DAX 클러스터 구성
DAX 클러스터는 관리형 클러스터이지만, 애플리케이션 요구 사항에 맞게 구성을 조정할 수 있습니다. DynamoDB API 작업과 긴밀하게 통합되므로, 애플리케이션을 DAX와 통합할 때는 다음 사항을 고려해야 합니다.
이 섹션의 내용
DAX 가격 책정
클러스터 비용은 프로비저닝한 노드의 수와 크기에 따라 달라집니다. 모든 노드는 클러스터에서 노드를 실행하는 시간별로 요금이 청구됩니다. 자세한 내용은 Amazon DynamoDB 요금
캐시 적중은 DynamoDB 비용을 발생시키지 않지만, DAX 클러스터 리소스에 영향을 미칩니다. 캐시 누락으로 인해 DynamoDB 읽기 비용이 발생하고 DAX 리소스가 필요합니다. 쓰기는 DynamoDB 쓰기 비용을 발생시키고 쓰기를 프록시하는 DAX 클러스터 리소스에 영향을 줍니다.
항목 캐시 및 쿼리 캐시
DAX는 항목 캐시와 쿼리 캐시를 유지합니다. 이러한 캐시 간의 차이점을 이해하면 해당 캐시가 애플리케이션에 제공하는 성능 및 일관성 특성을 결정하는 데 도움이 될 수 있습니다.
| 항목 캐시 | 쿼리 캐시 |
|---|---|
| Purpose | |
|
GetItem 및 BatchGetItem API 작업의 결과를 저장합니다. |
쿼리 및 스캔 API 작업의 결과를 저장합니다. 이러한 작업은 특정 항목 키 대신 쿼리 조건에 따라 여러 항목을 반환할 수 있습니다. |
| Access type | |
|
키 기반 액세스를 사용합니다. 애플리케이션이 |
파라미터 기반 액세스를 사용합니다. DAX는 |
| Cache invalidation | |
|
DAX는 다음 시나리오에서 업데이트된 항목을 DAX 클러스터 내 노드의 항목 캐시에 자동으로 복제합니다.
|
쿼리 캐시는 항목 캐시보다 무효화하기가 더 어렵습니다. 항목 업데이트가 캐시된 쿼리 또는 스캔에 직접 매핑되지 않을 수 있습니다. 데이터 일관성을 유지하려면 쿼리 캐시 TTL을 신중하게 조정해야 합니다. DAX 또는 기본 테이블을 통한 쓰기는 TTL이 이전에 캐시된 응답을 만료하고 DAX가 DynamoDB에 대해 새 쿼리를 수행할 때까지 쿼리 캐시에 반영되지 않습니다. |
| Global secondary index | |
Because the GetItem API operation isn't supported on local secondary indexes or global secondary indexes, the item cache only caches reads from the base table. |
Query cache caches queries against both tables and indexes. |
캐시에 대한 TTL 설정 선택
TTL은 데이터가 오래되기 전에 캐시에 저장되는 기간을 결정합니다. 이 기간이 지나면 다음 요청 시 데이터가 자동으로 새로 고쳐집니다. DAX 캐시에 적합한 TTL 설정을 선택하려면 애플리케이션 성능 최적화와 데이터 일관성 간의 균형을 맞춰야 합니다. 모든 애플리케이션에 적용되는 범용 TTL 설정은 존재하지 않으므로, 최적의 TTL 설정은 애플리케이션의 구체적인 특성 및 요구 사항에 따라 달라집니다. 이 권장 가이드를 바탕으로 보수적인 TTL 설정으로 시작하는 것이 좋습니다. 그런 다음 애플리케이션의 성능 데이터 및 인사이트를 기반으로 TTL 설정을 반복적으로 조정하세요.
DAX는 항목 캐시에 대해 가장 오랫동안 사용되지 않음(LRU) 목록을 유지합니다. LRU 목록은 항목이 캐시에 처음 기록된 시점 또는 캐시에서 마지막으로 읽은 시점을 추적합니다. DAX 노드 메모리가 가득 차면 DAX는 아직 만료되지 않았더라도 오래된 항목을 제거하여 새 항목을 위한 공간을 마련합니다. LRU 알고리즘은 항상 활성화되어 있으며 사용자가 구성할 수 없습니다.
애플리케이션에 적합한 TTL 기간을 설정하려면 다음 사항을 고려하세요.
