기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
에서 다중 서버 평가 보고서 생성 AWS Schema Conversion Tool
전체 환경에 가장 적합한 대상 방향을 결정하려면 다중 서버 평가 보고서를 생성합니다.
다중 서버 평가 보고서는 평가하려는 각 스키마 정의에 대해 제공된 입력 내용을 기반으로 여러 서버를 평가합니다. 스키마 정의에는 데이터베이스 서버 연결 파라미터와 각 스키마의 전체 이름이 포함됩니다. 각 스키마를 평가한 후는 여러 서버에서 데이터베이스 마이그레이션을 위한 집계된 요약 평가 보고서를 AWS SCT 생성합니다. 이 보고서는 가능한 각 마이그레이션 대상의 예상 복잡성을 보여줍니다.
AWS SCT 를 사용하여 다음 소스 및 대상 데이터베이스에 대한 다중 서버 평가 보고서를 생성할 수 있습니다.
| 원본 데이터베이스 | 대상 데이터베이스 |
|---|---|
|
Amazon Redshift |
Amazon Redshift |
|
Azure SQL Database |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
Azure Synapse Analytics |
Amazon Redshift |
|
BigQuery |
Amazon Redshift |
|
Greenplum |
Amazon Redshift |
|
IBM Db2 for z/OS |
Amazon Aurora MySQL-Compatible Edition(Aurora MySQL), Amazon Aurora PostgreSQL-Compatible Edition(Aurora PostgreSQL), MySQL, PostgreSQL |
|
IBM DB2 LUW |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Microsoft SQL Server |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, Babelfish for Aurora PostgreSQL, MariaDB, Microsoft SQL Server, MySQL, PostgreSQL |
|
MySQL |
Aurora PostgreSQL, MySQL, PostgreSQL |
|
Netezza |
Amazon Redshift |
|
Oracle |
Aurora MySQL, Aurora PostgreSQL, Amazon Redshift, MariaDB, MySQL, Oracle, PostgreSQL |
|
PostgreSQL |
Aurora MySQL, Aurora PostgreSQL, MySQL, PostgreSQL |
|
SAP ASE |
Aurora MySQL, Aurora PostgreSQL, MariaDB, MySQL, PostgreSQL |
|
Snowflake |
Amazon Redshift |
|
Teradata |
Amazon Redshift |
|
Vertica |
Amazon Redshift |
다중 서버 평가 수행
다음 절차에 따라를 사용하여 다중 서버 평가를 수행합니다 AWS SCT. 다중 서버 평가를 수행하기 AWS SCT 위해에서 새 프로젝트를 생성할 필요가 없습니다. 시작하기 전에 데이터베이스 연결 파라미터가 포함된 쉼표로 구분된 값(CSV) 파일이 준비되었는지 확인합니다. 또한 필요한 데이터베이스 드라이버를 모두 설치하고 AWS SCT 설정에서 드라이버 위치를 설정했는지 확인합니다. 자세한 내용은 용 JDBC 드라이버 설치 AWS Schema Conversion Tool 단원을 참조하십시오.
다중 서버 평가를 수행하고 집계된 요약 보고서를 생성하려면
-
에서 파일 AWS SCT, 새 다중 서버 평가를 선택합니다. New multiserver assessment 대화 상자가 열립니다.
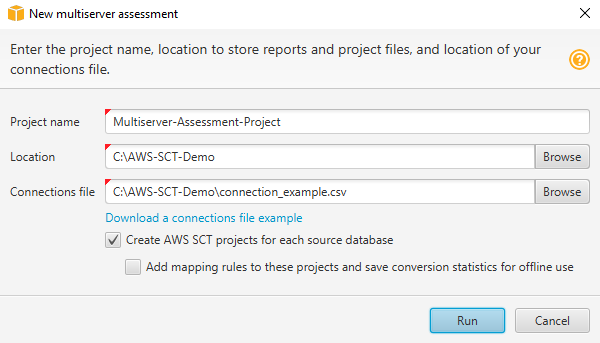
-
Download a connections file example을 선택하여 데이터베이스 연결 파라미터가 포함된 CSV 파일의 빈 템플릿을 다운로드합니다.
-
프로젝트 이름, 위치(보고서 저장용), Connections file(CSV 파일)의 값을 입력합니다.
-
평가 보고서를 생성한 후 마이그레이션 AWS SCT 프로젝트를 자동으로 생성하려면 각 소스 데이터베이스에 대한 프로젝트 생성을 선택합니다.
