기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
를 사용하여 하둡 워크로드를 Amazon EMR로 마이그레이션 AWS Schema Conversion Tool
Apache Hadoop 클러스터를 마이그레이션하려면 AWS SCT 버전 1.0.670 이상을 사용해야 합니다. 또한 AWS SCT의 명령줄 인터페이스(CLI)를 숙지해야 합니다. 자세한 내용은 에 대한 CLI 참조 AWS Schema Conversion Tool 단원을 참조하십시오.
주제
마이그레이션 개요
다음 이미지는 Apache Hadoop에서 Amazon EMR로의 마이그레이션에 대한 아키텍처 다이어그램을 보여줍니다.
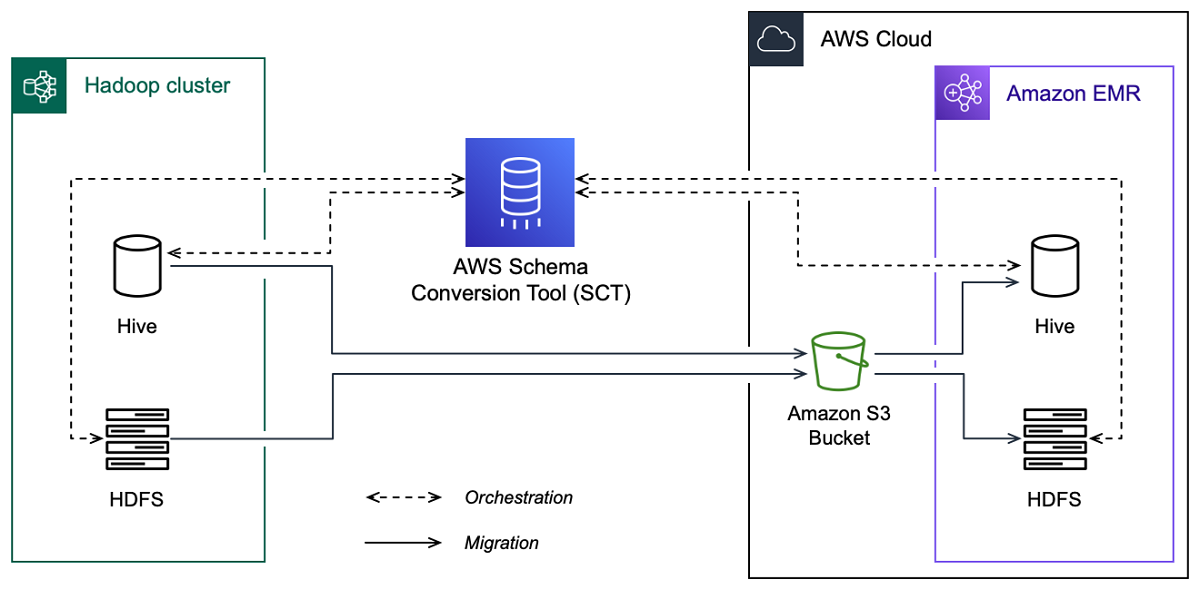
AWS SCT 는 소스 Hadoop 클러스터에서 Amazon S3 버킷으로 데이터 및 메타데이터를 마이그레이션합니다. 다음으로, AWS SCT 는 소스 Hive 메타데이터를 사용하여 대상 Amazon EMR Hive 서비스에서 데이터베이스 객체를 생성합니다. 선택적으로를 메타스토어 AWS Glue Data Catalog 로 사용하도록 Hive를 구성할 수 있습니다. 이 경우는 소스 Hive 메타데이터를 로 AWS SCT 마이그레이션합니다 AWS Glue Data Catalog.
그런 다음 AWS SCT 를 사용하여 Amazon S3 버킷에서 대상 Amazon EMR HDFS 서비스로 데이터를 마이그레이션할 수 있습니다. 또는 Amazon S3 버킷에 데이터를 그대로 두고 Hadoop 워크로드를 위한 데이터 리포지토리로 사용할 수도 있습니다.
