Oracle 전송 가능한 테이블스페이스를 사용한 마이그레이션
Oracle 전송 가능한 테이블스페이스 기능을 사용하여 온프레미스 Oracle 데이터베이스의 테이블스페이스 세트를 RDS for Oracle DB 인스턴스로 복사할 수 있습니다. 물리적 수준에서 Amazon EFS 또는 Amazon S3를 사용하여 소스 데이터 파일과 메타데이터 파일을 대상 DB 인스턴스에 전송합니다. 전송 가능한 테이블스페이스 기능은 rdsadmin.rdsadmin_transport_util 패키지를 사용합니다. 이 패키지의 구문 및 의미는 테이블스페이스 전송 섹션을 참조하세요.
테이블스페이스를 전송하는 방법을 설명하는 블로그 게시물은 전송 가능한 테이블스페이스를 사용하도록 Oracle 데이터베이스를 AWS로 마이그레이션
주제
Oracle 전송 가능한 테이블스페이스 개요
전송 가능한 테이블스페이스 세트는 전송 중인 테이블스페이스 세트에 대한 데이터 파일과 테이블스페이스 메타데이터를 포함하는 내보내기 덤프 파일로 구성됩니다. 전송 가능한 테이블스페이스와 같은 물리적 마이그레이션 솔루션에서는 데이터 파일, 구성 파일 및 Data Pump 덤프 파일과 같은 물리적 파일을 전송합니다.
전송 가능한 테이블스페이스의 장점 및 단점
가동 중지 시간을 최소화하면서 하나 이상의 대규모 테이블스페이스를 RDS로 마이그레이션해야 하는 경우 전송 가능한 테이블스페이스를 사용하는 것이 좋습니다. 전송 가능한 테이블스페이스에는 논리적 마이그레이션에 비해 다음과 같은 이점이 있습니다.
-
대부분의 다른 Oracle 마이그레이션 솔루션보다 가동 중지 시간이 짧습니다.
-
전송 가능한 테이블스페이스 기능은 물리적 파일만 복사하므로 논리적 마이그레이션에서 발생할 수 있는 데이터 무결성 오류와 논리적 손상을 방지합니다.
-
추가 라이선스가 필요하지 않습니다.
-
예를 들어 Oracle Solaris 플랫폼에서 Linux로 마이그레이션하는 등 다양한 플랫폼 및 엔디안(endianness) 유형 간에 테이블스페이스 세트를 마이그레이션할 수 있습니다. 하지만 Windows 서버 간에 테이블스페이스를 주고받는 것은 지원되지 않습니다.
참고
Linux는 완벽하게 테스트되고 지원됩니다. 일부 UNIX 버전은 테스트되지 않았습니다.
전송 가능한 테이블스페이스를 사용하는 경우 Amazon S3 또는 Amazon EFS를 사용하여 데이터를 전송할 수 있습니다.
-
EFS를 사용하는 경우 백업은 가져오는 동안 EFS 파일 시스템에 남아 있습니다. 나중에 파일을 제거할 수 있습니다. 이 기법에서는 DB 인스턴스에 EBS 스토리지를 프로비저닝할 필요가 없습니다. 따라서 S3 대신 Amazon EFS를 사용하는 것이 좋습니다. 자세한 내용은 Amazon EFS 통합 섹션을 참조하세요.
-
S3를 사용하는 경우 DB 인스턴스에 연결된 EBS 스토리지에 RMAN 백업을 다운로드합니다. 가져오는 동안 파일은 EBS 스토리지에 남아 있습니다. 가져온 후에는 DB 인스턴스에 할당된 상태로 남아 있는 이 공간을 비워 여유 공간을 확보할 수 있습니다.
전송 가능한 테이블스페이스의 주요 단점은 Oracle Database에 대해 비교적 높은 수준의 지식이 필요하다는 것입니다. 자세한 내용은 Oracle Database 관리자 안내서의 데이터베이스 간 테이블스페이스 전송
전송 가능한 테이블스페이스의 제한 사항
RDS for Oracle에서 이 기능을 사용하는 경우 전송 가능한 테이블스페이스에 대한 Oracle Database 제한 사항이 적용됩니다. 자세한 내용은 Oracle Database 관리자 안내서의 전송 가능한 테이블스페이스 제한 사항
-
소스 데이터베이스와 대상 데이터베이스 모두 Standard Edition 2(SE2)를 사용할 수 없습니다. Enterprise Edition만 지원됩니다.
