DynamoDB 테이블에서 적절한 규모의 프로비저닝을 위해 프로비저닝된 용량 평가
이 섹션에서는 DynamoDB 테이블에 적절한 규모의 프로비저닝이 있는지 평가하는 방법을 간략히 살펴봅니다. 워크로드가 발전함에 따라 운영 절차를 적절하게 수정해야 합니다. 특히 DynamoDB 테이블이 프로비저닝 모드로 구성되어 있고 테이블을 과다 프로비저닝하거나 과소 프로비저닝할 위험이 있는 경우에는 더욱 그렇습니다.
아래에 설명된 절차에는 프로덕션 애플리케이션을 지원하는 DynamoDB 테이블에서 캡처해야 하는 통계 정보가 필요합니다. 애플리케이션 동작을 이해하려면 애플리케이션의 데이터 계절성을 포착할 수 있을 만큼 충분히 중요한 기간을 정의해야 합니다. 예를 들어 애플리케이션이 주간 패턴을 보이는 경우 3주 기간을 사용하면 애플리케이션 처리량 요구 사항을 분석할 시간을 충분히 확보할 수 있습니다.
어디서부터 시작해야 할지 모르겠다면 아래 계산에 최소 한 달 분량의 데이터 사용량을 사용해 보세요.
DynamoDB 테이블은 용량을 평가하는 동안 읽기 용량 단위(RCU)와 쓰기 용량 단위(WCU)를 별개로 구성할 수 있습니다. 테이블에 글로벌 보조 인덱스(GSI)가 구성된 경우 소비할 처리량을 지정해야 합니다. 이 처리량은 기본 테이블의 RCU 및 WCU와도 별개입니다.
참고
로컬 보조 인덱스(LSI)는 기본 테이블의 용량을 소비합니다.
DynamoDB 테이블에서 소비 지표를 검색하는 방법
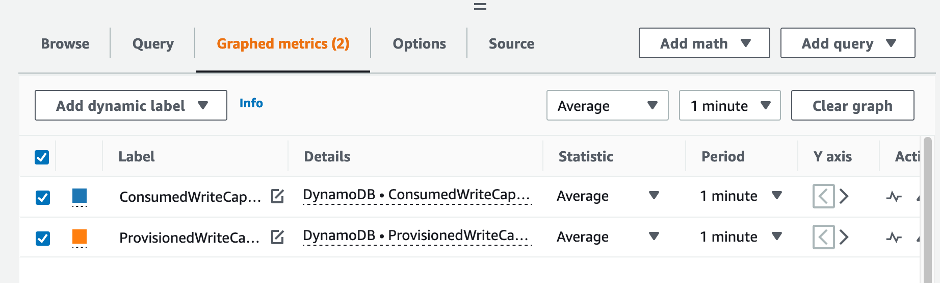
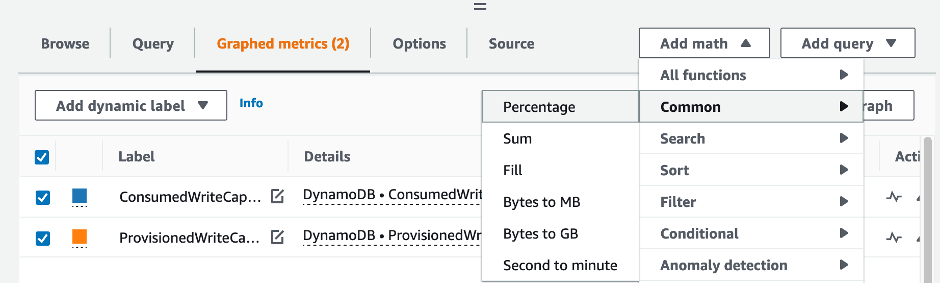
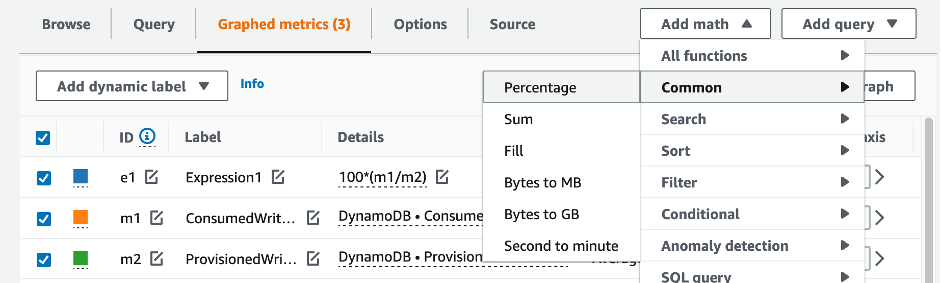
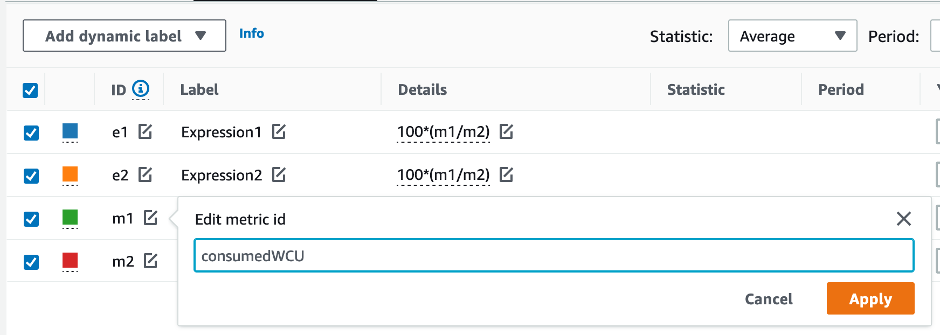
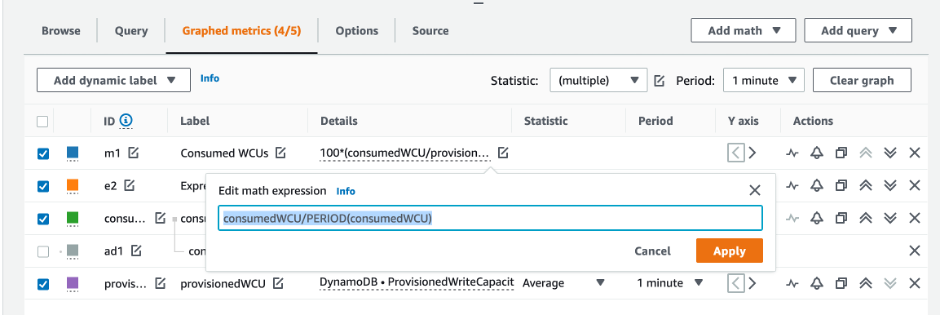
테이블 및 GSI 용량을 평가하려면 다음 CloudWatch 지표를 모니터링하고 적절한 차원을 선택하여 테이블 또는 GSI 정보를 검색하세요.
| 읽기 용량 단위 | 쓰기 용량 단위 |
|---|---|
|
|
|
|
|
|
|
|
|
AWS CLI 또는 AWS Management Console을 통해 이 작업을 할 수 있습니다.
