉, 보조 DB 클러스터가 기본 클러스터 역할을 맡도록 승격되면 보조 클러스터의 파라미터 그룹이 기본 클러스터와 다르게 구성될 수 있습니다. 그런 경우, 승격된 보조 DB 클러스터의 파라미터 그룹을 기본 클러스터의 설정에 맞게 수정합니다. 자세한 방법은 Aurora 글로벌 데이터베이스에 대한 파라미터 수정 단원을 참조하십시오.
Amazon CloudWatch Events 및 경보 등의 모니터링 도구 및 옵션 구성 – 승격된 DB 클러스터를 전역 데이터베이스에 필요한 것과 동일한 로깅 기능, 경보 등으로 구성합니다. 파라미터 그룹과 마찬가지로, 이러한 기능에 대한 구성은 전환 프로세스 중에 기본 클러스터에서 상속되지 않습니다. 복제 지연과 같은 일부 CloudWatch 지표는 보조 리전에서만 사용할 수 있습니다. 따라서 전환으로 인해 해당 지표를 보고 경보를 설정하는 방법이 달라짐에 따라 사전 정의된 대시보드를 변경해야 할 수도 있습니다. Aurora DB 클러스터 및 모니터링에 대한 자세한 내용은 Amazon Aurora 모니터링 개요를 참조하세요.
다른 AWS 서비스와의 통합 구성 - Aurora 글로벌 데이터베이스가 AWS Secrets Manager, AWS Identity and Access Management, Amazon S3 및 AWS Lambda 등의 AWS 서비스와 통합되는 경우, 필요에 따라 이러한 서비스와의 통합이 구성되어 있는지 확인해야 합니다. Aurora 전역 데이터베이스를 IAM, Amazon S3, Lambda과(와) 통합하는 방법에 대한 자세한 내용은 다른 AWS 서비스와 함께 Amazon Aurora Global Database 사용 섹션을 참조하세요. Secrets Manager에 대한 자세한 내용은 AWS 리전에 걸쳐 AWS Secrets Manager에서 비밀 복제를 자동화하는 방법
을 참조하세요.
참고
일반적으로 역할 전환에는 최대 몇 분이 걸릴 수 있습니다. 하지만 보조 클러스터를 추가로 구축하는 데는 데이터베이스 크기와 리전 간의 실제 거리에 따라 몇 분에서 몇 시간이 걸릴 수 있습니다.
전환 프로세스가 완료되면 승격된 Aurora DB 클러스터에서 Aurora 글로벌 데이터베이스에 대한 쓰기 작업을 처리할 수 있습니다. 애플리케이션의 엔드포인트를 변경하여 새 엔드포인트를 사용할 수 있는지 확인하세요. Aurora 전역 데이터베이스를 생성할 때 제공된 이름을 수락한 경우, 애플리케이션에 있는 승격된 클러스터의 엔드포인트 문자열에서 -ro을(를) 제거하여 엔드포인트를 변경할 수 있습니다.
예를 들어, 보조 클러스터의 엔드포인트 my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com은(는) 해당 클러스터가 기본 클러스터로 승격될 때 my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com이(가) 됩니다.
RDS 프록시를 사용하는 경우, 애플리케이션의 쓰기 작업을 새 기본 클러스터와 연결된 프록시의 적절한 읽기/쓰기 엔드포인트로 리디렉션해야 합니다. 이 프록시 엔드포인트는 기본 엔드포인트이거나 사용자 지정 읽기/쓰기 엔드포인트일 수 있습니다. 자세한 정보는 RDS 프록시 엔드포인트가 글로벌 데이터베이스에서 작동하는 방식 섹션을 참조하세요.
AWS Management Console, AWS CLI 또는 RDS API를 사용하여 Aurora 글로벌 데이터베이스를 장애 조치할 수 있습니다.
Aurora 글로벌 데이터베이스에서 전환을 수행하는 방법
https://console.aws.amazon.com/rds/
에서 AWS Management Console에 로그인한 후 Amazon RDS 콘솔을 엽니다. 데이터베이스를 선택하고 전환하려는 Aurora 글로벌 데이터베이스를 찾습니다.
작업 메뉴에서 글로벌 데이터베이스 전환 또는 장애 조치를 선택합니다.