-
Oracle Database 11g 데이터베이스를 소스로 사용할 수 없습니다. RMAN 크로스 플랫폼 전송 가능한 테이블스페이스 기능은 Oracle Database 11g에서 지원하지 않는 RMAN 전송 메커니즘을 사용합니다.
-
전송 가능한 테이블스페이스를 사용하여 RDS for Oracle DB 인스턴스에서 데이터를 마이그레이션할 수 없습니다. RDS for Oracle DB 인스턴스로 데이터를 마이그레이션하는 경우에만 전송 가능한 테이블스페이스를 사용할 수 있습니다.
-
Windows 운영 체제는 지원되지 않습니다.
-
하위 릴리스 수준에서는 테이블스페이스를 데이터베이스로 전송할 수 없습니다. 대상 데이터베이스는 릴리스 수준이 소스 데이터베이스 이상이어야 합니다. 예를 들어 Oracle Database 21c에서 Oracle Database 19c로 테이블스페이스를 전송할 수 없습니다.
-
SYSTEM및SYSAUX와 같은 관리 테이블스페이스는 전송할 수 없습니다. -
PL/SQL 패키지, Java 클래스, 뷰, 트리거, 시퀀스, 사용자, 역할 및 임시 테이블과 같은 비데이터 객체는 전송할 수 없습니다. 비데이터 객체를 전송하려면 객체를 수동으로 만들거나 Data Pump 메타데이터 내보내기 및 가져오기를 사용하세요. 자세한 내용은 내 Oracle 지원 노트 1454872.1
을 참조하세요. -
암호화된 테이블스페이스 또는 암호화된 열을 사용하는 테이블스페이스를 전송할 수 없습니다.
-
Amazon S3를 사용하여 파일을 전송하는 경우 지원되는 최대 파일 크기는 5TiB입니다.
-
소스 데이터베이스에서 Spatial과 같은 Oracle 옵션을 사용하는 경우 대상 데이터베이스에 동일한 옵션이 구성되어 있지 않으면 테이블스페이스를 전송할 수 없습니다.
-
Oracle 복제본 구성에서는 테이블스페이스를 RDS for Oracle DB 인스턴스로 전송할 수 없습니다. 이 문제를 해결하려면 모든 복제본을 삭제하고 테이블스페이스를 전송한 다음 복제본을 다시 생성하면 됩니다.
전송 가능한 테이블스페이스의 사전 요구 사항
시작하기 전에 다음 작업을 완료하세요.
-
My Oracle Support의 다음 문서에 설명된 전송 가능한 테이블스페이스의 요구 사항을 검토하세요.
-
엔디안 변환을 계획하세요. 소스 플랫폼 ID를 지정하는 경우 RDS for Oracle은 엔디안을 자동으로 변환합니다. 플랫폼 ID를 찾는 방법을 알아보려면 동일한 Data Guard 구성의 이기종 기본 및 물리적 대기에 대한 Data Guard 지원(문서 ID 413484.1)
을 참조하세요. -
대상 DB 인스턴스에서 전송 가능한 테이블스페이스 기능이 사용 설정되어 있는지 확인하세요. 이 기능은 다음 쿼리를 실행할 때
ORA-20304오류가 발생하지 않는 경우에만 사용 설정됩니다.SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files);전송 가능한 테이블스페이스 기능이 사용 설정되지 않았으면 DB 인스턴스를 재부팅하세요. 자세한 내용은 DB 인스턴스 재부팅 섹션을 참조하세요.
-
소스 및 대상 데이터베이스에서 시간대 파일이 동일한지 확인합니다.
-
소스 및 대상 데이터베이스의 데이터베이스 문자 세트가 다음 요구 사항 중 하나를 충족하는지 확인합니다.
-
문자 세트가 동일해야 합니다.
-
문자 세트가 호환되어야 합니다. 호환성 요구 사항 목록은 Oracle Database 설명서의 General Limitations on Transporting Data
를 참조하세요.