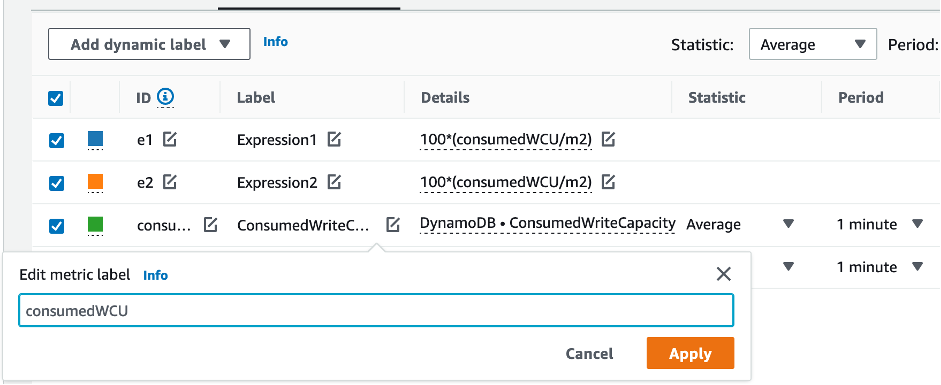
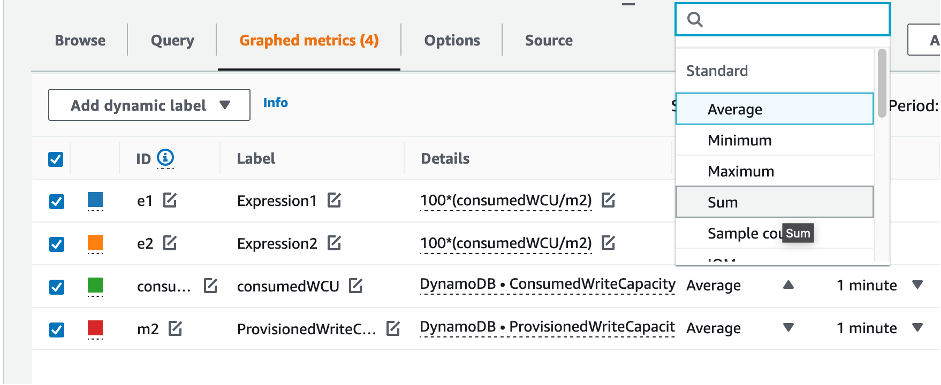
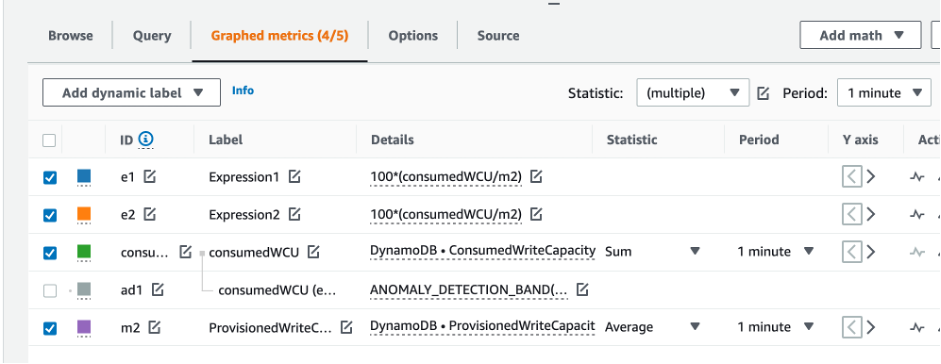
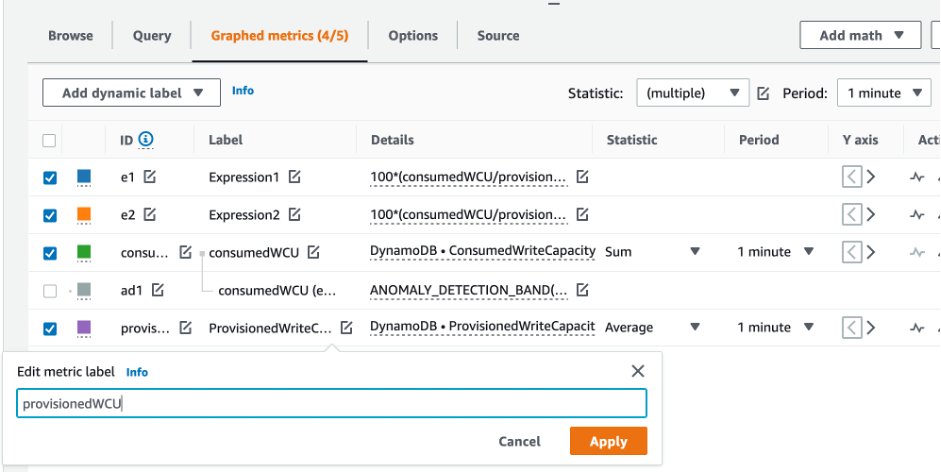
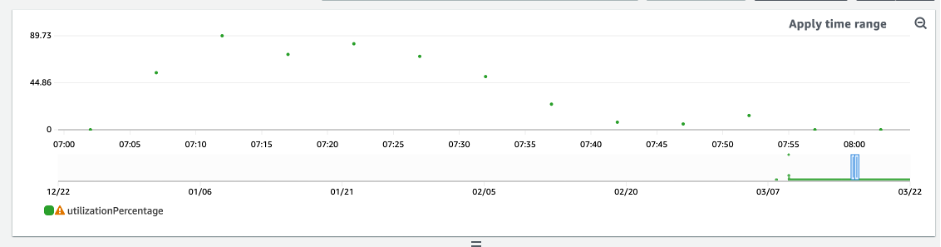
과소 프로비저닝된 DynamoDB 테이블을 식별하는 방법
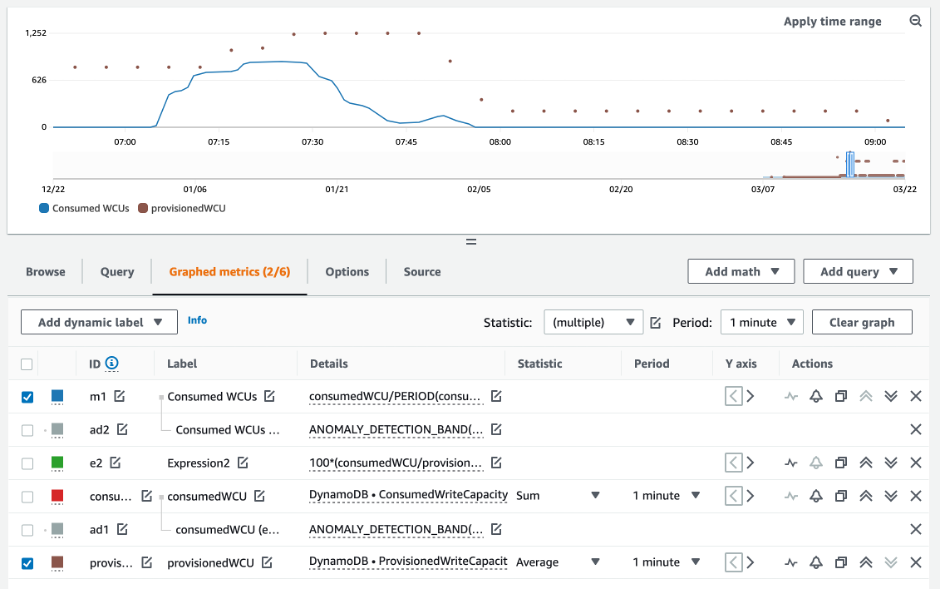
대부분의 워크로드에서 테이블은 프로비저닝된 용량의 80%를 초과하여 지속적으로 소비하는 경우 과소 프로비저닝된 것으로 간주됩니다.
버스트 용량은 고객이 원래 프로비저닝된 것보다 더 많은(테이블에 정의된 초당 프로비저닝된 처리량보다 많은) RCU/WCU를 일시적으로 소비할 수 있도록 하는 DynamoDB 기능입니다. 버스트 용량은 특수 이벤트 또는 사용량 급증으로 인한 갑작스러운 트래픽 증가를 흡수하기 위해 만들어졌습니다. 이 버스트 용량은 지속되지 않습니다. 사용되지 않은 RCU와 WCU가 소진되었을 때 프로비저닝된 용량보다 더 많은 용량을 소비하려고 하면 제한이 발생합니다. 애플리케이션 트래픽이 80% 사용률에 가까워지면 제한 위험이 훨씬 높아집니다.
80% 사용률 규칙은 데이터의 계절성 및 트래픽 증가에 따라 달라집니다. 다음 시나리오를 고려해 보세요.
-
지난 12개월 동안 트래픽이 약 90%의 사용률로 안정적이었다면 테이블의 용량이 적절한 것입니다.
-
애플리케이션 트래픽이 3개월 이내에 매월 8%씩 증가하면 100%에 도달하게 됩니다.
-
애플리케이션 트래픽이 4개월이 조금 넘는 기간 이내에 5%씩 증가해도 100%에 도달하게 됩니다.
