이 페이지 개선에 도움 주기
이 사용자 가이드에 기여하려면 모든 페이지의 오른쪽 창에 있는 GitHub에서 이 페이지 편집 링크를 선택합니다.
Kubernetes 개념
Amazon Elastic Kubernetes Service(Amazon EKS)는 오픈 소스 Kubernetes
이 페이지에서는 Kubernetes 개념을 Kubernetes를 사용해야 하는 이유, 클러스터, 워크로드의 세 섹션으로 나누어 설명합니다. 첫 번째 섹션에서는 Kubernetes 서비스, 특히 Amazon EKS와 같은 관리형 서비스를 실행하는 것의 가치에 대해 설명합니다. 워크로드 섹션에서는 Kubernetes 애플리케이션의 구축, 저장, 실행 및 관리 방법을 다룹니다. 클러스터 섹션에서는 Kubernetes 클러스터를 구성하는 다양한 구성 요소와 Kubernetes 클러스터를 생성하고 유지 관리하는 사용자의 책임에 대해 설명합니다.
내용을 살펴보면서 여기에서 다루는 주제에 대해 더 자세히 알아보고 싶을 경우 링크를 통해 Amazon EKS 및 쿠버네티스 문서에 있는 Kubernetes 개념에 대한 추가 설명으로 이동할 수 있습니다. Amazon EKS가 Kubernetes 컨트롤 플레인 및 컴퓨팅 기능을 구현하는 방법에 대한 자세한 내용은 Amazon EKS 아키텍처 섹션을 참조하세요.
Kubernetes를 사용해야 하는 이유
Kubernetes는 미션 크리티컬한 프로덕션 품질의 컨테이너화된 애플리케이션을 실행할 때 가용성과 확장성을 개선하도록 설계되었습니다. Kubernetes는 이러한 목표를 달성하기 위해 단일 머신에서 Kubernetes를 실행하는 것이 아니라(물론 가능하지만), 수요에 따라 확장되거나 축소될 수 있는 컴퓨터 세트에서 애플리케이션을 실행합니다. Kubernetes에는 다음과 같은 작업을 더 쉽게 수행하기 위한 기능이 포함되어 있습니다.
-
여러 시스템에 애플리케이션 배포(포드에 배포된 컨테이너 사용)
-
컨테이너 상태 모니터링 및 장애가 발생한 컨테이너 다시 시작
-
부하에 따라 컨테이너 확장 및 축소
-
새 버전으로 컨테이너 업데이트
-
컨테이너 간 리소스 할당
-
시스템 간 트래픽 균형 조정
Kubernetes가 이러한 유형의 복잡한 태스크를 자동화하므로 애플리케이션 개발자는 인프라에 대한 걱정 없이 애플리케이션 워크로드를 구축하고 개선하는 데 집중할 수 있습니다. 개발자는 일반적으로 원하는 애플리케이션 상태를 설명하는 구성 파일을 YAML 파일 형식으로 생성합니다. 여기에는 실행할 컨테이너, 리소스 제한, 포드 복제본 수, CPU/메모리 할당, 선호도 규칙 등이 포함될 수 있습니다.
Kubernetes의 속성
Kubernetes에는 목표를 달성하기 위한 다음과 같은 특징이 있습니다.