-
-
Amazon S3를 사용하여 파일을 전송하려는 경우 다음을 수행하세요.
-
파일 전송에 Amazon S3 버킷을 사용할 수 있고 Amazon S3 버킷이 DB 인스턴스와 동일한 AWS 리전에 있어야 합니다. 지침을 보려면 Amazon Simple Storage Service 시작 안내서에서 버킷 생성을 참조하세요.
-
Amazon S3와 RDS for Oracle 통합을 위한 IAM 권한 구성의 지침에 따라 Amazon RDS 통합을 위해 Amazon S3 버킷을 준비해야 합니다.
-
-
Amazon EFS를 사용하여 파일을 전송하려는 경우 Amazon EFS 통합의 지침에 따라 EFS를 구성해야 합니다.
-
대상 DB 인스턴스에서 자동 백업을 켜는 것이 좋습니다. 메타데이터 가져오기 단계가 실패할 수 있으므로 DB 인스턴스를 가져오기 전 상태로 복원할 수 있어야 합니다. 그러면 테이블스페이스를 다시 백업하고 전송하고 가져올 필요가 없습니다.
1단계: 소스 호스트 설정
이 단계에서는 My Oracle Support에서 제공하는 전송 테이블스페이스 스크립트를 복사하고 필요한 구성 파일을 설정합니다. 다음 단계에서는 소스 호스트가 대상 인스턴스로 전송할 테이블스페이스가 포함된 데이터베이스를 실행하고 있습니다.
소스 호스트를 설정하는 방법
-
소스 호스트에 Oracle 홈의 소유자로 로그인합니다.
-
ORACLE_HOME및ORACLE_SID환경 변수가 소스 데이터베이스를 가리키는지 확인합니다. -
데이터베이스에 관리자로 로그인하고 시간대 버전, DB 문자 세트 및 국가 문자 세트가 대상 데이터베이스와 동일한지 확인합니다.
SELECT * FROM V$TIMEZONE_FILE; SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER IN ('NLS_CHARACTERSET','NLS_NCHAR_CHARACTERSET'); -
Oracle Support 노트 2471245.1
에 설명된 대로 전송 가능한 테이블스페이스 유틸리티를 설정합니다. 설정에는 소스 호스트의
xtt.properties파일 편집이 포함됩니다. 다음 샘플xtt.properties파일은/dsk1/backups디렉터리에 있는 세 개의 테이블스페이스에 대한 백업을 지정합니다. 이는 대상 DB 인스턴스로 전송하려는 테이블스페이스입니다. 또한 엔디안을 자동으로 변환할 소스 플랫폼 ID를 지정합니다.참고
유효한 플랫폼 ID 정보는 동일한 Data Guard 구성의 이기종 기본 및 물리적 대기에 대한 Data Guard 지원(문서 ID 413484.1)
을 참조하세요. #linux system platformid=13#list of tablespaces to transport tablespaces=TBS1,TBS2,TBS3#location where backup will be generated src_scratch_location=/dsk1/backups#RMAN command for performing backup usermantransport=1
2단계: 전체 테이블스페이스 백업 준비
이 단계에서는 테이블스페이스를 처음으로 백업하고 대상 호스트로 백업을 전송한 다음, rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces 프로시저에 따라 테이블스페이스를 복원합니다. 이 단계가 완료되면 초기 테이블스페이스 백업이 대상 DB 인스턴스에 상주하며 증분 백업으로 업데이트할 수 있습니다.
1단계: 소스 호스트의 테이블스페이스 백업
이 단계에서는 xttdriver.pl 스크립트를 사용하여 테이블스페이스의 전체 백업을 만듭니다. xttdriver.pl의 출력은 TMPDIR 환경 변수에 저장됩니다.