Hapood 마이그레이션을 시작하려면 AWS SCT CLI 스크립트를 생성하고 실행합니다. 이 스크립트에는 마이그레이션을 실행하기 위한 전체 명령 세트가 포함되어 있습니다. Hadoop 마이그레이션 스크립트의 템플릿을 다운로드하여 편집할 수 있습니다. 자세한 내용은 CLI 시나리오 가져오기 단원을 참조하십시오.
Apache Hadoop에서 Amazon S3 및 Amazon EMR로 마이그레이션을 실행할 수 있도록 스크립트에는 다음 단계가 포함되어 있어야 합니다.
1단계: Hadoop 클러스터에 연결
Apache Hadoop 클러스터의 마이그레이션을 시작하려면 새 AWS SCT 프로젝트를 생성합니다. 그 다음, 소스 및 대상 클러스터에 연결합니다. 마이그레이션을 시작하기 전에 대상 AWS 리소스를 생성하고 프로비저닝해야 합니다.
이 단계에서는 다음 AWS SCT CLI 명령을 사용합니다.
CreateProject- 새 AWS SCT 프로젝트를 생성합니다.AddSourceCluster- AWS SCT 프로젝트의 소스 Hadoop 클러스터에 연결합니다.AddSourceClusterHive- 프로젝트의 소스 Hive 서비스에 연결합니다.AddSourceClusterHDFS- 프로젝트의 소스 HDFS 서비스에 연결합니다.AddTargetCluster- 프로젝트의 대상 Amazon EMR 클러스터에 연결합니다.AddTargetClusterS3- Amazon S3 버킷을 프로젝트에 추가합니다.AddTargetClusterHive- 프로젝트의 대상 Hive 서비스에 연결합니다.AddTargetClusterHDFS- 프로젝트의 대상 HDFS 서비스에 연결합니다.
이러한 AWS SCT CLI 명령 사용 예제는 섹션을 참조하세요Apache Hadoop에 연결.
소스 또는 대상 클러스터에 연결하는 명령을 실행하면가이 클러스터에 대한 연결을 설정하려고 AWS SCT 시도합니다. 연결 시도가 실패하면는 CLI 스크립트에서 명령 실행을 AWS SCT 중지하고 오류 메시지를 표시합니다.
2단계: 매핑 규칙 설정
소스 및 대상 클러스터에 연결한 후 매핑 규칙을 설정합니다. 매핑 규칙은 소스 클러스터의 마이그레이션 대상을 정의합니다. AWS SCT 프로젝트에 추가한 모든 소스 클러스터에 대한 매핑 규칙을 설정해야 합니다. 매핑 규칙에 대한 자세한 내용은 AWS Schema Conversion Tool에서 데이터 유형 매핑 섹션을 참조하세요.
이 단계에서는 AddServerMapping 명령을 사용합니다. 이 명령은 소스 및 대상 클러스터를 정의하는 두 개의 파라미터를 사용합니다. 데이터베이스 객체의 명시적 경로 또는 객체 이름과 함께 AddServerMapping 명령을 사용할 수 있습니다. 첫 번째 옵션에는 객체의 유형과 이름을 포함합니다. 두 번째 옵션에는 객체 이름만 포함합니다.
-
sourceTreePath- 소스 데이터베이스 객체의 명시적 경로입니다.targetTreePath- 대상 데이터베이스 객체의 명시적 경로입니다. -
sourceNamePath- 소스 객체의 이름만 포함하는 경로입니다.targetNamePath- 대상 객체의 이름만 포함하는 경로입니다.
다음 코드 예제는 소스 testdb Hive 데이터베이스 및 대상 EMR 클러스터의 명시적 경로를 사용하여 매핑 규칙을 생성합니다.