-
컨테이너화 - Kubernetes는 컨테이너 오케스트레이션 도구입니다. Kubernetes를 사용하려면 먼저 애플리케이션을 컨테이너화해야 합니다. 애플리케이션 유형에 따라, 이러한 컨테이너화는 마이크로서비스 세트, 배치 작업 또는 다른 형태가 될 수 있습니다. 이제 애플리케이션에서 Kubernetes 워크플로를 활용할 수 있으며, 이 워크플로에는 컨테이너를 컨테이너 레지스트리의 이미지
로 저장하고, Kubernetes 클러스터 에 배포하고, 사용 가능한 노드 에서 실행할 수 있는 거대한 도구 에코시스템이 포함됩니다. Kubernetes 클러스터에 컨테이너를 배포하기 전에 로컬 컴퓨터에서 Docker 또는 다른 컨테이너 런타임 을 사용하여 개별 컨테이너를 빌드하고 테스트할 수 있습니다. -
규모 조정 가능 - 애플리케이션에 대한 수요가 해당 애플리케이션의 실행 중인 인스턴스 용량을 초과하는 경우 Kubernetes를 스케일 업할 수 있습니다. 필요에 따라 Kubernetes는 애플리케이션에 더 많은 CPU 또는 메모리가 필요한지 여부를 확인하고 사용 가능한 용량을 자동으로 확장하거나 기존 용량을 더 많이 사용하여 이에 대응할 수 있습니다. 애플리케이션의 더 많은 인스턴스를 실행하기에 충분한 컴퓨팅 용량을 사용할 수 있는 경우, 포드 수준에서 확장을 수행할 수 있고(수평적 포드 자동 확장
), 늘어난 용량을 처리하기 위해 더 많은 노드를 가져와야 하는 경우, 노드 수준에서 확장을 수행할 수 있습니다(Cluster Autoscaler 또는 Karpenter ). 용량이 더 이상 필요하지 않게 되면 이러한 서비스는 필요하지 않은 포드를 삭제하고 불필요한 노드를 종료할 수 있습니다. -
사용 가능 - 애플리케이션 또는 노드가 비정상이거나 사용할 수 없게 되면 Kubernetes는 실행 중인 워크로드를 사용 가능한 다른 노드로 이동할 수 있습니다. 워크로드의 실행 중인 인스턴스 또는 워크로드를 실행 중인 노드를 삭제하기만 하면 문제를 강제로 해결할 수 있습니다. 여기서 중요한 것은 워크로드를 현재 위치에서 더 이상 실행할 수 없는 경우 다른 위치로 가져올 수 있다는 것입니다.
-
선언적 - Kubernetes는 활성 조정을 사용하여 클러스터에 대해 선언한 상태가 실제 상태와 일치하는지 지속적으로 확인합니다. 예를 들어, 일반적으로 YAML 형식의 구성 파일을 통해 클러스터에 Kubernetes 객체
를 적용하면 클러스터에서 실행할 워크로드를 시작하도록 요청할 수 있습니다. 나중에 구성을 변경하여 최신 버전의 컨테이너를 사용하거나 추가 메모리를 할당하는 등의 작업을 수행할 수 있습니다. Kubernetes는 원하는 상태를 설정하기 위해 수행해야 하는 작업을 수행합니다. 이러한 작업에는 노드 가동 또는 중단, 워크로드 중지 및 재시작, 업데이트된 컨테이너 가져오기 등이 포함될 수 있습니다. -
구성 가능 — 애플리케이션은 일반적으로 여러 구성 요소로 구성되므로 이러한 구성 요소 세트(대개 여러 컨테이너로 표시됨)를 함께 관리할 수 있어야 합니다. Docker Compose는 Docker를 사용하여 직접 이 작업을 수행하는 방법을 제공하지만 Kubernetes Kompose
명령을 사용하면 Kubernetes에서 이 작업을 수행할 수 있습니다. 이 작업을 수행하는 방법에 대한 예는 Docker 작성 파일을 Kubernetes 리소스로 번역하기를 참조하세요. -
확장 가능 - 독점 소프트웨어와 달리 오픈 소스 Kubernetes 프로젝트는 필요에 따라 원하는 방식으로 Kubernetes를 확장할 수 있도록 설계되었습니다. API 및 구성 파일은 직접 수정할 수 있습니다. 타사에서 자체 컨트롤러
를 작성하여 인프라 및 최종 사용자 Kubernetes 기능을 모두 확장하는 것을 권장합니다. 웹후크 를 사용하면 클러스터 규칙을 설정하여 정책을 적용하고 변화하는 조건에 맞게 조정할 수 있습니다. Kubernetes 클러스터를 확장하는 방법에 대한 자세한 내용은 Kubernetes 확장 을 참조하세요. -
이식 가능 - Kubernetes를 사용하면 모든 애플리케이션 요구 사항을 동일한 방식으로 관리할 수 있기 때문에 많은 조직에서 이를 기반으로 운영을 표준화하고 있습니다. 개발자는 동일한 파이프라인을 사용하여 컨테이너화된 애플리케이션을 빌드하고 저장할 수 있습니다. 그런 다음 이러한 애플리케이션을 온프레미스, 클라우드, 레스토랑의 POS 터미널 또는 회사 원격 사이트에 분산된 IoT 디바이스에서 실행되는 Kubernetes 클러스터에 배포할 수 있습니다. 오픈 소스라는 특성 덕분에 사용자가 이러한 특수 Kubernetes 배포판과 이를 관리하는 데 필요한 도구를 함께 개발할 수 있습니다.
