이 페이지는 Vaults와 2012RESTAPI년의 원본을 사용하는 S3 Glacier 서비스의 기존 고객만 사용할 수 있습니다.
아카이브 스토리지 솔루션을 찾고 있다면 Amazon S3, S3 Glacier Instant Retrieval , S33 S3 Glacier Flexible Retrieval 및 S3 Glacier Deep Archive 의 S3 Glacier 스토리지 클래스를 사용하는 것이 좋습니다. Amazon S3 이러한 스토리지 옵션에 대한 자세한 내용은 Amazon S3 사용 설명서의 S3 Glacier 스토리지 클래스
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 다운로드 시 체크섬 수신
작업 시작 API(작업 시작 (POST작업) 참조)를 사용하여 아카이브를 가져올 때는 옵션으로 아카이브를 가져오는 범위를 지정할 수 있습니다. 마찬가지로 작업 출력 가져오기 API(작업 출력 가져오기(GET output) 참조)를 사용하여 데이터를 다운로드할 때도 옵션으로 다운로드할 데이터 범위를 지정할 수 있습니다. 이러한 범위에는 아카이브 데이터를 가져오거나 다운로드할 때 반드시 알고 있어야 할 두 가지 특성이 있습니다. 가져오기 범위는 아카이브에 대해 메가바이트 정렬로 이루어져야 합니다. 또한 데이터를 다운로드할 때 체크섬 값을 수신하려면 가져오기 범위와 다운로드 범위 모두 트리-해시 정렬로 이루어져야 합니다. 이러한 두 가지 유형의 범위 정렬은 아래와 같이 정의할 수 있습니다.
-
메가바이트 정렬 - 범위 [StartByte, EndBytes] 는 1MB로 나눌 수 있는 경우 메가바이트 (1024*1024) 로 StartBytes정렬되고 1을 EndBytes더한 값은 1MB로 나눌 수 있거나 지정된 아카이브의 끝 (아카이브 바이트 크기에서 1을 뺀 값) 과 같을 때 정렬됩니다. 작업 시작 API에서 사용하는 범위는 지정하는 경우에 한해 메가바이트 정렬로 이루어져야 합니다.
-
트리 해시 정렬 - 범위 [StartBytes, EndBytes] 는 범위 위에 빌드된 트리 해시의 루트가 전체 아카이브의 트리 해시에 있는 노드와 동일한 경우에만 아카이브를 기준으로 정렬된 트리 해시입니다. 데이터를 다운로드하면서 체크섬 값을 수신하려면 가져오기 범위와 다운로드 범위 모두 트리-해시 정렬로 이루어져야 합니다. 아카이브 트리-해시에 대한 범위 및 범위 관계 예는 트리-해시 예제: 트리-해시로 정렬하여 아카이브 범위 가져오기 단원을 참조하십시오.
트리-해시로 정렬되는 범위는 메가바이트로도 정렬됩니다. 하지만 메가바이트로 정렬된 범위가 꼭 트리-해시로 정렬될 필요는 없습니다.
다음은 아카이브 데이터를 다운로드하면서 체크섬 값을 수신하는 경우에 대한 설명입니다.
-
작업 시작 요청에서 가져오기 범위를 지정하지 않고 작업 가져오기 요청에서 전체 아카이브를 다운로드하는 경우
-
작업 시작 요청에서 가져오기 범위를 지정하지 않고 작업 가져오기 요청에서 다운로드할 트리-해시 정렬 범위를 지정하는 경우
-
작업 시작 요청에서 가져올 트리-해시 정렬 범위를 지정하고 작업 가져오기 요청에서 전체 범위를 다운로드하는 경우
-
작업 시작 요청에서 가져올 트리-해시 정렬 범위를 지정하고 작업 가져오기 요청에서 다운로드할 트리-해시 정렬 범위를 지정하는 경우
작업 시작 요청에서 트리-해시로 정렬하지 않고 가져올 범위를 지정하더라도 아카이브 데이터를 가져올 수는 있지만 작업 가져오기 요청에서 데이터를 다운로드할 때 체크섬 값은 반환되지 않습니다.