데이터 액세스 패턴 파악
-
읽기 중심의 워크로드 - 읽기 워크로드가 많고 데이터 업데이트 빈도가 낮은 애플리케이션의 경우 TTL 기간을 더 길게 설정하여 캐시 누락 횟수를 줄이세요. TTL 기간이 길면 기본 DynamoDB 테이블에 액세스할 필요성도 줄어듭니다.
-
쓰기 중심의 워크로드 - DAX를 통해 작성되지 않고 업데이트가 잦은 애플리케이션의 경우 캐시가 데이터베이스와 일관성을 유지할 수 있도록 TTL 기간을 짧게 설정하세요. TTL 기간이 짧을수록 오래된 데이터를 제공할 위험도 줄어듭니다.
애플리케이션의 성능 요구 사항 평가
-
지연 시간 민감도 - 애플리케이션에 데이터 새로 고침보다 짧은 지연 시간이 필요한 경우 TTL 기간을 더 길게 사용하세요. TTL 기간이 길수록 캐시 적중률이 극대화되어 평균 읽기 지연 시간이 줄어듭니다.
-
처리량 및 확장성 - TTL 기간이 길수록 DynamoDB 테이블의 부하가 줄어들고 처리량과 확장성이 향상됩니다. 그러나 최신 데이터에 대한 필요성과 균형을 맞춰야 합니다.
캐시 제거 및 메모리 사용량 분석
-
캐시 메모리 제한 - DAX 클러스터의 메모리 사용량을 모니터링합니다. TTL 기간이 길어지면 캐시에 더 많은 데이터를 저장할 수 있으며, 이로 인해 메모리 한도에 도달하여 LRU 기반 제거로 이어질 수 있습니다.
지표와 모니터링을 사용하여 TTL 조정
캐시 적중률 및 누락, CPU 및 메모리 사용률과 같은 지표를 정기적으로 검토하세요. 이러한 지표를 기반으로 TTL 설정을 조정하여 성능과 데이터 최신성 간의 최적의 균형을 찾을 수 있습니다. 캐시 누락이 많고 메모리 사용률이 낮은 경우 TTL 기간을 늘려 캐시 적중률을 높이세요.
비즈니스 요구 사항 및 규정 준수 고려
데이터 보존 정책에 따라 민감한 정보 또는 개인 정보에 설정할 수 있는 최대 TTL 기간이 정해질 수 있습니다.
TTL을 0으로 설정한 경우의 캐시 동작
TTL을 0으로 설정하면 항목 캐시와 쿼리 캐시는 다음과 같은 동작을 나타냅니다.
-
항목 캐시 - LRU 제거 또는 라이트-스루 작업이 발생한 경우에만 캐시의 항목이 새로 고쳐집니다.
-
쿼리 캐시 - 쿼리 응답은 캐시되지 않습니다.
DAX 클러스터로 여러 테이블 캐싱
개별 캐시가 필요하지 않은 작은 DynamoDB 테이블이 여러 개 있는 워크로드의 경우 단일 DAX 클러스터가 이러한 테이블에 대한 요청을 캐싱합니다. 따라서 특히 여러 테이블에 액세스하고 고성능 읽기가 필요한 애플리케이션에 DAX를 보다 유연하고 효율적으로 사용할 수 있습니다.
DynamoDB 데이터 플레인 API와 마찬가지로 DAX 요청에는 테이블 이름이 필요합니다. 동일한 DAX 클러스터에서 여러 테이블을 사용하는 경우 구체적인 구성이 필요하지 않습니다. 그러나 클러스터의 보안 권한이 모든 캐시된 테이블에 대한 액세스를 허용하는지 확인해야 합니다.
여러 테이블과 함께 DAX를 사용하기 위한 고려 사항
DAX를 여러 DynamoDB 테이블과 함께 사용할 때 다음 사항을 고려해야 합니다.
-
메모리 관리 - 여러 테이블과 함께 DAX를 사용할 때는 작업 데이터세트의 전체 크기를 고려해야 합니다. 데이터세트의 모든 테이블은 선택한 노드 유형의 동일한 메모리 공간을 공유합니다.
-
리소스 할당 - DAX 클러스터의 리소스는 캐시된 모든 테이블에서 공유됩니다. 하지만 트래픽이 많은 테이블에서는 인접한 더 작은 테이블에서 데이터가 제거될 수 있습니다.