Kubernetes 관리
Kubernetes 소스 코드는 무료로 제공되므로 자체 장비만 있으면 직접 Kubernetes를 설치하고 관리할 수 있습니다. 그러나 Kubernetes를 자체 관리하려면 심층적인 운영 전문 지식이 필요하며 시간과 노력을 들여 유지 관리해야 합니다. 이러한 이유 때문에 프로덕션 워크로드를 배포하는 대부분의 사용자는 자체에서 테스트한 Kubernetes 배포판과 Kubernetes 전문가 지원을 제공하는 클라우드 제공업체(예: Amazon EKS)나 온프레미스 제공업체(예: Amazon EKS Anywhere)를 선택합니다. 이렇게 하면 클러스터를 유지 관리하는 데 필요한 다음과 같은 힘든 작업을 대부분 제거할 수 있습니다.
-
하드웨어 - 요구 사항에 따라 Kubernetes를 실행할 수 있는 하드웨어가 없는 경우 AWS Amazon EKS와 같은 클라우드 제공업체를 통해 초기 비용을 절약할 수 있습니다. Amazon EKS를 사용하면 컴퓨팅 인스턴스(Amazon Elastic Compute Cloud), 자체 프라이빗 환경(Amazon VPC), 중앙 집중식 ID 및 권한 관리(IAM), 스토리지(Amazon EBS) 등을 비롯한 AWS에서 제공하는 최상의 클라우드 리소스를 사용할 수 있습니다. AWS가 컴퓨터, 네트워크, 데이터 센터 및 Kubernetes 실행에 필요한 기타 모든 물리적 구성 요소를 관리합니다. 마찬가지로, 수요가 가장 많은 기간 동안의 최대 용량을 처리하도록 데이터 센터를 계획할 필요도 없습니다. Amazon EKS Anywhere 또는 기타 온프레미스 Kubernetes 클러스터의 경우 Kubernetes 배포에 사용된 인프라를 관리할 책임은 사용자에게 있지만 여전히 AWS를 사용하여 Kubernetes를 최신 상태를 유지할 수 있습니다.
-
컨트롤 플레인 관리 - Amazon EKS가 컨테이너 예약, 애플리케이션 가용성 관리 및 기타 주요 태스크를 담당하는 AWS 호스팅 Kubernetes 컨트롤 플레인의 보안 및 가용성을 관리하므로 사용자는 애플리케이션 워크로드에 집중할 수 있습니다. 사용자의 클러스터가 중단되는 경우 AWS에 클러스터를 실행 상태로 복원할 수 있는 수단이 있어야 합니다. Amazon EKS Anywhere의 경우 컨트롤 플레인을 직접 관리할 수 있습니다.
-
테스트된 업그레이드 - 클러스터를 업그레이드할 때 Amazon EKS 또는 Amazon EKS Anywhere를 사용하여 Kubernetes 배포판의 테스트된 버전을 제공할 수 있습니다.
-
추가 기능 - Kubernetes를 확장하고 Kubernetes와 함께 작동하도록 구축된 수백 가지의 프로젝트가 있으며, 이를 클러스터의 인프라에 추가하거나 워크로드 실행을 지원하는 데 사용할 수 있습니다. 이러한 추가 기능을 직접 빌드 및 관리하는 대신 AWS는 클러스터와 함께 사용할 수 있는 Amazon EKS 추가 기능을 제공합니다. Amazon EKS Anywhere는 여러 인기 있는 오픈 소스 프로젝트의 빌드가 포함된 선별 패키지
를 제공합니다. 따라서 소프트웨어를 직접 빌드하거나 주요 보안 패치, 버그 수정 또는 업그레이드를 관리할 필요가 없습니다. 마찬가지로 기본 구성이 요구 사항을 충족하는 경우 일반적으로 이러한 추가 기능을 거의 구성할 필요가 없습니다. 추가 기능으로 클러스터를 확장하는 방법에 대한 자세한 내용은 확장 클러스터을 참조하세요.