트리-해시 예제: 트리-해시로 정렬하여 아카이브 범위 가져오기
볼트에 6.5MB의 아카이브가 저장되어 있으며 여기에서 2MB를 가져온다고 가정하겠습니다. 이때는 작업 시작하기 요청에서 2MB 범위의 지정 방식에 따라 데이터 다운로드 시 데이터 체크섬 값의 수신 여부가 결정됩니다. 다음은 6.5MB 아카이브에서 다운로드할 수 있는 두 가지 2MB 범위를 설명한 다이어그램입니다. 두 범위 모두 메가바이트로 정렬되지만 하나만 트리-해시로 정렬됩니다.
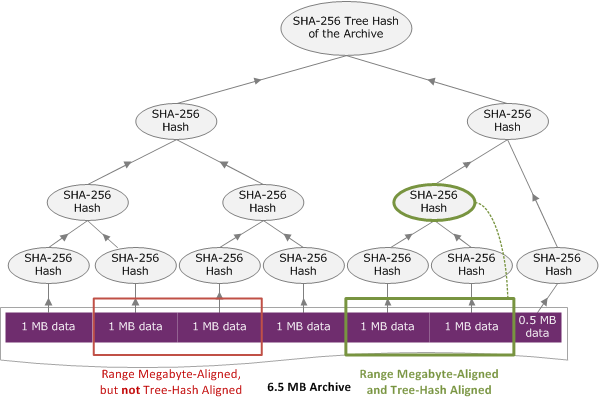
트래-해시 정렬 범위의 지정
이번 단원에서는 트리-해시 정렬 범위의 구성 요소를 정확하게 지정할 수 있는 방법에 대해서 설명합니다. 트리-해시 정렬 범위는 아카이브 일부를 다운로드하면서 가져올 데이터 범위와 가져온 데이터에서 다운로드할 범위를 지정할 때 매우 중요합니다. 이 두 범위를 트리-해시로 정렬하는 경우에는 데이터 다운로드 시 체크섬 데이터까지 수신하게 됩니다.
새 트리 해시가 [A, B]에서 만들어지고, 해당 범위의 트리 해시의 루트가 전체 아카이브의 트리 해시 노드에 해당할 경우, 그리고 이러한 경우일 때만 아카이브에 대한 범위 [A, B]가 트리 해시로 정렬됩니다. 트리-해시 예제: 트리-해시로 정렬하여 아카이브 범위 가져오기 다이어그램에서 이러한 예를 볼 수 있습니다. 이번에는 트리-해시 정렬을 위한 지정 방법에 대해서 살펴보겠습니다.
이번에는 [P, Q)가 N메가바이트(MB)의 아카이브에 대한 범위 쿼리이고, 여기에서 P와 Q는 1MB의 승수라고 가정합니다. 이때 실제로 포함되는 범위는 [PMB, QMB-1바이트]이지만, 여기에서는 간단명료하게 [P, Q)로 나타냈습니다. 이를 감안하여 다음 내용을 살펴보십시오.
-
P가 홀수인 경우 가능한 트리 해시 정렬 범위는 한 가지, 즉 [P, P+1MB)가 유일합니다.
-
P가 짝수이고 k가 최대 수인 경우 P는 2k*X로 쓸 수 있고, P로시작하는 트리 해시 정렬 범위는 최대 k개 입니다. X는 0보다 큰 정수입니다. 결과적으로 트리-해시 정렬 범위는 다음 카테고리에 해당합니다.
-
각 i마다(0 <= i <= k)이고, P + 2i < N인 경우에는 [P, Q + 2i)가 트리-해시 정렬 범위에 해당합니다.
-
P = 0은 A = 2[lgN]*0인 특수한 경우입니다.
-
