기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Google Cloud Storage를 사용하여 AWS DataSync 전송 구성
를 사용하면 Google Cloud Storage와 다음 AWS 스토리지 서비스 간에 데이터를 전송할 AWS DataSync수 있습니다.
-
Amazon S3
-
Amazon EFS
-
Amazon FSx for Windows File Server
-
Amazon FSx for Lustre
-
Amazon FSx for OpenZFS
-
Amazon FSx for NetApp ONTAP
전송 설정을 시작하려면 Google Cloud Storage의 위치를 생성합니다. 이 위치를 전송의 소스 또는 대상으로 사용할 수 있습니다. DataSync 에이전트는 Google Cloud Storage와 Amazon EFS 간에, 또는 Amazon FSx 간에 데이터를 전송하는 경우나 기본 모드 작업을 사용하는 경우에만 필요합니다. Google Cloud Storage와 Amazon S3 간 확장 모드 데이터 전송에는 에이전트가 필요하지 않습니다.
참고
Google Cloud Storage와 간의 프라이빗 클라우드 연결을 위해 에이전트와 함께 기본 모드를 AWS사용합니다.
개요
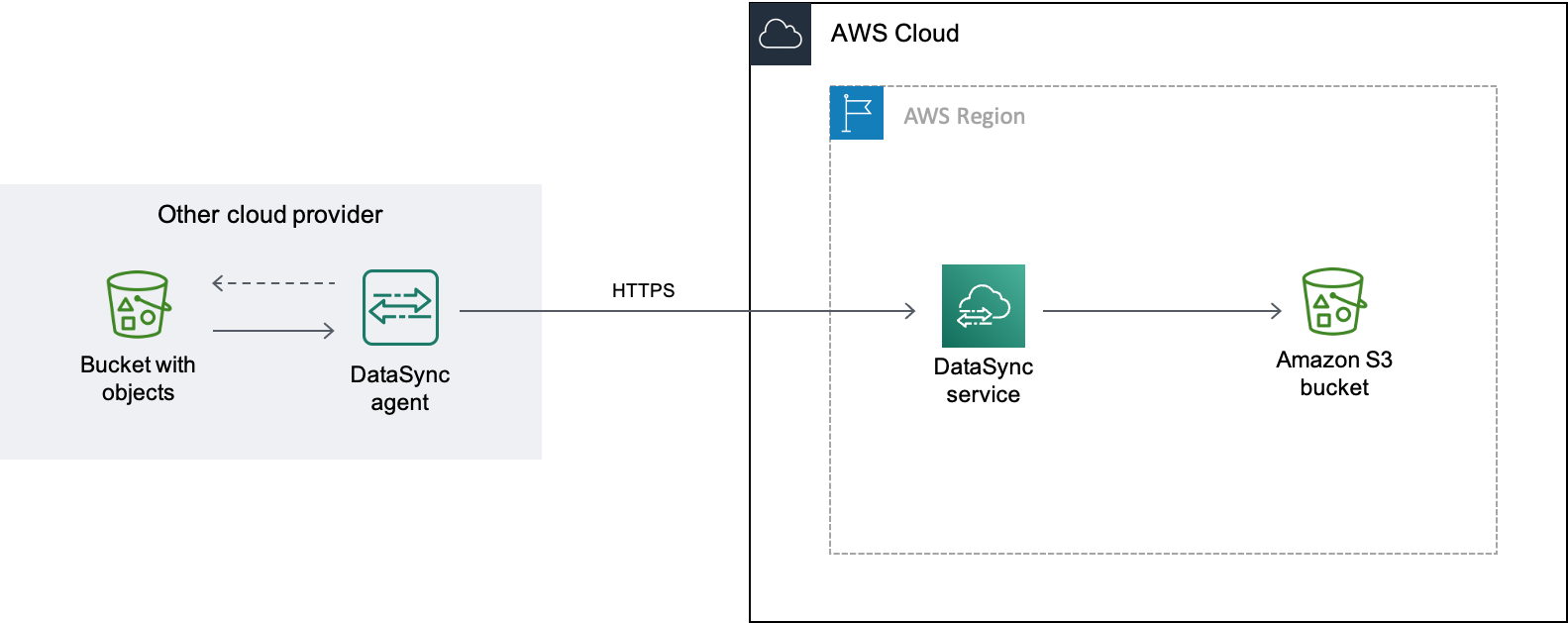
DataSync는 데이터 전송에 Google Cloud Storage XML API
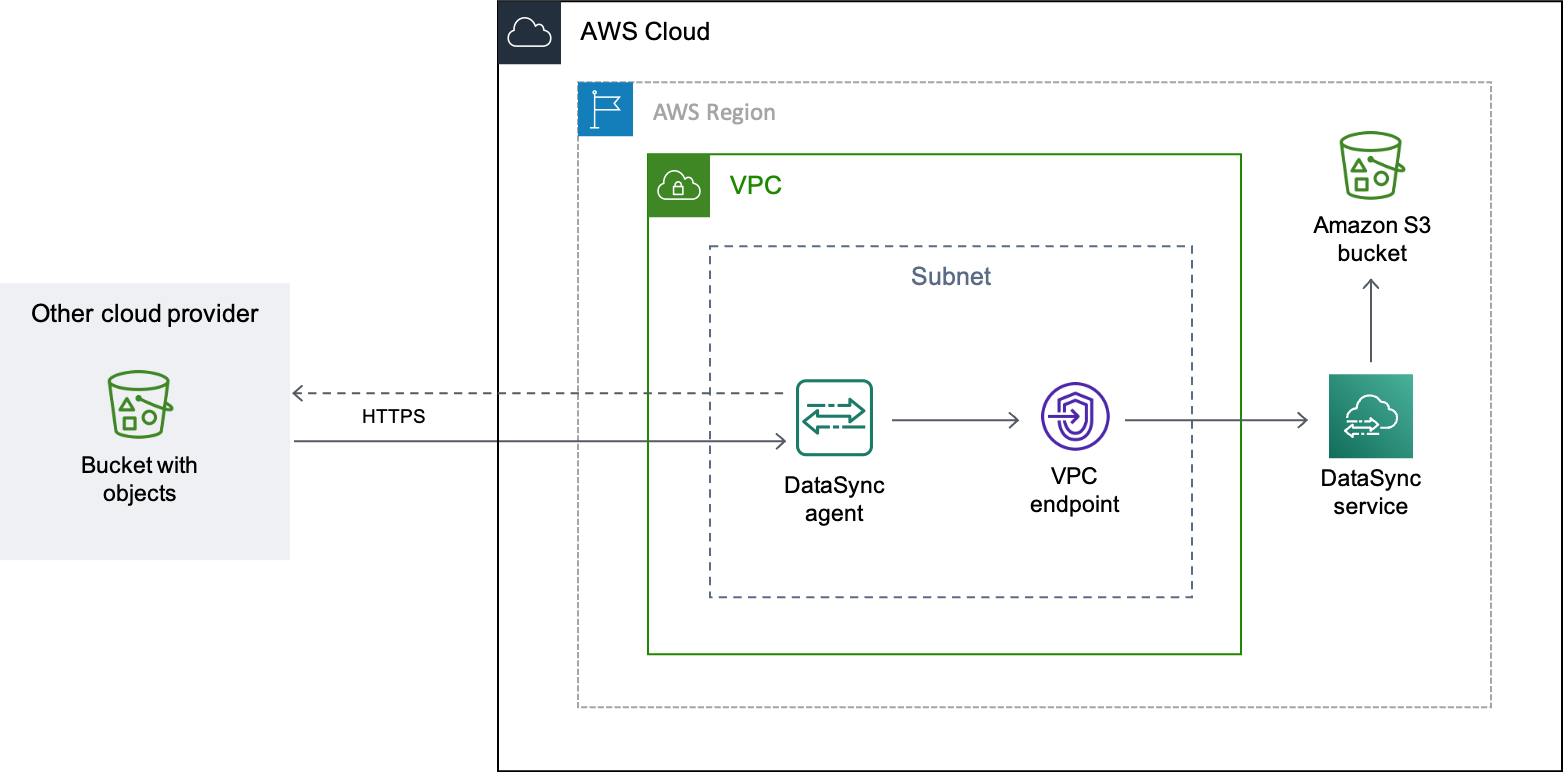
전송에 기본 모드를 사용하는 경우 Google Cloud Storage 또는 Amazon VPC에 에이전트를 배포할 수 있습니다.
비용
이 마이그레이션과 관련된 수수료에는 다음이 포함됩니다.