-
각 소스 데이터베이스에 대한 AWS SCT 프로젝트 생성을 켠 상태에서 이러한 프로젝트에 매핑 규칙 추가를 선택하고 오프라인 사용을 위해 변환 통계를 저장할 수 있습니다. 이 경우 AWS SCT 는 각 프로젝트에 매핑 규칙을 추가하고 소스 데이터베이스 메타데이터를 프로젝트에 저장합니다. 자세한 내용은 에서 오프라인 모드 사용 AWS Schema Conversion Tool 단원을 참조하십시오.
-
실행을 선택합니다.
데이터베이스 평가 속도를 나타내는 진행률 표시줄이 나타납니다. 대상 엔진 수는 평가 런타임에 영향을 미칠 수 있습니다.
-
다음 메시지가 표시되면 예를 선택합니다. Full analysis of all Database servers may take some time. Do you want to proceed?
다중 서버 평가 보고서가 생성되면 완료되었음을 나타내는 화면이 표시됩니다.
-
집계된 요약 평가 보고서를 보려면 Open Report를 선택합니다.
기본적으로는 모든 소스 데이터베이스에 대한 집계 보고서와 소스 데이터베이스의 각 스키마 이름에 대한 세부 평가 보고서를 AWS SCT 생성합니다. 자세한 내용은 보고서 찾기 및 보기 단원을 참조하십시오.
각 소스 데이터베이스의 AWS SCT 프로젝트 생성 옵션이 켜진 상태에서는 각 소스 데이터베이스의 빈 프로젝트를 AWS SCT 생성합니다. AWS SCT 또한는 앞서 설명한 대로 평가 보고서를 생성합니다. 이러한 평가 보고서를 분석하고 각 소스 데이터베이스의 마이그레이션 대상을 선택한 후 이러한 빈 프로젝트에 대상 데이터베이스를 추가합니다.
이러한 프로젝트에 매핑 규칙 추가 및 오프라인 사용에 대한 변환 통계 저장 옵션이 켜져 있으면가 각 소스 데이터베이스에 대한 프로젝트를 AWS SCT 생성합니다. 이러한 프로젝트에는 다음 정보가 포함됩니다.
소스 데이터베이스 및 가상 대상 데이터베이스 플랫폼. 자세한 내용은 AWS Schema Conversion Tool에서 가상 대상에 매핑 단원을 참조하십시오.
이 소스–대상 쌍에 대한 매핑 규칙. 자세한 내용은 데이터 유형 매핑 단원을 참조하십시오.
이 소스-대상 쌍에 대한 데이터베이스 마이그레이션 평가 보고서
소스 스키마 메타데이터 - 오프라인 모드에서이 AWS SCT 프로젝트를 사용할 수 있습니다. 자세한 내용은 에서 오프라인 모드 사용 AWS Schema Conversion Tool 단원을 참조하십시오.
입력 CSV 파일 준비
연결 파라미터를 다중 서버 평가 보고서의 입력으로 제공하려면 다음 예제와 같이 CSV 파일을 사용합니다.
Name,Description,Secret Manager Key,Server IP,Port,Service Name,Database name,BigQuery path,Source Engine,Schema Names,Use Windows Authentication,Login,Password,Use SSL,Trust store,Key store,SSL authentication,Target Engines Sales,,,192.0.2.0,1521,pdb,,,ORACLE,Q4_2021;FY_2021,,user,password,,,,,POSTGRESQL;AURORA_POSTGRESQL Marketing,,,ec2-a-b-c-d.eu-west-1.compute.amazonaws.com,1433,,target_audience,,MSSQL,customers.dbo,,user,password,,,,,AURORA_MYSQL HR,,,192.0.2.0,1433,,employees,,MSSQL,employees.%,true,,,,,,,AURORA_POSTGRESQL Customers,,secret-name,,,,,,MYSQL,customers,,,,,,,,AURORA_POSTGRESQL Analytics,,,198.51.100.0,8195,,STATISTICS,,DB2LUW,BI_REPORTS,,user,password,,,,,POSTGRESQL Products,,,203.0.113.0,8194,,,,TERADATA,new_products,,user,password,,,,,REDSHIFT
위의 예에서는 세미콜론을 사용하여 Sales 데이터베이스의 두 스키마 이름을 구분합니다. 또한 세미콜론을 사용하여 Sales 데이터베이스의 두 대상 데이터베이스 마이그레이션 플랫폼을 구분합니다.
또한 이전 예제에서는 AWS Secrets Manager 를 사용하여 Customers 데이터베이스에 연결하고 Windows 인증을 사용하여 HR 데이터베이스에 연결합니다.
새 CSV 파일을 만들거나 AWS SCT 에서 CSV 파일용 템플릿을 다운로드하여 필요한 정보를 입력할 수 있습니다. CSV 파일의 첫 번째 행에 위의 예에 나온 것과 같은 열 이름이 포함되어 있는지 확인합니다.