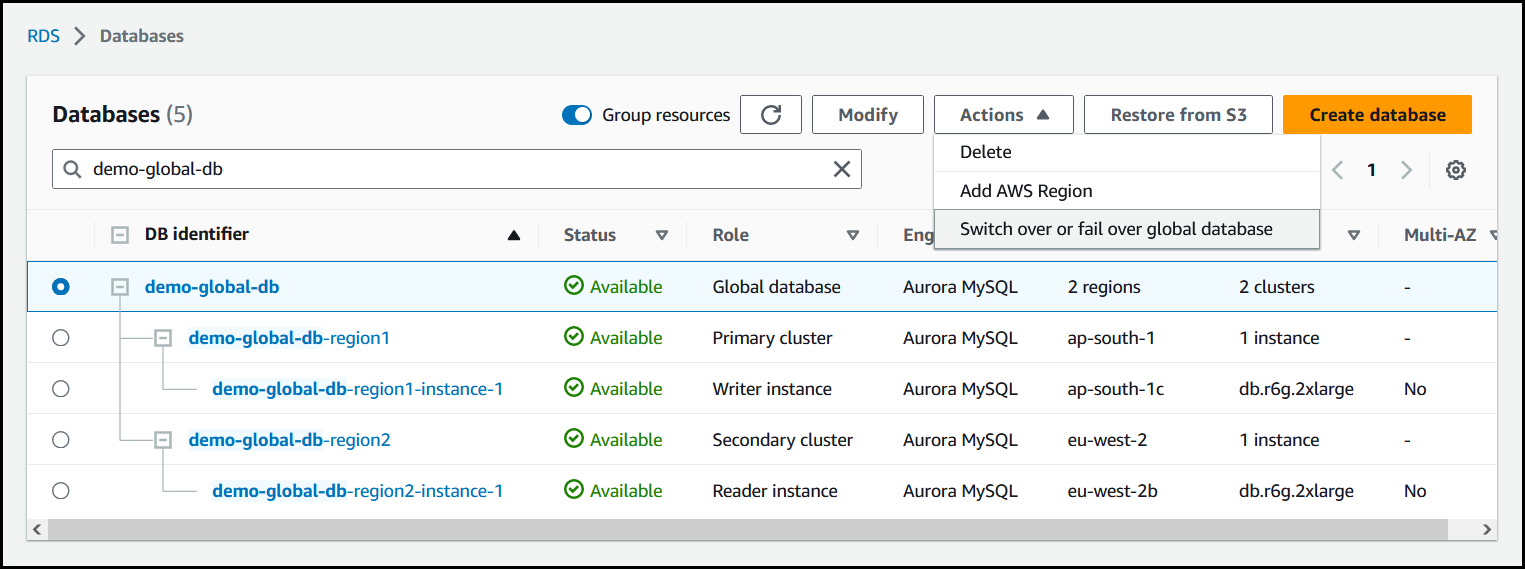
전환을 선택합니다.

새 기본 클러스터에서 보조 AWS 리전 중 하나의 활성 클러스터를 새 기본 클러스터로 선택합니다.
확인을 선택합니다.
전환이 완료되면 다음 이미지와 같이 데이터베이스 목록에서 Aurora DB 클러스터와 해당 클러스터의 현재 상태를 확인할 수 있습니다.
