Athena에서 EXPLAIN 및 EXPLAIN ANALYZE 사용
EXPLAIN 문은 지정된 SQL 문의 논리적 또는 분산 실행 계획을 보여주거나 SQL 문의 유효성을 검사합니다. 결과를 텍스트 형식 또는 데이터 형식으로 출력하여 그래프로 렌더링할 수 있습니다.
참고
EXPLAIN 구문을 사용하지 않고도 쿼리에 대한 논리적 계획 및 분산된 계획의 그래픽 표현을 Athena 콘솔에서 볼 수 있습니다. 자세한 내용은 SQL 쿼리에 대한 실행 계획 보기 단원을 참조하십시오.
EXPLAIN ANALYZE 문은 지정된 SQL 문의 분산 실행 계획과 SQL 쿼리의 각 작업 계산 비용을 모두 표시합니다. 결과를 텍스트 또는 JSON 형식으로 출력할 수 있습니다.
고려 사항 및 제한 사항
Athena의EXPLAIN 및 EXPLAIN ANALYZE 문에는 다음과 같은 제한이 있습니다.
-
EXPLAIN쿼리는 어떠한 데이터도 스캔하지 않으므로 Athena는 이에 대해 과금하지 않습니다. 그러나EXPLAIN쿼리는 AWS Glue를 호출하여 테이블 메타데이터를 검색하기 때문에 호출이 Glue의 프리 티어 한도를 초과할 경우 Glue에서 요금이 발생할 수 있습니다. -
EXPLAIN ANALYZE쿼리가 실행되면 스캔 데이터를 수행하고 Athena가 스캔한 데이터 양에 대해 요금을 청구하기 때문입니다. -
Lake Formation에 정의된 행 또는 셀 필터링 정보와 쿼리 통계 정보는
EXPLAIN및EXPLAIN ANALYZE의 출력에 표시되지 않습니다.
EXPLAIN 구문
EXPLAIN [ (option[, ...]) ]statement
옵션은 다음 중 하나일 수 있습니다.
FORMAT { TEXT | GRAPHVIZ | JSON } TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
FORMAT 옵션이 지정되지 않은 경우 출력은 기본적으로 TEXT 형식입니다. IO 유형은 쿼리에서 읽는 테이블 및 스키마에 대한 정보를 제공합니다.
EXPLAIN ANALYZE 구문
EXPLAIN에 포함된 출력 외에도 EXPLAIN
ANALYZE 출력에는 CPU 사용량, 입력 행 수 및 출력 행 수와 같은 지정된 쿼리에 대한 런타임 통계도 포함됩니다.
EXPLAIN ANALYZE [ (option[, ...]) ]statement
옵션은 다음 중 하나일 수 있습니다.
FORMAT { TEXT | JSON }
FORMAT 옵션이 지정되지 않은 경우 출력은 기본적으로 TEXT 형식입니다. EXPLAIN ANALYZE에 대한 모든 쿼리는 DISTRIBUTED이며, TYPE 옵션은 EXPLAIN ANALYZE에 사용할 수 없기 때문입니다.
statement는 다음 중 하나일 수 있습니다.
SELECT CREATE TABLE AS SELECT INSERT UNLOAD
EXPLAIN 예제
EXPLAIN에 대한 다음 예는 더 간단한 예에서 더 복잡한 예로 진행됩니다.
다음 예에서 EXPLAIN은 Elastic Load Balancing 로그 기반 SELECT 쿼리에 대한 실행 계획을 보여줍니다. 형식은 기본적으로 텍스트 출력입니다.
EXPLAIN SELECT request_timestamp, elb_name, request_ip FROM sampledb.elb_logs;
결과
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULARAthena 콘솔을 사용하여 쿼리 계획을 그래프로 작성할 수 있습니다. Athena 쿼리 편집기에 다음과 같이 SELECT 문을 입력한 다음 EXPLAIN을 선택합니다.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey
Athena 쿼리 편집기의 Explain 페이지가 열리고 쿼리에 대한 분산 계획과 논리적 계획이 표시됩니다. 다음 그래프는 예제의 논리적 계획을 보여줍니다.