입력 CSV 파일의 템플릿을 다운로드하려면
시작 AWS SCT.
파일을 선택한 다음, New multiserver assessment를 선택합니다.
Download a connections file example을 선택합니다.
템플릿에서 제공하는 다음과 같은 값이 CSV 파일에 포함되어 있는지 확인합니다.
-
이름 - 데이터베이스를 식별하는 데 도움이 되는 텍스트 레이블입니다. AWS SCT 는 평가 보고서에 이 텍스트 레이블을 표시합니다.
-
설명 - 데이터베이스에 대한 추가 정보를 제공할 수 있는 선택적 값입니다.
-
Secret Manager Key - AWS Secrets Manager에 데이터베이스 보안 인증 정보를 저장하는 보안 암호의 이름입니다. Secrets Manager를 사용하려면 AWS 프로필을에 저장해야 합니다 AWS SCT. 자세한 내용은 AWS Secrets Manager 에서 구성 AWS Schema Conversion Tool 단원을 참조하십시오.
중요
AWS SCT 는 입력 파일에 서버 IP, 포트, 로그인 및 암호 파라미터를 포함하는 경우 Secret Manager 키 파라미터를 무시합니다.
-
서버 IP – 소스 데이터베이스 서버의 DNS(Domain Name Service) 이름 또는 IP 주소입니다.
-
포트 - 소스 데이터베이스 서버에 연결하는 데 사용되는 포트입니다.
-
서비스 이름 - 서비스 이름을 사용하여 Oracle 데이터베이스에 연결하는 경우 연결할 Oracle 서비스의 이름입니다.
-
데이터베이스 이름 - 데이터베이스 이름입니다. Oracle 데이터베이스의 경우 Oracle System ID(SID)를 사용합니다.
-
BigQuery path - 소스 BigQuery 데이터베이스의 서비스 계정 키 파일 경로입니다. 이 파일 생성에 대한 자세한 내용은 BigQuery를 소스로 사용하기 위한 권한 섹션을 참조하세요.
-
소스 엔진 - 소스 데이터베이스의 유형입니다. 다음 값 중 하나를 사용합니다.
AZURE_MSSQL - Azure SQL Database
AZURE_SYNAPSE - Azure Synapse Analytics 데이터베이스
GOOGLE_BIGQUERY - BigQuery 데이터베이스
DB2ZOS - IBM Db2 for z/OS 데이터베이스
DB2LUW - IBM Db2 LUW 데이터베이스
GREENPLUM - Greenplum 데이터베이스
MSSQL - Microsoft SQL Server 데이터베이스
MYSQL - MySQL 데이터베이스
NETEZZA - Netezza 데이터베이스
ORACLE - Oracle 데이터베이스
POSTGRESQL - PostgreSQL 데이터베이스
REDSHIFT - Amazon Redshift 데이터베이스
SNOWFLAKE - Snowflake 데이터베이스
SYBASE_ASE - SAP ASE 데이터베이스
TERADATA - Teradata 데이터베이스
VERTICA - Vertica 데이터베이스
-
스키마 이름 - 평가 보고서에 포함할 데이터베이스 스키마의 이름입니다.
Azure SQL Database, Azure Synapse Analytics, BigQuery, Netezza, SAP ASE, Snowflake 및 SQL Server의 경우 다음 형식의 스키마 이름을 사용합니다.
db_name.schema_namedb_nameschema_name"database.name"."schema.name"과 같이 점이 포함된 데이터베이스 또는 스키마 이름은 큰따옴표로 묶습니다.Schema1;Schema2와 같이 세미콜론을 사용하여 여러 스키마 이름을 구분합니다.데이터베이스 및 스키마 이름은 대/소문자를 구분합니다.
데이터베이스 또는 스키마 이름에 있는 여러 기호를 바꾸려면 퍼센트(
%)를 와일드카드로 사용합니다. 위 예제에서는 퍼센트(%)를 와일드카드로 사용하여employees데이터베이스의 모든 스키마를 평가 보고서에 포함시킵니다. -
Use Windows Authentication - Windows 인증을 사용하여 Microsoft SQL Server 데이터베이스에 연결하는 경우 true를 입력합니다. 자세한 내용은 Microsoft SQL Server를 소스로 사용할 때 Windows 인증 사용 단원을 참조하십시오.
-
로그인 – 소스 데이터베이스 서버에 연결하는 사용자 이름입니다.
-
암호 - 소스 데이터베이스 서버에 연결하는 데 필요한 암호입니다.