테이블스페이스를 백업하는 방법
-
테이블스페이스가 읽기 전용 모드인 경우
ALTER TABLESPACE권한이 있는 사용자로 소스 데이터베이스에 로그인하고 테이블스페이스를 읽기/쓰기 모드로 설정합니다. 그렇지 않은 경우 다음 단계로 건너뜁니다.다음 예에서는
tbs1,tbs2및tbs3를 읽기/쓰기 모드로 설정합니다.ALTER TABLESPACE tbs1 READ WRITE; ALTER TABLESPACE tbs2 READ WRITE; ALTER TABLESPACE tbs3 READ WRITE; -
xttdriver.pl스크립트를 사용하여 테이블스페이스를 백업합니다. 선택적으로 스크립트를 디버그 모드에서 실행하도록--debug를 지정할 수 있습니다.export TMPDIR=location_of_log_filescdlocation_of_xttdriver.pl$ORACLE_HOME/perl/bin/perl xttdriver.pl --backup
2단계: 백업 파일을 대상 DB 인스턴스로 전송
이 단계에서는 스크래치 위치에서 백업 및 구성 파일을 대상 DB 인스턴스로 복사합니다. 다음 옵션 중 하나를 선택하세요.
-
소스 및 대상 호스트가 Amazon EFS 파일 시스템을 공유하는 경우
cp등의 운영 체제 유틸리티를 사용하여 스크래치 위치에서 백업 파일과res.txt파일을 공유 디렉터리로 복사합니다. 3단계: 대상 DB 인스턴스에 테이블스페이스 가져오기 단원을 참조하세요. -
Amazon S3 버킷으로 백업을 스테이징해야 하는 경우 다음 단계를 완료하세요.
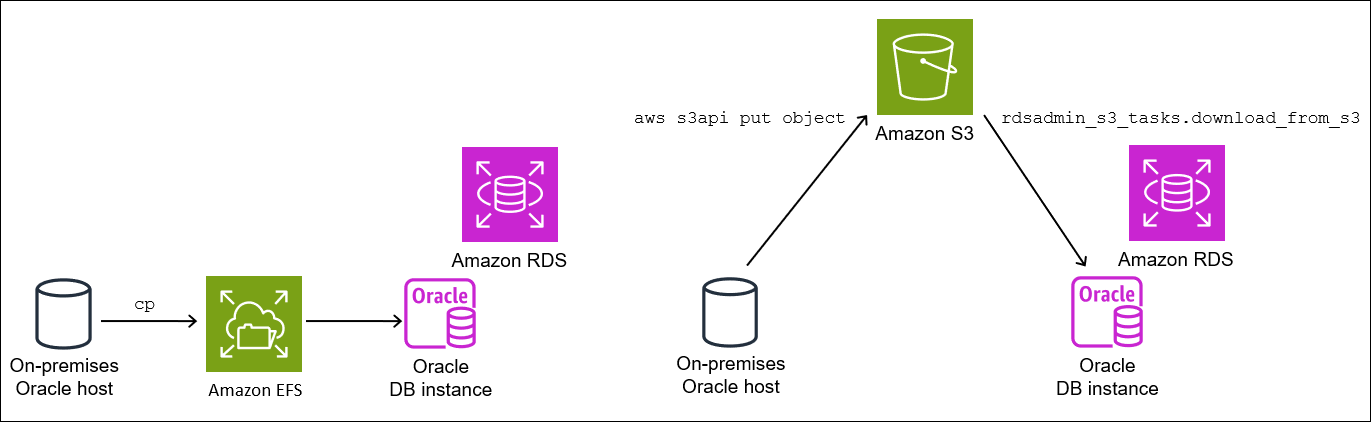
2.2단계: 백업을 Amazon S3 버킷에 업로드
스크래치 디렉터리의 백업과 res.txt 파일을 Amazon S3 버킷에 업로드합니다. 자세한 내용은 Amazon Simple Storage Service 사용 설명서의 객체 업로드를 참조하세요.
2.3단계: Amazon S3 버킷에서 대상 DB 인스턴스로 백업 다운로드
이 단계에서는 rdsadmin.rdsadmin_s3_tasks.download_from_s3 프로시저를 사용하여 RDS for Oracle DB 인스턴스에 백업을 다운로드합니다.
Amazon S3 버킷에서 백업을 다운로드하는 방법
-
SQL*Plus 또는 Oracle SQL Developer를 시작하고 RDS for Oracle DB 인스턴스에 로그인합니다.