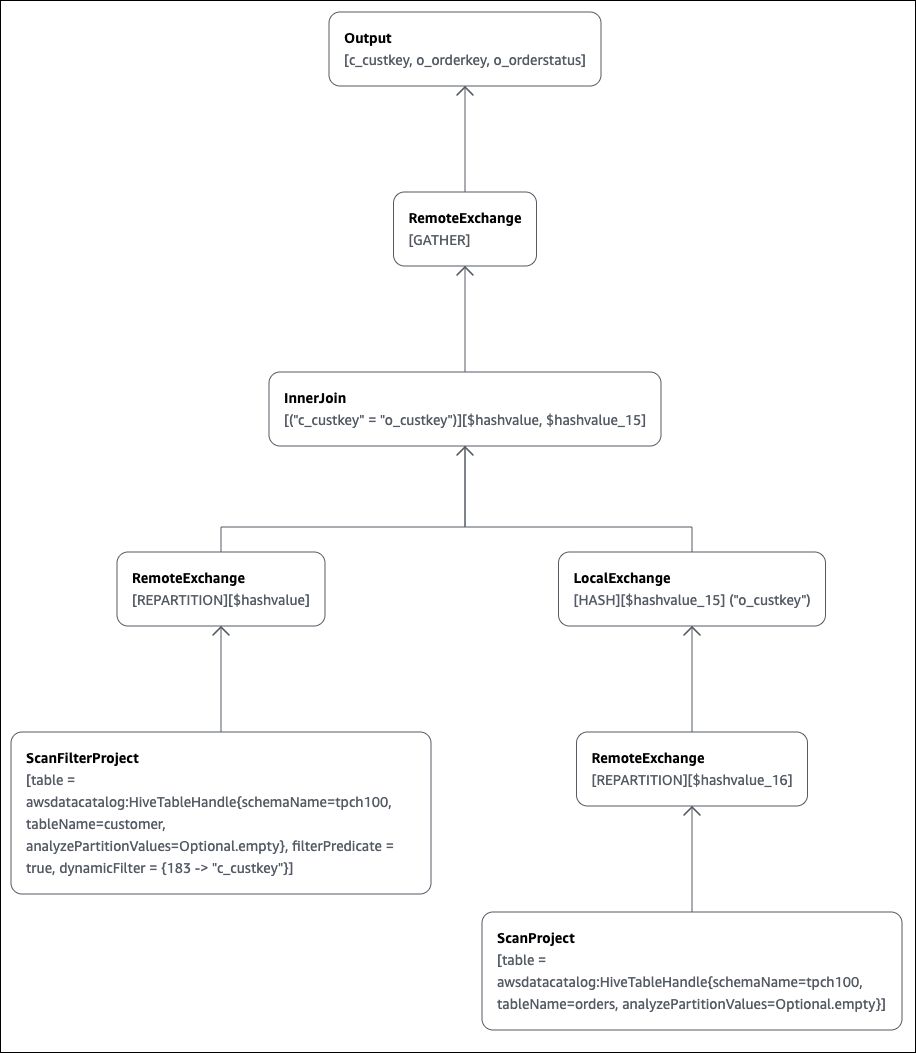
중요
현재 일부 파티션 필터는 Athena에서 쿼리에 적용하더라도 중첩 연산자 트리 그래프에 표시되지 않을 수도 있습니다. 이러한 필터의 효과를 확인하려면 쿼리에서 EXPLAIN 또는 EXPLAIN
ANALYZE를 실행하고 결과를 확인합니다.
Athena 콘솔에서 쿼리 계획 그래프 작성 기능 사용에 대한 자세한 내용은 SQL 쿼리에 대한 실행 계획 보기 단원을 참조하세요.
분할된 테이블을 쿼리할 때 분할된 키에 필터링 조건자를 사용하면 쿼리 엔진은 조건자를 분할된 키에 적용해 읽는 데이터의 양을 줄입니다.
다음 예제에서는 EXPLAIN 쿼리를 사용하여 분할된 테이블에 대한 SELECT 쿼리의 파티션 정리를 확인합니다. 먼저 CREATE TABLE 문은 tpch100.orders_partitioned 테이블을 생성합니다. 테이블은 o_orderdate 열에서 분할됩니다.
CREATE TABLE `tpch100.orders_partitioned`( `o_orderkey` int, `o_custkey` int, `o_orderstatus` string, `o_totalprice` double, `o_orderpriority` string, `o_clerk` string, `o_shippriority` int, `o_comment` string) PARTITIONED BY ( `o_orderdate` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://amzn-s3-demo-bucket/<your_directory_path>/'
SHOW PARTITIONS 명령으로 표시된 것처럼 tpch100.orders_partitioned 테이블에는 o_orderdate에 여러 개의 파티션이 있습니다.