Kubernetes 적용 사례
다음 다이어그램에서는 Kubernetes 관리자 또는 애플리케이션 개발자가 Kubernetes 클러스터를 생성하고 사용하기 위해 수행하는 주요 활동을 보여줍니다. 이 프로세스에서는 AWS 클라우드를 기반 클라우드 제공업체의 예로 사용하여 Kubernetes 구성 요소가 서로 상호 작용하는 방식을 보여줍니다.
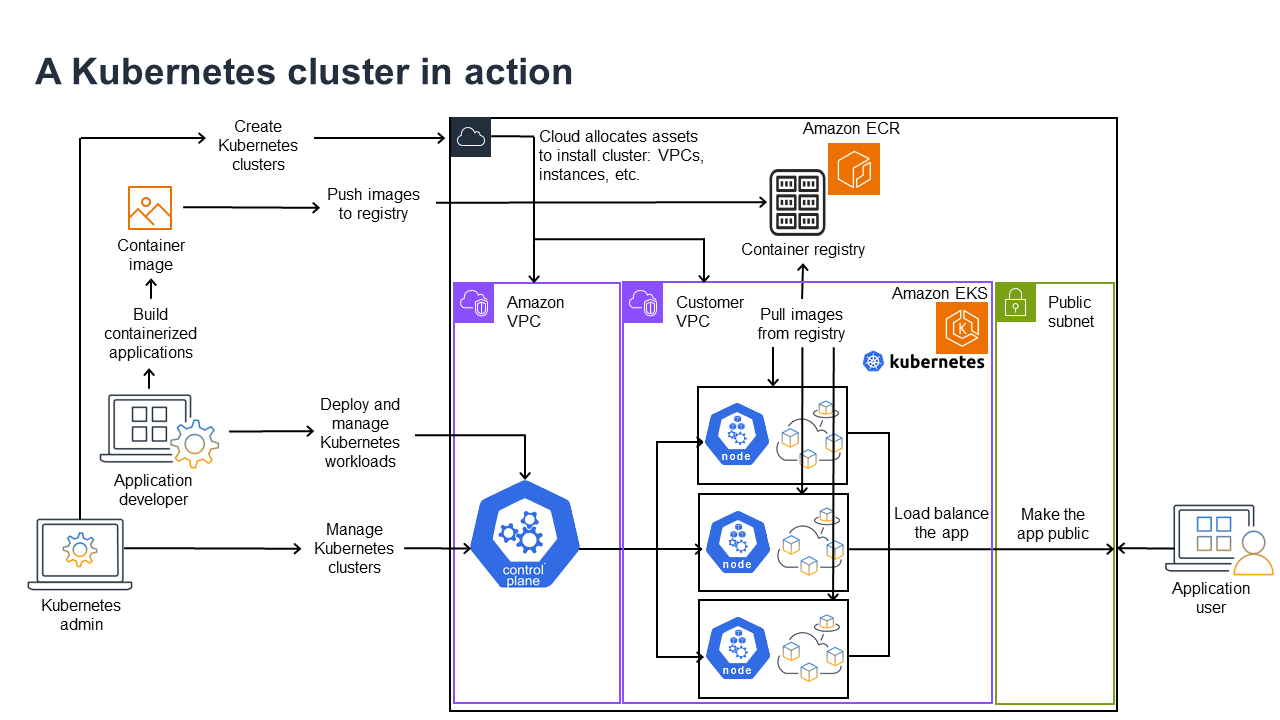
Kubernetes 관리자는 Kubernetes 클러스터가 구축될 제공자의 유형에 맞는 도구를 사용하여 클러스터를 생성합니다. 이 예에서는 Amazon EKS라는 관리형 Kubernetes 서비스를 제공하는 AWS 클라우드를 제공업체로 사용합니다. 관리형 서비스는 클러스터를 위한 2개의 새 가상 프라이빗 클라우드(Amazon VPC) 생성, 네트워킹 설정, 클라우드 자산 관리를 위한 새 VPC에 직접 Kubernetes 권한 매핑을 포함하여 클러스터를 생성하는 데 필요한 리소스를 자동으로 할당합니다. 또한 관리형 서비스에서는 컨트롤 플레인 서비스가 워크로드 실행을 위한 Kubernetes 노드로 0개 이상의 Amazon EC2 인스턴스를 실행 및 할당하는 위치를 지원함을 확인할 수 있습니다. AWS는 컨트롤 플레인에 대해 하나의 자체 Amazon VPC를 관리하며, 다른 Amazon VPC에는 워크로드를 실행하는 고객 노드가 포함되어 있습니다.