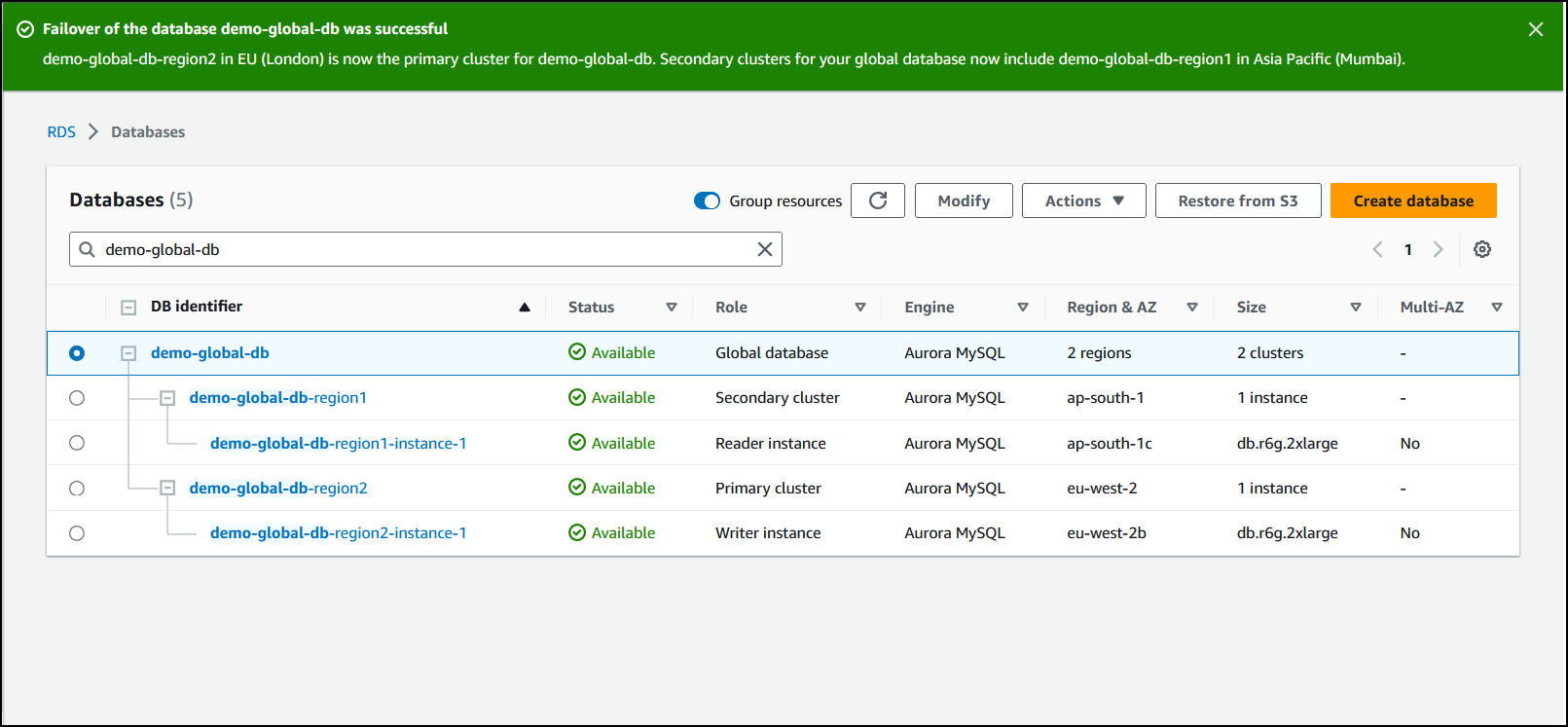
Aurora 글로벌 데이터베이스에서 전환을 수행하는 방법
switchover-global-cluster CLI 명령을 사용하여 Aurora 글로벌 데이터베이스를 장애 조치합니다. 명령을 사용하여 다음 파라미터에 대한 값을 전달합니다.
-
--region– Aurora Global Database의 기본 DB 클러스터가 실행 중인 AWS 리전을 지정합니다. --global-cluster-identifier– Aurora 전역 데이터베이스의 이름을 지정합니다.--target-db-cluster-identifier– Aurora 전역 데이터베이스의 기본 클러스터로 승격시킬 Aurora DB 클러스터의 Amazon 리소스 이름(ARN)을 지정합니다.
대상 LinuxmacOS, 또는Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Windows의 경우:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Aurora 글로벌 데이터베이스를 전환하려면 SwitchoverGlobalCluster API 작업을 실행합니다.
Aurora PostgreSQL–기반 전역 데이터베이스에 대한 RPO 관리
Aurora PostgreSQL 기반 글로벌 데이터베이스를 사용하면 rds.global_db_rpo 파라미터를 사용하여 Aurora 글로벌 데이터베이스의 Recovery Point Objective(RPO)를 관리할 수 있습니다. RPO는 중단 이벤트로 인해 손실될 수 있는 최대 데이터 양을 나타냅니다.