AddServerMapping -sourceTreePath: 'Clusters.HADOOP_SOURCE.HIVE_SOURCE.Databases.testdb' -targetTreePath: 'Clusters.HADOOP_TARGET.HIVE_TARGET' /
Windows에서 이 예제와 다음 예제를 사용할 수 있습니다. Linux에서 CLI 명령을 실행하려면 운영 체제에 맞게 파일 경로를 업데이트해야 합니다.
다음 코드 예제는 객체 이름만 포함된 경로를 사용하여 매핑 규칙을 생성합니다.
AddServerMapping -sourceNamePath: 'HADOOP_SOURCE.HIVE_SOURCE.testdb' -targetNamePath: 'HADOOP_TARGET.HIVE_TARGET' /
Amazon EMR 또는 Amazon S3을 소스 객체의 대상으로 선택할 수 있습니다. 각 소스 객체에 대해 단일 AWS SCT 프로젝트에서 대상을 하나만 선택할 수 있습니다. 소스 객체의 마이그레이션 대상을 변경하려면 기존 매핑 규칙을 삭제한 다음 새 매핑 규칙을 생성합니다. 매핑 규칙을 삭제하려면 DeleteServerMapping 명령을 사용합니다. 이 명령은 다음 두 파라미터 중 하나를 사용합니다.
sourceTreePath- 소스 데이터베이스 객체의 명시적 경로입니다.sourceNamePath- 소스 객체의 이름만 포함하는 경로입니다.
AddServerMapping 및 DeleteServerMapping 명령에 대한 자세한 내용은 AWS Schema Conversion Tool CLI 참조
3단계: 평가 보고서 생성
마이그레이션을 시작하기 전에 평가 보고서를 생성하는 것이 좋습니다. 이 보고서에는 모든 마이그레이션 작업이 요약되어 있으며 마이그레이션 중에 나타날 작업 항목에 대해 자세히 설명합니다. 마이그레이션이 실패하지 않도록 하려면 마이그레이션 전에 이 보고서를 검토하여 작업 항목을 해결합니다. 자세한 내용은 평가 보고서 단원을 참조하십시오.
이 단계에서는 CreateMigrationReport 명령을 사용합니다. 이 명령에서는 2개의 파라미터를 사용합니다. treePath 파라미터는 필수이고 forceMigrate 파라미터는 선택 사항입니다.
treePath- 평가 보고서 사본을 저장할 소스 데이터베이스 객체의 명시적 경로입니다.forceMigrate- 로 설정하면 프로젝트에 동일한 객체를 참조하는 HDFS 폴더와 Hive 테이블이 포함되어 있더라도 마이그레이션을trueAWS SCT 계속합니다. 기본값은false입니다.
그런 다음 평가 보고서 사본을 PDF 또는 쉼표로 구분된 값(CSV) 파일로 저장할 수 있습니다. 이렇게 하려면 SaveReportPDF 또는 SaveReportCSV 명령을 사용합니다.
SaveReportPDF 명령은 평가 보고서 사본을 PDF 파일로 저장합니다. 이 명령에서는 4개의 파라미터를 사용합니다. file 파라미터는 필수이고 다른 파라미터는 선택 사항입니다.
file- PDF 파일의 경로와 이름입니다.filter- 마이그레이션할 소스 객체의 범위를 정의하기 위해 이전에 만든 필터의 이름입니다.treePath- 평가 보고서 사본을 저장할 소스 데이터베이스 객체의 명시적 경로입니다.namePath- 평가 보고서 사본을 저장할 대상 객체의 이름만 포함된 경로입니다.
SaveReportCSV 명령은 평가 보고서를 3개의 CSV 파일로 저장합니다. 이 명령에서는 4개의 파라미터를 사용합니다. directory 파라미터는 필수이고 다른 파라미터는 선택 사항입니다.
directory-가 CSV 파일을 AWS SCT 저장하는 폴더의 경로입니다.filter- 마이그레이션할 소스 객체의 범위를 정의하기 위해 이전에 만든 필터의 이름입니다.treePath- 평가 보고서 사본을 저장할 소스 데이터베이스 객체의 명시적 경로입니다.namePath- 평가 보고서 사본을 저장할 대상 객체의 이름만 포함된 경로입니다.