-
Google 컴퓨팅 엔진
가상 머신 인스턴스 실행(Google 클라우드에 사용자 DataSync 에이전트를 배포하는 경우) -
Amazon EC2
인스턴스 실행(사용자 DataSync 에이전트를 AWS내부 VPC에 배포하는 경우) -
DataSync
를 사용하여 데이터 전송. 여기에는 Google Cloud Storage 및 Amazon S3와 관련된 요청 요금이 포함됩니다(S3가 사용자 전송 위치인 경우) -
Google Cloud Storage
밖으로 데이터 전송 -
Amazon S3
에 데이터 저장
사전 조건
아직 다음 사항을 수행하지 않았다면 시작하기 전에 이를 수행합니다.
-
AWS(으)로 전송하려는 객체가 포함된 Google Cloud Storage 버킷을 생성
합니다. -
객체가 AWS에 들어오면 저장할 수 있는 Amazon S3 버킷을 생성합니다.
Google Cloud Storage 버킷에 HMAC 키 생성
DataSync는 Google 서비스 계정과 연결된 HMAC 키를 사용하여 데이터를 전송하는 버킷을 인증하고 이를 읽습니다. (HMAC 키를 만드는 방법에 대한 자세한 지침은 Google Cloud Storage 설명서
HMAC 키 생성
-
Google 서비스 계정용 HMAC 키를 만드세요.
-
Google 서비스 계정에 최소한
Storage Object Viewer권한이 있는지 확인하세요. -
HMAC 키 액세스 ID와 비밀 번호를 안전한 위치에 저장합니다.
이러한 항목은 나중에 DataSync 소스 위치를 구성하는 데 필요합니다.
2단계: 사용자 네트워크 구성
네트워크 구성은 전송 시 DataSync 에이전트를 사용하는 경우에만 필요합니다. 마이그레이션에 필요한 네트워크 요구 사항은 사용자가 선택한 에이전트 배포 위치에 따라 달라집니다.
Google Cloud에서 DataSync 에이전트를 호스팅하려면 DataSync가 퍼블릭 엔드포인트를 통해 전송을 할 수 있도록 네트워크를 구성합니다.
에이전트를 호스팅하려면 인터페이스 엔드포인트가 있는 VPC가 AWS필요합니다. DataSync는 VPC 엔드포인트를 사용하여 전송을 용이하게 합니다.
VPC 엔드포인트에 맞게 네트워크를 구성하려면
-
VPC가 없는 경우 S3 버킷 AWS 리전 과 동일한에 VPC를 생성합니다.
-
DataSync에 대한 VPC 엔드포인트를 생성합니다.
-
DataSync가 VPC 서비스 엔드포인트를 통해 전송을 허용하도록 사용자 네트워크를 구성합니다.
이렇게 하려면 VPC 서비스 엔드포인트와 연결된 보안 그룹을 수정합니다.
3단계: DataSync 에이전트 생성(선택 사항)
DataSync 에이전트는 기본 모드 작업을 사용할 때만 필요합니다. 확장 모드를 사용하여 GCS(Google Cloud Storage)와 Amazon S3 간에 전송하는 경우 에이전트가 필요하지 않습니다. 기본 모드를 사용하려면 GCS 버킷에 액세스할 수 있는 DataSync 에이전트가 필요합니다.
이 시나리오에서 DataSync 에이전트는 Google Cloud 환경에서 실행됩니다.
시작하기 전: Google 클라우드 CLI를 설치합니다
Google 클라우드용 에이전트를 생성하려면
-
https://console.aws.amazon.com/datasync/
AWS DataSync 콘솔을 엽니다. -
왼쪽 탐색 창에서 에이전트를 선택한 다음, 에이전트 생성을 선택합니다.
-
하이퍼바이저의 경우 VMware ESXi를 선택한 다음 이미지 다운로드를 선택하여 에이전트가 포함된
.zip파일을 다운로드합니다. -
터미널을 엽니다. 다음 명령을 실행하여 이미지의 압축을 풉니다.
unzip AWS-DataSync-Agent-VMWare.zip -
다음 명령을 실행하여
aws-datasync로 시작하는 에이전트.ova파일의 내용을 추출합니다.tar -xvf aws-datasync-2.0.1655755445.1-x86_64.xfs.gpt.ova -
다음 Google Cloud CLI 명령어를 실행하여 에이전트의
.vmdk파일을 Google Cloud로 가져옵니다.gcloud compute images import aws-datasync-2-test \ --source-file INCOMPLETE-aws-datasync-2.0.1655755445.1-x86_64.xfs.gpt-disk1.vmdk \ --os centos-7참고
.vmdk파일을 가져오는 데 최대 2시간이 걸릴 수 있습니다. -
방금 가져온 에이전트 이미지의 VM 인스턴스를 만들고 시작합니다.
