기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
에서 동종 데이터 마이그레이션을 사용하여 PostgreSQL 데이터베이스에서 데이터 마이그레이션 AWS DMS
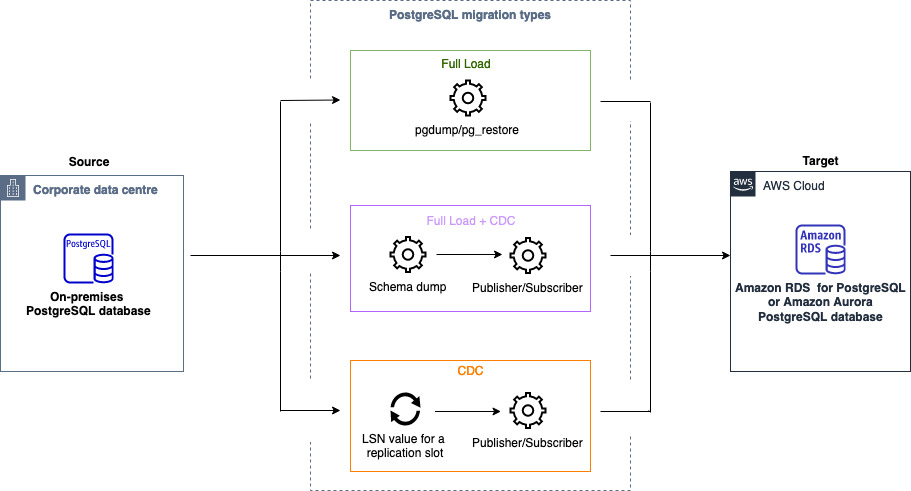
동종 데이터베이스 마이그레이션를 사용하여 자체 관리형 PostgreSQL 데이터베이스를 RDS for PostgreSQL 또는 RDS for Aurora PostgreSQL로 마이그레이션할 수 있습니다. AWS DMS 는 데이터 마이그레이션을 위한 서버리스 환경을 생성합니다. 다양한 유형의 데이터 마이그레이션에서 AWS DMS 는 여러 가지 기본 PostgreSQL 데이터베이스 도구를 사용합니다.
전체 로드 유형의 동종 데이터 마이그레이션의 경우 pg_dump를 AWS DMS 사용하여 소스 데이터베이스에서 데이터를 읽고 서버리스 환경에 연결된 디스크에 저장합니다. 가 모든 소스 데이터를 AWS DMS 읽은 후 대상 데이터베이스의 pg_restore를 사용하여 데이터를 복원합니다.
전체 로드 및 변경 데이터 캡처(CDC) 유형의 동종 데이터 마이그레이션의 경우는 pg_dump를 AWS DMS 사용하여 소스 데이터베이스의 테이블 데이터 없이 스키마 객체를 읽고 서버리스 환경에 연결된 디스크에 저장합니다. 그런 다음 대상 데이터베이스에서 pg_restore를 사용하여 스키마 객체를 복원합니다. 가 pg_restore 프로세스를 AWS DMS 완료하면 원본 데이터베이스에서 대상 데이터베이스로 직접 초기 테이블 데이터를 복사하는 Initial Data Synchronization 옵션과 함께 논리적 복제를 위해 게시자 및 구독자 모델로 자동 전환된 다음 지속적인 복제를 시작합니다. 이 모델에서는 한 명 이상의 구독자가 게시자 노드에 있는 하나 이상의 발행물을 구독합니다.
변경 데이터 캡처(CDC) 유형의 동종 데이터 마이그레이션의 경우 복제를 시작하려면 네이티브 시작점이 AWS DMS 필요합니다. 기본 시작점을 제공하면가 해당 지점의 변경 사항을 AWS DMS 캡처합니다. 또는 데이터 마이그레이션 설정에서 즉시를 선택하여 실제 데이터 마이그레이션이 시작될 때 복제 시작점을 자동으로 캡처할 수도 있습니다.
참고
CDC 전용 마이그레이션이 제대로 작동하려면 모든 소스 데이터베이스 스키마와 객체가 대상 데이터베이스에 이미 있어야 합니다. 그러나 대상에는 원본에 없는 객체가 있을 수 있습니다.
다음 코드 예제를 사용하여 PostgreSQL 데이터베이스의 기본 시작점을 가져올 수 있습니다.
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
이 쿼리는 PostgreSQL 데이터베이스의 pg_replication_slots 뷰를 사용하여 로그 시퀀스 번호(LSN) 값을 캡처합니다.
가 PostgreSQL 동종 데이터 마이그레이션의 상태를 중지됨, 실패 또는 삭제됨으로 AWS DMS 설정한 후에는 게시자와 복제가 제거되지 않습니다. 마이그레이션을 재개하지 않으려면 다음 명령을 사용하여 복제 슬롯과 게시자를 삭제하세요.
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
다음 다이어그램은에서 동종 데이터 마이그레이션 AWS DMS 을 사용하여 PostgreSQL 데이터베이스를 RDS for PostgreSQL 또는 Aurora PostgreSQL로 마이그레이션하는 프로세스를 보여줍니다.
PostgreSQL 데이터베이스를 동종 데이터 마이그레이션의 소스로 사용하는 모범 사례
FLCDC 태스크에 대한 구독자 측의 초기 데이터 동기화 속도를 높이려면
max_logical_replication_workers및max_sync_workers_per_subscription을 조정해야 합니다. 이러한 값을 늘리면 테이블 동기화 속도가 향상됩니다.max_logical_replication_workers - 논리적 복제 작업자의 최대 수를 지정합니다. 여기에는 구독자 측의 적용 작업자와 테이블 동기화 작업자가 모두 포함됩니다.
max_sync_workers_per_subscription –
max_sync_workers_per_subscription을 늘리면 테이블당 작업자 수가 아니라 병렬로 동기화된 테이블 수에만 영향을 줍니다.
참고
max_logical_replication_workers는max_worker_processes를 초과해서는 안 되며,max_sync_workers_per_subscription은max_logical_replication_workers보다 작거나 같아야 합니다.대규모 테이블을 마이그레이션하려면 선택 규칙을 사용하여 테이블을 별도의 태스크로 나누는 것이 좋습니다. 예를 들어 대규모 테이블을 별도의 개별 태스크로 나누고 작은 테이블을 다른 단일 태스크로 나눌 수 있습니다.
구독자 측의 디스크 및 CPU 사용량을 모니터링하여 최적의 성능을 유지합니다.