-
Amazon S3 버킷에서 DB 인스턴스로 파일을 다운로드하는 Amazon RDS 프로시저
rdsadmin.rdsadmin_s3_tasks.download_from_s3를 사용하여 Amazon S3 버킷에서 대상 DB 인스턴스로 백업을 다운로드합니다. 다음 예제에서는amzn-s3-demo-bucketDATA_PUMP_DIREXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'res.txt'); SELECT rdsadmin.rdsadmin_s3_tasks.download_from_s3( p_bucket_name => 'amzn-s3-demo-bucket', p_directory_name => 'DATA_PUMP_DIR') AS TASK_ID FROM DUAL;SELECT문은VARCHAR2데이터 형식으로 작업 ID를 반환합니다. 자세한 내용은 Amazon S3 버킷의 파일을 Oracle DB 인스턴스로 다운로드 섹션을 참조하세요.
3단계: 대상 DB 인스턴스에 테이블스페이스 가져오기
테이블스페이스를 대상 DB 인스턴스로 복원하려면 rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces 프로시저를 사용합니다. 이 프로시저는 데이터 파일을 올바른 엔디안(endian) 형식으로 자동 변환합니다.
Linux 이외의 플랫폼에서 가져오는 경우 import_xtts_tablespaces 호출 시 p_platform_id 파라미터를 사용하여 소스 플랫폼을 지정합니다. 지정하는 플랫폼 ID가 2단계: 소스 호스트의 테이블스페이스 메타데이터 내보내기의 xtt.properties 파일에서 지정하는 ID와 일치해야 합니다.
대상 DB 인스턴스에 테이블스페이스 가져오기
-
Oracle SQL 클라이언트를 시작하고 마스터 사용자로 대상 RDS for Oracle DB 인스턴스에 로그인합니다.
-
가져올 테이블스페이스와 백업이 포함된 디렉터리를 지정하여
rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces프로시저를 실행합니다.다음 예에서는
DATA_PUMP_DIR디렉터리에서TBS1,TBS2및TBS3테이블스페이스를 가져옵니다. 소스 플랫폼은 플랫폼 ID가6인 AIX 기반 시스템(64비트)입니다.V$TRANSPORTABLE_PLATFORM쿼리를 통해 플랫폼 ID를 찾을 수 있습니다.VAR task_id CLOB BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces( 'TBS1,TBS2,TBS3', 'DATA_PUMP_DIR', p_platform_id => 6); END; / PRINT task_id -
(선택 사항)
rdsadmin.rds_xtts_operation_info테이블을 쿼리하여 진행 상황을 모니터링합니다.xtts_operation_state열에는EXECUTING,COMPLETED또는FAILED값이 표시됩니다.SELECT * FROM rdsadmin.rds_xtts_operation_info;참고
장기 실행 작업의 경우
V$SESSION_LONGOPS,V$RMAN_STATUS및V$RMAN_OUTPUT을 쿼리할 수도 있습니다. -
이전 단계의 작업 ID를 사용하여 완료된 가져오기의 로그를 확인합니다.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));다음 단계로 이동하기 전에 가져오기가 성공적으로 완료되었는지 확인합니다.
3단계: 증분 백업 생성 및 전송
이 단계에서는 소스 데이터베이스가 활성 상태인 동안 정기적으로 증분 백업을 만들어 전송합니다. 이 방법을 사용하면 최종 테이블스페이스 백업의 크기가 줄어듭니다. 증분 백업을 여러 개 수행하는 경우 대상 인스턴스에 적용하려면 먼저 마지막 증분 백업 이후에 res.txt 파일을 복사해야 합니다.
가져오기 단계가 선택 사항이라는 점을 제외하고 단계는 2단계: 전체 테이블스페이스 백업 준비와 동일합니다.
4단계: 테이블스페이스 전송
이 단계에서는 읽기 전용 테이블스페이스를 백업하고 Data Pump 메타데이터를 내보내고 이러한 파일을 대상 호스트로 전송하고 테이블스페이스와 메타데이터를 모두 가져옵니다.
주제
1단계: 읽기 전용 테이블스페이스 백업
이 단계는 1단계: 소스 호스트의 테이블스페이스 백업과 동일하지만 한 가지 차이점은 테이블스페이스를 마지막으로 백업하기 전에 테이블스페이스를 읽기 전용 모드로 설정한다는 점입니다.
