Amazon S3 데이터에서 데이터 가져오기 개요
S3 데이터를 Amazon RDS로 가져오려면
먼저 함수에 제공해야 하는 세부 정보를 수집합니다. 여기에는 RDS for PostgreSQL DB 인스턴스의 테이블 이름과 버킷 이름, 파일 경로, 파일 유형 및 Amazon S3 데이터가 저장된 AWS 리전이 포함됩니다. 자세한 내용은 Amazon Simple Storage Service 사용 설명서의 객체 보기를 참조하세요.
참고
Amazon S3에서 멀티 파트 데이터 가져오기는 현재 지원되지 않습니다.
aws_s3.table_import_from_s3함수가 데이터를 가져올 테이블의 이름을 가져옵니다. 예를 들어 다음 명령은 이후 단계에서 사용할 수 있는 테이블t1을 만듭니다.postgres=>CREATE TABLE t1 (col1 varchar(80), col2 varchar(80), col3 varchar(80));Amazon S3 버킷 및 가져올 데이터에 대한 세부 정보를 가져옵니다. 이 작업을 수행하려면 https://console.aws.amazon.com/s3/
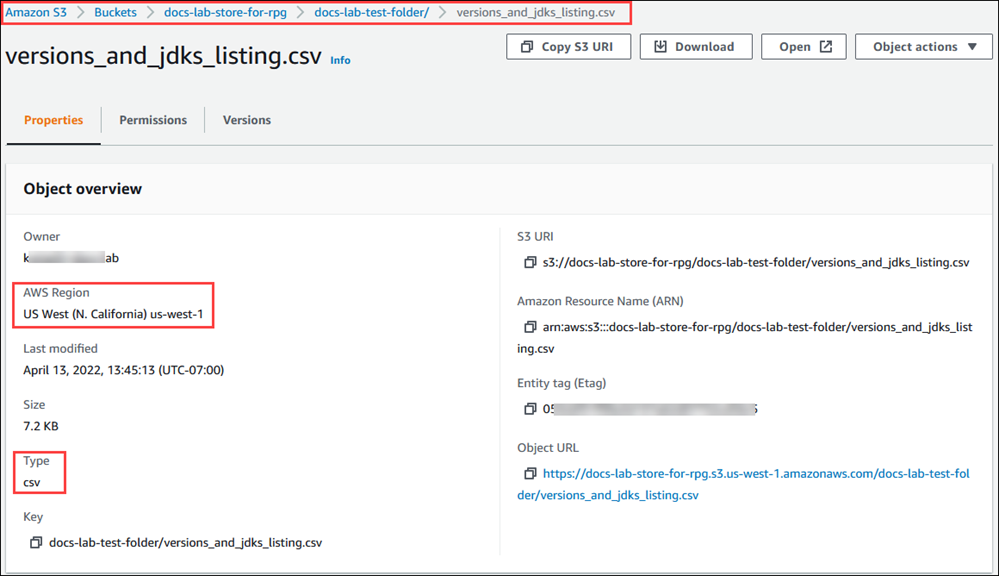
에서 Amazon S3 콘손을 열고 버킷을 선택합니다. 목록에서 데이터가 포함된 버킷을 찾습니다. 버킷을 선택하고 객체 개요 페이지를 연 다음 속성을 선택합니다. 버킷 이름, 경로, AWS 리전, 파일 형식을 적어 둡니다. IAM 역할을 통해 Amazon S3에 대한 액세스를 설정하는 Amazon 리소스 이름(ARN) 이 나중에 필요합니다. 자세한 내용은 Amazon S3 버킷에 대한 액세스 권한 설정 단원을 참조하세요. 다음 그림에 예가 나와 있습니다.
AWS CLI 명령
aws s3 cp를 사용하여 Amazon S3 버킷의 데이터 경로를 확인할 수 있습니다. 정보가 정확하면 이 명령이 Amazon S3 파일의 복사본을 다운로드합니다.aws s3 cp s3://amzn-s3-demo-bucket/sample_file_path./-
Amazon S3 버킷의 파일에 대한 액세스를 허용하도록 RDS for PostgreSQL DB 인스턴스에 대한 권한을 설정합니다. 이렇게 하려면 AWS Identity and Access Management(IAM) 역할 또는 보안 자격 증명을 사용합니다. 자세한 내용은 Amazon S3 버킷에 대한 액세스 권한 설정 단원을 참조하세요.
경로 및 수집된 기타 Amazon S3 객체 세부 정보(2단계 참조)를
create_s3_uri함수에 제공하여 Amazon S3 URI 객체를 생성합니다. 이 함수에 대한 자세한 내용은 aws_commons.create_s3_uri 단원을 참조하세요. 다음은 psql 세션 중에 이 객체를 구성하는 예입니다.postgres=>SELECT aws_commons.create_s3_uri( 'docs-lab-store-for-rpg', 'versions_and_jdks_listing.csv', 'us-west-1' ) AS s3_uri \gset다음 단계에서는 이 객체(
aws_commons._s3_uri_1)를aws_s3.table_import_from_s3함수에 전달하여 데이터를 테이블로 가져옵니다.-
aws_s3.table_import_from_s3함수를 호출하여 Amazon S3에서 테이블로 데이터를 가져옵니다. 참조 정보는 aws_s3.table_import_from_s3 단원을 참조하세요. 예시는 Amazon S3에서 RDS for PostgreSQL DB 인스턴스로 데이터 가져오기 섹션을 참조하세요.