다음 코드 예제는 평가 보고서 사본을 c:\sct\ar.pdf 파일에 저장합니다.
SaveReportPDF -file:'c:\sct\ar.pdf' /
다음 코드 예제는 평가 보고서 사본을 c:\sct 폴더에 CSV 파일로 저장합니다.
SaveReportCSV -file:'c:\sct' /
SaveReportPDF 및 SaveReportCSV 명령에 대한 자세한 내용은 AWS Schema Conversion Tool CLI 참조
4단계:를 사용하여 Apache Hadoop 클러스터를 Amazon EMR로 마이그레이션 AWS SCT
AWS SCT 프로젝트를 구성한 후 온프레미스 Apache Hadoop 클러스터를 로 마이그레이션합니다 AWS 클라우드.
이 단계에서는 Migrate, MigrationStatus 및 ResumeMigration 명령을 사용합니다.
Migrate 명령은 소스 객체를 대상 클러스터로 마이그레이션합니다. 이 명령에서는 4개의 파라미터를 사용합니다. filter 또는 treePath 파라미터를 지정했는지 확인합니다. 다른 파라미터는 선택 사항입니다.
filter- 마이그레이션할 소스 객체의 범위를 정의하기 위해 이전에 만든 필터의 이름입니다.treePath- 평가 보고서 사본을 저장할 소스 데이터베이스 객체의 명시적 경로입니다.forceLoad- 로 설정하면가 마이그레이션 중에 데이터베이스 메타데이터 트리를trueAWS SCT 자동으로 로드합니다. 기본값은false입니다.forceMigrate- 로 설정하면 프로젝트에 동일한 객체를 참조하는 HDFS 폴더와 Hive 테이블이 포함되어 있더라도 마이그레이션을trueAWS SCT 계속합니다. 기본값은false입니다.
MigrationStatus 명령은 마이그레이션 진행 상황에 대한 정보를 반환합니다. 이 명령을 실행하려면 name 파라미터에 마이그레이션 프로젝트의 이름을 입력합니다. CreateProject 명령에서 이 이름을 지정했습니다.
이 ResumeMigration 명령은 Migrate 명령을 사용하여 시작한 후 중단된 마이그레이션을 재개합니다. ResumeMigration 명령은 파라미터를 사용하지 않습니다. 마이그레이션을 재개하려면 소스 및 대상 클러스터에 연결해야 합니다. 자세한 내용은 마이그레이션 프로젝트 관리 단원을 참조하십시오.
다음 코드 예제는 소스 HDFS 서비스에서 Amazon EMR로 데이터를 마이그레이션합니다.
Migrate -treePath: 'Clusters.HADOOP_SOURCE.HDFS_SOURCE' -forceMigrate: 'true' /
CLI 스크립트 실행
AWS SCT CLI 스크립트 편집을 완료한 후 .scts 확장명이 있는 파일로 저장합니다. 이제 AWS SCT 설치 경로의 app 폴더에서 스크립트를 실행할 수 있습니다. 이렇게 하려면 다음 명령을 사용합니다.
RunSCTBatch.cmd --pathtoscts "C:\script_path\hadoop.scts"
위 예제에서 script_path를 CLI 스크립트가 있는 파일의 경로로 바꿉니다. 에서 CLI 스크립트를 실행하는 방법에 대한 자세한 내용은 섹션을 AWS SCT참조하세요스크립트 모드.
빅 데이터 마이그레이션 프로젝트 관리
마이그레이션을 완료한 후 나중에 사용할 수 있도록 AWS SCT 프로젝트를 저장하고 편집할 수 있습니다.