Aurora PostgreSQL–기반 전역 데이터베이스에 대한 RPO를 설정하면 Aurora은(는) 모든 보조 클러스터의 RPO 지연 시간을 모니터링하여 하나 이상의 보조 클러스터가 대상 RPO 기간 내에 있도록 합니다. RPO 지연 시간은 또 다른 시간 기반 지표입니다.
RPO는 장애 조치 후 데이터베이스가 새 AWS 리전에서 작업을 재개할 때 사용됩니다. Aurora는 다음과 같이 기본 클러스터에서 트랜잭션을 커밋(또는 차단)하기 위해 RPO 및 RPO 지연 시간을 평가합니다.
하나 이상의 보조 DB 클러스터의 RPO 지연 시간이 이 RPO보다 적은 경우 트랜잭션을 커밋합니다.
모든 보조 DB 클러스터의 RPO 지연 시간이 이 RPO보다 큰 경우 트랜잭션을 차단합니다. 또한 이벤트를 PostgreSQL 로그 파일에 기록하고 차단된 세션을 보여주는 “대기” 이벤트를 내보냅니다.
즉, 모든 보조 클러스터가 대상 RPO보다 뒤처지는 경우, Aurora은(는) 보조 클러스터 중 하나 이상이 캐치될 때까지 기본 클러스터에서 트랜잭션을 일시 중지합니다. 하나 이상의 세컨더리 데이터베이스 클러스터의 지연 시간이 이 RPO보다 적으면 즉시 일시 중지된 트랜잭션이 재개되고 다시 커밋됩니다. 결과적으로 RPO가 충족될 때까지 트랜잭션이 커밋될 수 없습니다.
rds.global_db_rpo 형식은 동적 파라미터입니다. 지연 시간이 충분히 감소할 때까지 모든 쓰기 트랜잭션이 중단되지 않도록 하려는 경우, 신속하게 재설정할 수 있습니다. 이 경우 Aurora는 잠시 대기한 후 변경 사항을 인식하고 구현합니다.
중요
리전이 두 개뿐인 글로벌 데이터베이스에서는 rds.global_db_rpo 파라미터의 기본값을 보조 리전의 파라미터 그룹에 유지하는 것이 좋습니다. 그렇지 않으면 기본 리전이 손실되어 이 리전으로 페일오버할 경우 Aurora가 트랜잭션을 일시 중지할 수 있습니다. 대신 Aurora가 이전 장애 리전에서 클러스터 재구축을 완료할 때까지 기다렸다가 이 파라미터를 변경하여 최대 RPO를 적용합니다.
이 파라미터를 다음에 설명된 대로 설정하면 해당 파라미터가 생성하는 지표도 모니터링할 수 있습니다. psql 또는 다른 도구를 사용하여 Aurora 전역 데이터베이스의 기본 DB 클러스터를 쿼리하고 Aurora PostgreSQL–기반 전역 데이터베이스 작업에 대한 자세한 정보를 얻을 수 있습니다. 자세한 방법은 Aurora PostgreSQL 기반 글로벌 데이터베이스 모니터링 단원을 참조하십시오.
복구 시점 목표 설정
rds.global_db_rpo 파라미터는 PostgreSQL 데이터베이스에 대한 RPO 설정을 제어합니다. 이 파라미터는 Aurora PostgreSQL에서 지원됩니다. rds.global_db_rpo에 대한 유효한 값의 범위는 20초~2,147,483,647초(68년)입니다. 비즈니스 요구 사항와 사용 사례에 맞는 현실적인 값을 선택하세요. 예를 들어, RPO에 대해 최대 10분 허용할 수 있습니다. 이 경우, 값을 600으로 설정합니다.
AWS Management Console, AWS CLI 또는 RDS API를 사용하여 Aurora PostgreSQL–기반 글로벌 데이터베이스에 대해 이 값을 설정할 수 있습니다.
RPO를 설정하려면
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. -
Aurora 전역 데이터베이스의 기본 클러스터를 선택하고 구성 탭을 열어 DB 클러스터 파라미터 그룹을 찾습니다. 예를 들어, Aurora PostgreSQL 11.7을 실행하는 기본 DB 클러스터의 기본 파라미터 그룹은
default.aurora-postgresql11입니다.파라미터 그룹은 직접 편집할 수 없습니다. 대신, 다음 작업을 수행합니다.