다음 예에서는 tbs1, tbs2 및 tbs3를 읽기 전용 모드로 설정합니다.
중요
테이블스페이스를 읽기 전용 모드로 설정하면 마이그레이션 가동 중지 시간이 시작됩니다. 이 시점부터 애플리케이션은 소스 데이터베이스의 이러한 테이블스페이스에 쓸 수 없습니다. 유지 관리 기간 동안 이 단계를 계획합니다.
ALTER TABLESPACE tbs1 READ ONLY; ALTER TABLESPACE tbs2 READ ONLY; ALTER TABLESPACE tbs3 READ ONLY;
2단계: 소스 호스트의 테이블스페이스 메타데이터 내보내기
소스 호스트에서 expdp 유틸리티를 실행하여 테이블스페이스 메타데이터를 내보냅니다. 다음 예에서는 DATA_PUMP_DIR 디렉터리의 TBS1, TBS2, TBS3 테이블스페이스를 xttdump.dmp 덤프 파일로 내보냅니다.
expdpusername/pwd\ dumpfile=xttdump.dmp\ directory=DATA_PUMP_DIR\ statistics=NONE \ transport_tablespaces=TBS1,TBS2,TBS3\ transport_full_check=y \ logfile=tts_export.log
DATA_PUMP_DIR이 Amazon EFS의 공유 디렉터리인 경우 4단계: 대상 DB 인스턴스에 테이블스페이스 가져오기로 건너뛰세요.
3단계: (Amazon S3만 해당) 백업 및 내보내기 파일을 대상 DB 인스턴스로 전송
Amazon S3를 사용하여 테이블스페이스 백업과 Data pump 내보내기 파일을 스테이징하려면 다음 단계를 완료하세요.
3.1단계: 소스 호스트에서 Amazon S3 버킷으로 백업 및 덤프 파일 업로드
소스 호스트에서 Amazon S3 버킷으로 백업 및 덤프 파일을 업로드합니다. 자세한 내용은 Amazon Simple Storage Service 사용 설명서의 객체 업로드를 참조하세요.
3.2단계: Amazon S3 버킷에서 대상 DB 인스턴스로 백업 및 덤프 파일 다운로드
이 단계에서는 rdsadmin.rdsadmin_s3_tasks.download_from_s3 프로시저를 사용하여 RDS for Oracle DB 인스턴스에 백업 및 덤프 파일을 다운로드합니다. 2.3단계: Amazon S3 버킷에서 대상 DB 인스턴스로 백업 다운로드 섹션의 단계를 따르세요.
4단계: 대상 DB 인스턴스에 테이블스페이스 가져오기
rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces 프로시저를 사용하여 테이블스페이스를 복원합니다. 이 프로시저의 구문 및 의미는 전송된 테이블스페이스를 DB 인스턴스로 가져오기 섹션을 참조하세요.
중요
최종 테이블스페이스 가져오기를 완료한 후 다음 단계는 Oracle Data Pump 메타데이터를 가져오는 것입니다. 가져오기에 실패할 경우 DB 인스턴스를 실패 이전 상태로 되돌리는 것이 중요합니다. 따라서 Amazon RDS의 단일 AZ DB 인스턴스에 대한 DB 스냅샷 생성의 지침에 따라 DB 인스턴스의 DB 스냅샷을 만드는 것이 좋습니다. 스냅샷에는 가져온 테이블스페이스가 모두 포함되므로 가져오기가 실패할 경우 백업 및 가져오기 프로세스를 반복하지 않아도 됩니다.
대상 DB 인스턴스에 자동 백업이 켜져 있는데 메타데이터를 가져오기 전에 Amazon RDS가 유효한 스냅샷이 시작되었음을 감지하지 못하면 RDS는 스냅샷 생성을 시도합니다. 인스턴스 활동에 따라 이 스냅샷은 성공하거나 실패할 수 있습니다. 유효한 스냅샷이 검색되지 않거나 스냅샷을 시작할 수 없는 경우 메타데이터 가져오기가 오류와 함께 종료됩니다.
대상 DB 인스턴스에 테이블스페이스 가져오기
-
Oracle SQL 클라이언트를 시작하고 마스터 사용자로 대상 RDS for Oracle DB 인스턴스에 로그인합니다.