인스턴스에는 다음과 같은 에이전트 구성이 필요합니다. (인스턴스를 만드는 방법에 대한 자세한 지침은 Google Cloud Compute Engine 설명서
를 참조하세요.) -
머신 유형은 다음 중 하나를 선택합니다.
-
e2-standard-8 - 최대 2천만 개의 객체를 처리하는 DataSync 작업 실행.
-
e2-standard-16 - 2천만 개 이상의 객체를 처리하는 DataSync 작업 실행.
-
-
부팅 디스크 설정은 커스텀 이미지 섹션으로 갑니다. 그런 다음 방금 가져온 DataSync 에이전트 이미지를 선택합니다.
-
서비스 계정 설정에서 Google 서비스 계정(1단계에서 사용한(와)과 동일한 계정)을 선택합니다.
-
방화벽 설정에서 HTTP(포트 80) 트래픽을 허용하는 옵션을 선택합니다.
DataSync 에이전트를 활성화하려면 에이전트에 포트 80이 열려 있어야 합니다. 이 포트는 공개적으로 액세스 되지 않아도 됩니다. 활성화되면 DataSync는 포트를 닫습니다.
-
-
VM 인스턴스를 실행한 후 해당 퍼블릭 IP 주소를 메모해 둡니다.
에이전트를 활성화하려면 이 IP 주소가 필요합니다.
-
DataSync 콘솔로 되돌아 갑니다. 에이전트 이미지를 다운로드한 에이전트 생성 화면에서 다음을 수행하여 에이전트를 활성화합니다.
-
엔드포인트 유형에서 공용 서비스 엔드포인트 옵션(예: 미국 동부 오하이오의 공공 서비스 엔드포인트)을 선택합니다.
-
활성화 키서 에이전트로부터 자동으로 활성화 키 받기를 선택합니다.
-
에이전트 주소에는 방금 생성한 에이전트 VM 인스턴스의 퍼블릭 IP 주소를 입력합니다.
-
Get key를 선택합니다.
-
-
에이전트 이름을 입력한 다음 에이전트 생성을 선택합니다.
에이전트가 온라인 상태이며 데이터를 전송할 준비가 되어 있습니다.
이 시나리오에서 에이전트는와 연결된 VPC에서 Amazon EC2 인스턴스로 실행됩니다 AWS 계정.
시작하기 전:(AWS Command Line InterfaceAWS CLI)를 설정하세요.
VPC용 에이전트를 만들려면
-
터미널을 엽니다. S3 버킷과 연결된 계정을 사용하도록 AWS CLI 프로필을 구성해야 합니다.
-
다음 명령을 복사합니다.
vpc-regionus-east-1).aws ssm get-parameter --name /aws/service/datasync/ami --regionvpc-region -
명령을 실행합니다. 출력에 표시된
"Value"속성을 메모해 둡니다.이 값은 사용자가 지정한 리전의 DataSync Amazon Machine Image(AMI) ID입니다. 예를 들어 AMI ID는
ami-1234567890abcdef0과 같을 수 있습니다. -
다음 URL을 복사합니다. 다시 한번,
vpc-regionami-idhttps://console.aws.amazon.com/ec2/v2/home?region=vpc-region#LaunchInstanceWizard:ami=ami-id -
브라우저에 URL을 붙여 넣습니다.
의 Amazon EC2 인스턴스 시작 페이지가 AWS Management Console 표시됩니다.
-
인스턴스 유형에서 DataSync 에이전트용 권장 Amazon EC2 인스턴스 중 하나를 선택합니다.
-
키 페어 이름에서 기존 키 페어를 선택하거나 새 이름을 생성합니다.
-
네트워크 설정에서 에이전트를 배포하려는 VPC와 서브넷을 선택합니다.
-
인스턴스 시작을 선택합니다.