적절한 기본 파라미터 그룹을 시작 지점으로 사용하여 사용자 지정 DB 클러스터 파라미터 그룹을 생성합니다. 예를 들어,
default.aurora-postgresql11을(를) 기반으로 사용자 지정 DB 클러스터 파라미터 그룹을 생성합니다.사용자 지정 DB 파라미터 그룹에서 사용 사례에 맞게 rds.global_db_rpo 파라미터 값을 설정합니다. 유효한 값은 20초에서 최대 정수 값인 2,147,483,647(68년)까지입니다.
수정된 DB 클러스터 파라미터 그룹을 Aurora DB 클러스터에 적용합니다.
자세한 내용은 Amazon Aurora에서 DB 클러스터 파라미터 그룹의 파라미터 수정 섹션을 참조하세요.
rds.global_db_rpo 파라미터를 설정하려면 modify-db-cluster-parameter-group CLI 명령을 사용합니다. 명령에서, 기본 클러스터의 파라미터 그룹 이름과 RPO 파라미터 값을 지정합니다.
다음 예제에서는 my_custom_global_parameter_group이라는 기본 DB 클러스터 파라미터 그룹의 RPO를 600초(10분)로 설정합니다.
대상 LinuxmacOS, 또는Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Windows의 경우:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
rds.global_db_rpo 파라미터를 수정하려면 Amazon RDS ModifyDBClusterParameterGroup API 작업을 사용합니다.
복구 시점 목표 보기
전역 데이터베이스의 RPO(복구 지점 목표)는 각 DB 클러스터의 rds.global_db_rpo 파라미터에 저장됩니다. 보려고 하는 보조 클러스터의 엔드포인트에 연결하고 이 값에 대해 인스턴스를 쿼리하는 데 psql을(를) 사용할 수 있습니다.
show rds.global_db_rpo;db-name=>
이 파라미터를 설정하지 않으면 쿼리에서 다음을 반환합니다.
rds.global_db_rpo
-------------------
-1
(1 row)다음 응답은 1분 RPO 설정이 있는 보조 DB 클러스터에서 온 것입니다.
rds.global_db_rpo
-------------------
60
(1 row)클러스터의 모든 rds.global_db_rpo 파라미터 값을 가져오기 위해 CLI를 사용하여 Aurora DB 클러스터에서 user이(가) 활성 상태인지 확인할 수 있는 값을 가져올 수도 있습니다.
대상 LinuxmacOS, 또는Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Windows의 경우:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
이 명령은 모든 user 파라미터에 대해 다음과 유사한 출력을 반환합니다. 이는 default-engine 또는 system DB 클러스터 파라미터가 아닙니다.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}클러스터 파라미터 그룹의 파라미터 보기에 대한 자세한 내용은 Amazon Aurora에서 DB 클러스터 파라미터 그룹의 파라미터 값 보기 단원을 참조하세요.
복구 시점 목표 비활성화
RPO를 비활성화하려면 rds.global_db_rpo 파라미터를 재설정합니다. AWS Management Console, AWS CLI 또는 RDS API를 사용하여 파라미터를 재설정할 수 있습니다.
RPO를 비활성화하려면
AWS Management Console에 로그인한 후 https://console.aws.amazon.com/rds/
에서 Amazon RDS 콘솔을 엽니다. -
탐색 창에서 파라미터 그룹을 선택합니다.
-
목록에서 기본 DB 클러스터 파라미터 그룹을 선택합니다.
-
파라미터 편집을 선택합니다.
-
rds.global_db_rpo 파라미터 옆의 상자를 선택합니다.
-
재설정을 선택합니다.
-
화면에 DB 파라미터 그룹의 파라미터 재설정이 표시되면 파라미터 재설정을 선택합니다.
콘솔에서 파라미터를 재설정하는 방법에 대한 자세한 내용은 Amazon Aurora에서 DB 클러스터 파라미터 그룹의 파라미터 수정 단원을 참조하십시오.
rds.global_db_rpo 파라미터를 재설정하려면 reset-db-cluster-parameter-group 명령을 사용합니다.
대상 LinuxmacOS, 또는Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Windows의 경우:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
rds.global_db_rpo 파라미터를 재설정하려면 Amazon RDS API ResetDBClusterParameterGroup 작업을 사용합니다.