-
가져올 테이블스페이스와 백업이 포함된 디렉터리를 지정하여
rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces프로시저를 실행합니다.다음 예에서는
DATA_PUMP_DIR디렉터리에서TBS1,TBS2및TBS3테이블스페이스를 가져옵니다.BEGIN :task_id:=rdsadmin.rdsadmin_transport_util.import_xtts_tablespaces('TBS1,TBS2,TBS3','DATA_PUMP_DIR'); END; / PRINT task_id -
(선택 사항)
rdsadmin.rds_xtts_operation_info테이블을 쿼리하여 진행 상황을 모니터링합니다.xtts_operation_state열에는EXECUTING,COMPLETED또는FAILED값이 표시됩니다.SELECT * FROM rdsadmin.rds_xtts_operation_info;참고
장기 실행 작업의 경우
V$SESSION_LONGOPS,V$RMAN_STATUS및V$RMAN_OUTPUT을 쿼리할 수도 있습니다. -
이전 단계의 작업 ID를 사용하여 완료된 가져오기의 로그를 확인합니다.
SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file('BDUMP', 'dbtask-'||'&task_id'||'.log'));다음 단계로 이동하기 전에 가져오기가 성공적으로 완료되었는지 확인합니다.
-
Amazon RDS의 단일 AZ DB 인스턴스에 대한 DB 스냅샷 생성의 지침에 따라 수동 DB 스냅샷을 생성합니다.
5단계: 대상 DB 인스턴스에 테이블스페이스 메타데이터 가져오기
이 단계에서는 rdsadmin.rdsadmin_transport_util.import_xtts_metadata 프로시저에 따라 전송 가능한 테이블스페이스 메타데이터를 RDS for Oracle DB 인스턴스로 가져옵니다. 이 프로시저의 구문 및 의미는 전송 가능한 테이블스페이스를 DB 인스턴스로 가져오기 섹션을 참조하세요. 작업 중에는 가져오기 상태가 rdsadmin.rds_xtts_operation_info 테이블에 표시됩니다.
중요
메타데이터를 가져오기 전에 테이블스페이스를 가져온 후 DB 스냅샷이 성공적으로 생성되었는지 확인하는 것이 좋습니다. 가져오기 단계가 실패하면 DB 인스턴스를 복원하고 가져오기 오류를 해결한 다음 가져오기를 다시 시도하세요.
RDS for Oracle DB 인스턴스로 Data Pump 메타데이터 가져오기
-
Oracle SQL 클라이언트를 시작하고 마스터 사용자로 대상 DB 인스턴스에 로그인합니다.
-
전송된 테이블스페이스에 스키마를 소유하는 사용자가 아직 없다면 생성합니다.
CREATE USERtbs_ownerIDENTIFIED BYpassword; -
덤프 파일의 이름과 디렉터리 위치를 지정하여 메타데이터를 가져옵니다.
BEGIN rdsadmin.rdsadmin_transport_util.import_xtts_metadata('xttdump.dmp','DATA_PUMP_DIR'); END; / -
(선택 사항) 전송 가능한 테이블스페이스 기록 테이블을 쿼리하여 메타데이터 가져오기 상태를 확인합니다.
SELECT * FROM rdsadmin.rds_xtts_operation_info;작업이 완료되면 테이블스페이스가 읽기 전용 모드가 됩니다.
-
(선택 사항) 로그 파일을 확인합니다.
다음 예에서는 BDUMP 디렉터리의 내용을 나열한 다음 가져오기 로그를 쿼리합니다.
SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'BDUMP')); SELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-import_xtts_metadata-2023-05-22.01-52-35.560858000.log'));
5단계: 전송된 테이블스페이스 검증
이 선택적 단계에서는 rdsadmin.rdsadmin_rman_util.validate_tablespace 프로시저를 사용하여 전송된 테이블스페이스를 검증한 다음 테이블스페이스를 읽기/쓰기 모드로 설정합니다.
전송된 데이터를 검증하는 방법
-
SQL*Plus 또는 SQL Developer를 시작하고 마스터 사용자로 대상 DB 인스턴스에 로그인합니다.