AWS SCT 프로젝트를 저장하려면 SaveProject 명령을 사용합니다. 이 명령은 파라미터를 사용하지 않습니다.
다음 코드 예제에서는 AWS SCT 프로젝트를 저장합니다.
SaveProject /
AWS SCT 프로젝트를 열려면 OpenProject 명령을 사용합니다. 이 명령은 1개의 필수 파라미터를 사용합니다. file 파라미터에 AWS SCT 프로젝트 파일의 경로와 이름을 입력합니다. CreateProject 명령에서 프로젝트 이름을 지정했습니다. OpenProject 명령을 실행하려면 프로젝트 파일 이름에 .scts 확장자를 추가해야 합니다.
다음 코드 예제는 c:\sct 폴더에서 hadoop_emr 프로젝트를 엽니다.
OpenProject -file: 'c:\sct\hadoop_emr.scts' /
AWS SCT 프로젝트를 연 후에는 소스 및 대상 클러스터를 프로젝트에 이미 추가했으므로 추가할 필요가 없습니다. 소스 및 대상 클러스터로 작업을 시작하려면 소스 및 대상 클러스터에 연결해야 합니다. 이렇게 하려면 ConnectSourceCluster 및 ConnectTargetCluster 명령을 사용합니다. 이들 명령은 AddSourceCluster 및 AddTargetCluster 명령과 동일한 파라미터를 사용합니다. 이러한 파라미터 목록은 변경하지 않은 상태로 CLI 스크립트를 편집하고 이러한 명령의 이름을 바꿀 수 있습니다.
다음 코드 예제는 소스 Hadoop 클러스터에 연결합니다.
ConnectSourceCluster -name: 'HADOOP_SOURCE' -vendor: 'HADOOP' -host: 'hadoop_address' -port: '22' -user: 'hadoop_user' -password: 'hadoop_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: 'hadoop_passphrase' /
다음 코드 예제는 대상 Amazon EMR 클러스터에 연결합니다.
ConnectTargetCluster -name: 'HADOOP_TARGET' -vendor: 'AMAZON_EMR' -host: 'ec2-44-44-55-66.eu-west-1.EXAMPLE.amazonaws.com' -port: '22' -user: 'emr_user' -password: 'emr_password' -useSSL: 'true' -privateKeyPath: 'c:\path\name.pem' -passPhrase: '1234567890abcdef0!' -s3Name: 'S3_TARGET' -accessKey: 'AKIAIOSFODNN7EXAMPLE' -secretKey: 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY' -region: 'eu-west-1' -s3Path: 'doc-example-bucket/example-folder' /
위 예제에서 hadoop_address를 Hadoop 클러스터의 IP 주소로 바꿉니다. 필요한 경우 port 변수 값을 구성합니다. 그런 다음 hadoop_user 및 hadoop_password를 Hadoop 사용자의 이름 및 이 사용자의 암호로 바꿉니다. path\name에는 소스 Hadoop 클러스터의 PEM 파일 이름과 경로를 입력합니다. 소스 및 대상 클러스터 추가에 대한 자세한 내용은 를 사용하여 Apache Hadoop 데이터베이스에 연결 AWS Schema Conversion Tool 항목을 참조하세요.
소스 및 대상 Hadoop 클러스터에 연결한 후에는 Hive 및 HDFS 서비스와 Amazon S3 버킷에 연결해야 합니다. 이렇게 하려면 ConnectSourceClusterHive, ConnectSourceClusterHdfs, ConnectTargetClusterHive, ConnectTargetClusterHdfs 및 ConnectTargetClusterS3 명령을 사용합니다. 이들 명령은 Hive 및 HDFS 서비스와 Amazon S3 버킷을 프로젝트에 추가하는 데 사용한 명령과 동일한 파라미터를 사용합니다. CLI 스크립트를 편집하여 명령 이름에서 Add 접두사를 Connect로 바꿉니다.