SHOW PARTITIONS tpch100.orders_partitioned; o_orderdate=1994 o_orderdate=2015 o_orderdate=1998 o_orderdate=1995 o_orderdate=1993 o_orderdate=1997 o_orderdate=1992 o_orderdate=1996
다음 EXPLAIN 쿼리는 지정된 SELECT 문의 파티션 정리를 확인합니다.
EXPLAIN SELECT o_orderkey, o_custkey, o_orderdate FROM tpch100.orders_partitioned WHERE o_orderdate = '1995'
결과
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR결과에서 굵은 텍스트는 o_orderdate =
'1995' 조건자가 PARTITION_KEY에 적용되었음을 나타냅니다.
다음 EXPLAIN 쿼리는 SELECT 문의 조인 순서 및 조인 유형을 확인합니다. 이와 같은 쿼리를 사용하면 쿼리 메모리 사용량을 검사하여 EXCEEDED_LOCAL_MEMORY_LIMIT 오류가 발생할 확률을 줄일 수 있습니다.
EXPLAIN (TYPE DISTRIBUTED) SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.customer c JOIN tpch100.orders o ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
결과
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR예제 쿼리는 성능 향상을 위해 크로스 조인으로 최적화되었습니다. 결과는 tpch100.orders가 BROADCAST 배포 유형으로 배포될 예정임을 보여줍니다. 이는 tpch100.orders 테이블이 조인 작업을 수행하는 모든 노드에 배포될 것임을 의미합니다. BROADCAST 배포 유형은 tpch100.orders 테이블의 모든 필터링된 결과가 조인 작업을 수행하는 각 노드의 메모리에 부합할 것을 요구합니다.
그러나 tpch100.customer 테이블은 tpch100.orders보다 작습니다. tpch100.customer는 더 적은 메모리를 필요로 하므로 쿼리를 tpch100.orders 대신에 BROADCAST
tpch100.customer에 다시 작성할 수 있습니다. 이렇게 하면 쿼리가 EXCEEDED_LOCAL_MEMORY_LIMIT 오류를 수신할 가능성이 낮아집니다. 이 전략은 다음 사항을 가정합니다.
-
tpch100.customer.c_custkey가tpch100.customer테이블에서 고유합니다. -
tpch100.customer와tpch100.orders사이에 일대다 매핑 관계가 있습니다.
다음 예제에서는 다시 작성된 쿼리를 보여줍니다.
SELECT c.c_custkey, o.o_orderkey, o.o_orderstatus FROM tpch100.orders o JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes. ON c.c_custkey = o.o_custkey WHERE c.c_custkey = 123
EXPLAIN 쿼리를 사용하여 필터링 조건자의 영향을 확인할 수 있습니다. 다음 예제와 같이 결과를 사용하여 영향이 없는 조건자를 제거할 수 있습니다.
EXPLAIN SELECT c.c_name FROM tpch100.customer c WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT) AND c.c_custkey BETWEEN 1000 AND 2000 AND c.c_custkey = 1500
결과
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULAR결과의 filterPredicate는 옵티마이저가 원래 세 개인 조건자를 두 개의 조건자로 병합하고 애플리케이션의 순서를 변경했음을 보여줍니다.
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
결과에 따르면 AND c.c_custkey BETWEEN
1000 AND 2000 조건자는 아무런 영향이 없으므로 쿼리 결과의 변화 없이 이 조건자를 제거할 수 있습니다.
EXPLAIN 쿼리의 결과에 사용된 용어에 관한 자세한 내용은 Athena EXPLAIN 문 결과 이해 단원을 참조하세요.
EXPLAIN ANALYZE 예제
다음 예에서는 EXPLAIN ANALYZE 쿼리 및 출력 예를 보여줍니다.
다음 예에서 EXPLAIN ANALYZE는 CloudFront 로그의 SELECT 쿼리에 대한 실행 계획 및 계산 비용을 보여줍니다. 형식은 기본적으로 텍스트 출력입니다.
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
결과
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULAR다음 예에서는 CloudFront 로그 기반 SELECT 쿼리에 대한 실행 계획 및 계산 비용을 보여줍니다. 이 예에서는 JSON을 출력 형식으로 지정합니다.
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
결과
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}추가 리소스
자세한 내용은 다음 리소스를 참조하세요.