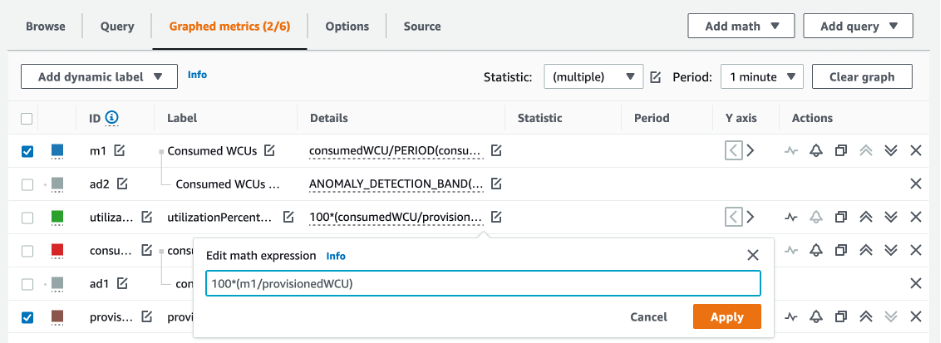
위 쿼리의 결과는 사용률을 보여줍니다. 이를 참고하여 필요에 따라 테이블 용량을 늘리도록 선택하는 데 도움이 될 수 있는 다른 지표(예: 월별 또는 주별 증가율)를 추가로 평가해 보세요. 운영 팀과 협력하여 워크로드와 테이블에 적합한 비율을 정하세요.
일별 또는 주별로 데이터를 분석할 때 데이터가 왜곡되는 특수한 시나리오가 있습니다. 예를 들어 근무 시간 동안 사용량이 급증하다가 근무 시간 외에는 거의 0으로 떨어지는 계절성 애플리케이션의 경우, 프로비저닝된 용량을 늘리거나 줄일 하루 중 시간(및 요일)을 지정하는 Auto Scaling을 예약하면 효과를 볼 수 있습니다. 바쁜 시간을 처리하기 위해 더 높은 용량을 목표로 하는 대신 계절성이 덜 두드러지는 경우 DynamoDB 테이블 Auto Scaling 구성을 활용할 수도 있습니다.
참고
기본 테이블에 대해 DynamoDB Auto Scaling 구성을 생성할 때는 테이블과 연결된 GSI에 대해 다른 구성을 포함해야 한다는 점을 기억하세요.
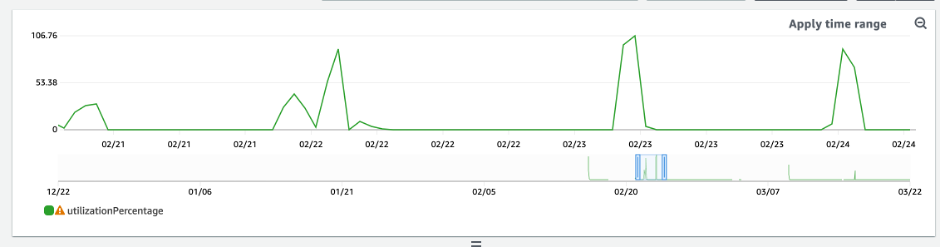
과다 프로비저닝된 DynamoDB 테이블을 식별하는 방법
위 스크립트에서 얻은 쿼리 결과는 일부 초기 분석을 수행하는 데 필요한 데이터 포인트를 제공합니다. 데이터 세트의 여러 간격에 사용률이 20% 미만인 값이 표시되면 테이블이 과다 프로비저닝된 것일 수 있습니다. WCU 및 RCU 수를 줄여야 하는지 여부를 더 자세히 정의하려면 해당 간격의 다른 측정값을 다시 살펴봐야 합니다.
테이블에 낮은 사용 간격이 여러 개 있는 경우 Auto Scaling을 예약하거나 사용률을 기반으로 테이블에 대한 기본 Auto Scaling 정책을 구성하여 Auto Scaling 정책을 사용하면 큰 이점을 얻을 수 있습니다.
워크로드에 사용률이 낮고 제한은 높은 비율(간격의 Max(ThrottleEvents)/Min(ThrottleEvents))이 있는 경우 며칠(또는 몇 시간) 동안 트래픽이 많이 증가하지만 일반적으로는 트래픽이 지속적으로 낮은 변동이 심한 워크로드일 때 이런 일이 발생할 수 있습니다. 이러한 시나리오에서는 예약된 Auto Scaling을 사용하는 것이 유용할 수 있습니다.