-
규모의 경제 - 더 작은 리소스를 더 큰 DAX 클러스터로 그룹화하여 트래픽을 더 안정적인 패턴으로 평균화합니다. DAX 클러스터에 필요한 총 읽기 리소스 수를 고려하면 3개 이상의 노드를 보유하는 것도 경제적입니다. 또한, 클러스터에 있는 모든 캐시된 테이블의 가용성도 향상됩니다.
DAX 및 DynamoDB 글로벌 테이블의 데이터 복제
DAX는 리전 기반 서비스이므로, 클러스터는 AWS 리전 내의 트래픽만 인식합니다. 글로벌 테이블은 다른 리전의 데이터를 복제할 때 캐시를 중심으로 작성합니다.
TTL 기간이 길면 오래된 데이터가 기본 리전보다 보조 리전에 더 오래 남아 있을 수 있습니다. 이로 인해 보조 리전의 로컬 캐시에서 캐시 누락이 발생할 수 있습니다.
다음 다이어그램은 소스 리전 A의 글로벌 테이블 수준에서 발생하는 데이터 복제를 보여줍니다. 리전 B의 DAX 클러스터는 소스 리전 A에서 새로 복제된 데이터를 즉시 인식하지 못합니다.
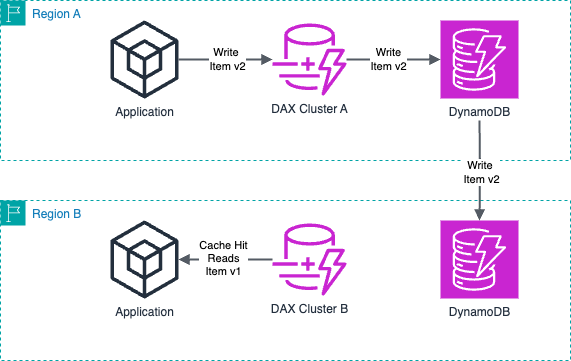
DAX 리전 가용성
DynamoDB 테이블을 지원하는 모든 리전이 DAX 클러스터 배포를 지원하지는 않습니다. 애플리케이션에 DAX를 통한 짧은 읽기 지연 시간이 필요한 경우 먼저 DAX를 지원하는 리전 목록을 검토하세요. 그런 다음 DynamoDB 테이블의 리전을 선택합니다.
DAX 캐싱 동작
DAX는 메타데이터와 음성 캐싱을 수행합니다. 이러한 캐싱 동작을 이해하면 캐시된 항목 및 음성 캐시 항목의 속성 메타데이터를 효과적으로 관리하는 데 도움이 됩니다.
-
메타데이터 캐싱 - DAX 클러스터는 캐시한 항목의 속성 이름에 대한 메타데이터를 무기한 유지 관리합니다. 이 메타데이터는 항목이 만료되거나 캐시에서 제거된 후에도 유지됩니다.
시간이 지남에 따라 무한한 수의 속성 이름을 사용하는 애플리케이션은 DAX 클러스터에서 메모리 부족을 야기할 수 있습니다. 이러한 제한은 최상위 속성 이름에만 적용되며, 중첩 속성 이름에는 적용되지 않습니다. 무제한 속성 이름의 예로는 타임스탬프, UUID 및 세션 ID가 포함됩니다. 타임스탬프와 세션 ID를 속성 값으로 사용할 수 있지만, 더 짧고 예측 가능한 속성 이름을 사용하는 것이 좋습니다.
-
음성 캐싱 - 캐시 누락이 발생하고 DynamoDB 테이블에서 읽은 결과 일치하는 항목이 없는 경우 DAX는 각 항목 또는 쿼리 캐시에 음성 캐시 항목을 추가합니다. 이 항목은 캐시 TTL 기간이 만료되거나 라이트-스루 작업이 발생할 때까지 유지됩니다. DAX는 향후 요청을 위해 이 음성 캐시 항목을 계속 반환합니다.
음성 캐싱 동작이 애플리케이션 패턴에 맞지 않는 경우 DAX가 빈 결과를 반환할 때 DynamoDB 테이블을 직접 읽어보세요. 또한, 캐시에서 빈 결과가 오래 지속되지 않도록 하고 테이블과의 일관성을 높이려면 TTL 캐시 기간을 짧게 설정하는 것이 좋습니다.