-
rdsadmin.rdsadmin_rman_util.validate_tablespace프로시저를 사용하여 테이블스페이스를 검증합니다.SET SERVEROUTPUT ON BEGIN rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS1', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS2', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); rdsadmin.rdsadmin_rman_util.validate_tablespace( p_tablespace_name => 'TBS3', p_validation_type => 'PHYSICAL+LOGICAL', p_rman_to_dbms_output => TRUE); END; / -
테이블스페이스를 읽기/쓰기 모드로 설정합니다.
ALTER TABLESPACETBS1READ WRITE; ALTER TABLESPACETBS2READ WRITE; ALTER TABLESPACETBS3READ WRITE;
6단계: 남은 파일 정리
이 선택적 단계에서는 불필요한 파일을 모두 제거합니다. rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files 프로시저를 사용하여 테이블스페이스 가져오기 후 분리된 데이터 파일을 나열한 다음, rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import 프로시저를 사용하여 삭제합니다. 이 프로시저의 구문 및 의미는 테이블스페이스 가져오기 후 분리된 파일 나열 및 테이블스페이스 가져오기 후 분리된 파일 삭제 섹션을 참조하세요.
남은 파일을 정리하는 방법
-
다음과 같이
DATA_PUMP_DIR에서 오래된 백업을 제거합니다.-
rdsadmin.rdsadmin_file_util.listdir을 실행하여 백업 파일을 나열합니다.SELECT * FROM TABLE(rdsadmin.rds_file_util.listdir(p_directory => 'DATA_PUMP_DIR')); -
UTL_FILE.FREMOVE를 호출하여 백업을 하나씩 제거합니다.EXEC UTL_FILE.FREMOVE ('DATA_PUMP_DIR', 'backup_filename');
-
-
테이블스페이스를 가져왔지만 테이블스페이스에 대한 메타데이터를 가져오지 않은 경우 다음과 같이 분리된 데이터 파일을 삭제할 수 있습니다.
-
삭제해야 하는 분리된 데이터 파일을 나열합니다. 다음 예에서는
rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files프로시저를 호출합니다.SQL> SELECT * FROM TABLE(rdsadmin.rdsadmin_transport_util.list_xtts_orphan_files); FILENAME FILESIZE -------------- --------- datafile_7.dbf 104865792 datafile_8.dbf 104865792 -
rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import프로시저를 실행하여 분리된 파일을 삭제합니다.BEGIN rdsadmin.rdsadmin_transport_util.cleanup_incomplete_xtts_import('DATA_PUMP_DIR'); END; /정리 작업을 수행하면
BDUMP디렉터리에rds-xtts-delete_xtts_orphaned_files-이름 형식을 사용하는 로그 파일이 생성됩니다.YYYY-MM-DD.HH24-MI-SS.FF.log -
이전 단계에서 생성된 로그 파일을 읽습니다. 다음 예에서는
rds-xtts-delete_xtts_orphaned_files-로그를 읽습니다.2023-06-01.09-33-11.868894000.logSELECT * FROM TABLE(rdsadmin.rds_file_util.read_text_file( p_directory => 'BDUMP', p_filename => 'rds-xtts-delete_xtts_orphaned_files-2023-06-01.09-33-11.868894000.log')); TEXT -------------------------------------------------------------------------------- orphan transported datafile datafile_7.dbf deleted. orphan transported datafile datafile_8.dbf deleted.
-
-
테이블스페이스를 가져오고 테이블스페이스에 대한 메타데이터도 가져왔지만 호환성 오류나 기타 Oracle Data Pump 문제가 발생한 경우 부분적으로 전송된 데이터 파일을 다음과 같이 정리하세요.
-
DBA_TABLESPACES를 쿼리하여 부분적으로 전송된 데이터 파일이 포함된 테이블스페이스를 나열합니다.SQL> SELECT TABLESPACE_NAME FROM DBA_TABLESPACES WHERE PLUGGED_IN='YES'; TABLESPACE_NAME -------------------------------------------------------------------------------- TBS_3 -
테이블스페이스와 부분적으로 전송된 데이터 파일을 삭제합니다.
DROP TABLESPACETBS_3INCLUDING CONTENTS AND DATAFILES;
-