-
Use SSL - SSL(Secure Sockets Layer)을 사용하여 소스 데이터베이스에 연결하는 경우 true를 입력합니다.
-
트러스트 스토어 - SSL 연결에 사용할 트러스트 스토어입니다.
-
키 스토어 - SSL 연결에 사용할 키 스토어입니다.
-
SSL 인증 - 인증서를 통해 SSL 인증을 사용하는 경우 true를 입력합니다.
-
Target Engines - 대상 데이터베이스 플랫폼입니다. 평가 보고서에서 하나 이상의 대상을 지정하려면 다음 값을 사용합니다.
AURORA_MYSQL - Aurora MySQL-Compatible 데이터베이스
AURORA_POSTGRESQL - Aurora PostgreSQL-Compatible 데이터베이스
BABELFISH - Babelfish for Aurora PostgreSQL 데이터베이스
MARIA_DB - MariaDB 데이터베이스
MSSQL - Microsoft SQL Server 데이터베이스
MYSQL - MySQL 데이터베이스
ORACLE - Oracle 데이터베이스
POSTGRESQL - PostgreSQL 데이터베이스
REDSHIFT - Amazon Redshift 데이터베이스
MYSQL;MARIA_DB와 같이 세미콜론을 사용하여 여러 대상을 구분합니다. 대상 수는 평가를 실행하는 데 걸리는 시간에 영향을 줍니다.
보고서 찾기 및 보기
다중 서버 평가에서는 두 가지 유형의 보고서가 생성됩니다.
-
모든 소스 데이터베이스의 집계 보고서
-
소스 데이터베이스의 각 스키마 이름에 대한 대상 데이터베이스의 세부 평가 보고서
보고서는 New multiserver assessment 대화 상자의 위치에서 선택한 디렉터리에 저장됩니다.
세부 보고서에 액세스하려면 소스 데이터베이스, 스키마 이름 및 대상 데이터베이스 엔진별로 구성된 하위 디렉터리를 탐색할 수 있습니다.
집계 보고서에는 대상 데이터베이스의 변환 복잡도에 대한 정보가 네 개의 열로 표시됩니다. 해당 열에는 코드 객체, 스토리지 객체, 구문 요소의 변환 및 변환 복잡도에 대한 정보가 포함됩니다.
다음 예제에서는 두 Oracle 데이터베이스 스키마를 Amazon RDS for PostgreSQL로 변환하는 방법에 대한 정보를 보여줍니다.

지정된 각각의 추가 대상 데이터베이스 엔진에 대해 동일한 네 개의 열이 보고서에 추가됩니다.
이 정보를 읽는 방법에 대한 자세한 내용은 다음을 참조하세요.
집계된 평가 보고서의 출력
의 집계된 다중 서버 데이터베이스 마이그레이션 평가 보고서는 다음 열이 있는 CSV 파일 AWS Schema Conversion Tool 입니다.
-
Server IP address and port -
Secret Manager key -
Name -
Description -
Database name -
Schema name -
Code object conversion % fortarget_database -
Storage object conversion % fortarget_database -
Syntax elements conversion % fortarget_database -
Conversion complexity fortarget_database
정보를 수집하기 위해는 전체 평가 보고서를 AWS SCT 실행한 다음 스키마별로 보고서를 집계합니다.
보고서에서 다음 세 필드는 평가를 기반으로 가능한 자동 변환 비율을 나타냅니다.
- Code object conversion %
-
스키마에서 자동 또는 최소한의 변경으로 변환 AWS SCT 할 수 있는 코드 객체의 백분율입니다. 코드 객체에는 프로시저, 함수, 보기 등이 포함됩니다.
- Storage object conversion %
-
SCT가 자동으로 변환하거나 최소한의 변경으로 변환할 수 있는 스토리지 객체의 비율입니다. 스토리지 객체에는 테이블, 인덱스, 제약 조건 등이 포함됩니다.
- Syntax elements conversion %
-
SCT가 자동으로 변환할 수 있는 구문 요소의 비율입니다. 구문 요소에는
SELECT,FROM,DELETE및JOIN절 등이 포함됩니다.
변환 복잡도 계산은 작업 항목의 개념을 기반으로 합니다. 작업 항목은 특정 대상으로 마이그레이션하는 동안 수동으로 수정해야 하는 소스 코드의 문제 유형을 나타냅니다. 작업 항목은 여러 번 발생할 수 있습니다.
가중치 척도는 마이그레이션 수행의 복잡도를 나타냅니다. 숫자 1은 가장 낮은 복잡도를 나타내고 숫자 10은 가장 높은 복잡도를 나타냅니다.