-
Amazon EC2 인스턴스가 실행되면 VPC 엔드포인트를 선택합니다.
4단계: Google Cloud Storag 버킷에 DataSync 소스 위치 생성
Google Cloud Storage 버킷의 DataSync 위치를 설정하려면 1단계에서 생성한 HMAC 키의 액세스 ID와 비밀번호가 필요합니다.
DataSync 소스 위치를 만들려면
https://console.aws.amazon.com/datasync/
AWS DataSync 콘솔을 엽니다. 왼쪽 탐색 창에서 데이터 전송을 펼친 다음, 위치와 위치 생성을 선택합니다.
-
위치 유형에서 객체 스토리지를 선택합니다.
-
서버에
storage.googleapis.com를 입력합니다. -
버킷 이름에 Google Cloud Storage 버킷의 이름을 입력합니다.
-
폴더에는 객체 접두사를 입력합니다.
DataSync는 이 접두사가 있는 객체만 복사합니다.
-
전송에 에이전트가 필요한 경우 에이전트 사용을 선택한 다음 3단계에서 생성한 에이전트를 선택합니다.
-
추가 설정을 폅니다. 서버 프로토콜에서 HTTPS를 선택합니다. 서버 포트에서 443을 선택합니다.
-
인증 섹션까지 아래로 스크롤합니다. 자격 증명 필요 확인란이 선택되어 있는지 확인하고 다음을 수행하세요.
-
액세스 키에 사용자 HMAC 키의 액세스 ID를 입력합니다.
-
비밀 키에 HMAC 키의 비밀 키를 직접 입력하거나 키가 포함된 AWS Secrets Manager 비밀을 지정합니다. 자세한 내용은 스토리지 위치에 대한 자격 증명 제공을 참조하세요.
-
-
위치 생성을 선택합니다.
5단계: S3 버킷용 DataSync 대상 위치 생성
데이터가 최종적으로 가야 할 DataSync 위치가 필요합니다.
DataSync 대상 위치를 만들려면
https://console.aws.amazon.com/datasync/
AWS DataSync 콘솔을 엽니다. 왼쪽 탐색 창에서 데이터 전송을 펼쳐서 위치와 위치 생성을 선택합니다.
-
VPC에 DataSync 에이전트를 배포한 경우이 자습서에서는 S3 버킷이 VPC 및 DataSync 에이전트 AWS 리전 와 동일한에 있다고 가정합니다.
6단계: DataSync 작업 생성 및 시작
소스 및 대상 위치가 구성된 상태에서 데이터를 이동할 수 있습니다 AWS.
DataSync 작업을 생성하고 시작하려면
https://console.aws.amazon.com/datasync/
AWS DataSync 콘솔을 엽니다. 왼쪽 탐색 창에서 데이터 전송을 확장한 다음 작업을 선택하고 작업 생성을 선택합니다.
-
소스 위치 구성 페이지에서 다음 작업을 수행하세요.
-
기존 위치 선택을 선택합니다.
-
4단계에서 생성한 소스 위치를 선택한 후 다음을 선택합니다.
-
-
대상 위치 구성 페이지에서 다음 작업을 수행하세요.
-
기존 위치 선택을 선택합니다.
-
5단계에서 생성한 대상 위치를 선택한 후 다음을 선택합니다.
-
-
설정 구성 페이지에서 다음을 수행합니다.
-
데이터 전송 구성에서 추가 설정을 펼쳐서 개체 태그 복사 확인란의 선택을 취소합니다.
중요
Google Cloud Storage XML API는 객체 태그 읽기 또는 쓰기를 지원하지 않으므로 객체 태그 복사 시 DataSync 작업이 실패할 수 있습니다.
-
원하는 다른 작업 설정을 구성한 후 다음을 선택합니다.
-
-
검토 페이지에서 설정을 검토한 다음 작업 생성을 선택합니다.
-
작업의 세부 정보 페이지에서 시작을 선택하고 다음 중 하나를 선택하세요:
-
수정하지 않고 작업을 실행하려면 기본값으로 시작을 선택합니다.
-
작업을 실행하기 전에 수정하려면 재정의 옵션으로 시작을 선택합니다.
-
작업이 완료되면 Google Cloud Storage 버킷의 객체가 S3 버킷에 있음을 확인할 수 있습니다.