앞으로 Kubernetes 관리자의 많은 태스크는 kubectl과 같은 Kubernetes 도구를 사용하여 수행됩니다. 이 도구는 클러스터의 컨트롤 플레인에 직접 서비스를 요청합니다. 클러스터를 쿼리하고 변경하는 방식은 다른 Kubernetes 클러스터에서 수행하는 방식과 매우 비슷합니다.
이 클러스터에 워크로드를 배포하려는 애플리케이션 개발자는 여러 작업을 수행할 수 있습니다. 개발자는 애플리케이션을 하나 이상의 컨테이너 이미지로 빌드한 다음 Kubernetes 클러스터에서 액세스할 수 있는 컨테이너 레지스트리로 해당 이미지를 푸시해야 합니다. AWS는 이 용도로 Amazon Elastic Container Registry(Amazon ECR)를 제공합니다.
애플리케이션을 실행하기 위해 개발자는 레지스트리에서 가져올 컨테이너와 해당 컨테이너를 포드에 래핑하는 방법을 포함하여 클러스터에 애플리케이션 실행 방법을 알려주는 YAML 형식의 구성 파일을 생성할 수 있습니다. 컨트롤 플레인(스케줄러)은 컨테이너를 하나 이상의 노드에 예약하고 각 노드의 컨테이너 런타임은 실제로 필요한 컨테이너를 가져와 실행합니다. 또한 개발자는 Application Load Balancer를 설정하여 각 노드에서 실행 중인 사용 가능한 컨테이너에 대한 트래픽의 균형을 조정하고 공용 네트워크를 통해 외부에서 사용할 수 있도록 애플리케이션을 노출할 수 있습니다. 이 모든 작업이 완료되면 애플리케이션을 사용하려는 사용자가 애플리케이션 엔드포인트에 연결하여 액세스할 수 있습니다.
다음 섹션에서는 Kubernetes 클러스터 및 워크로드의 관점에서 이러한 각 기능에 대해 자세히 살펴봅니다.
클러스터
작업이 Kubernetes 클러스터를 시작하고 관리하는 것이라면 Kubernetes 클러스터가 생성, 강화, 관리 및 삭제되는 방법을 알아야 합니다. 또한 클러스터를 구성하는 구성 요소가 무엇인지, 이러한 구성 요소를 유지 관리하기 위해 어떤 작업이 필요한지도 알아야 합니다.
클러스터를 관리하는 도구는 Kubernetes 서비스와 기반 하드웨어 제공업체 간의 중복을 처리합니다. 이러한 이유 때문에 Kubernetes 제공업체(예: Amazon EKS 또는 Amazon EKS Anywhere)는 제공업체 전용 도구를 사용하여 이러한 태스크를 자동화하는 경향이 있습니다. 예를 들어, Amazon EKS 클러스터를 시작하려면 eksctl create cluster를 사용할 수 있고 Amazon EKS Anywhere에서는 eksctl anywhere create cluster를 사용할 수 있습니다. 이러한 명령은 Kubernetes 클러스터를 생성하지만 제공업체별로 다르며 Kubernetes 프로젝트 자체에 포함되지는 않습니다.
클러스터 생성 및 관리 도구
Kubernetes 프로젝트는 Kubernetes 클러스터를 수동으로 생성할 수 있는 도구를 제공합니다. 따라서 단일 시스템에 Kubernetes를 설치하거나 시스템에서 컨트롤 플레인을 실행하고 노드를 수동으로 추가하려는 경우 Kubernetes Install Tools
AWS 클라우드에서는 eksctl
-
관리형 컨트롤 플레인 — AWS는 자동으로 컨트롤 플레인을 관리하고 AWS 가용 영역 전체에서 사용할 수 있도록 만들기 때문에 Amazon EKS 클러스터의 가용성과 확장성이 보장됩니다.
-
노드 관리 - 노드를 수동으로 추가하는 대신 Amazon EKS에서 관리형 노드 그룹(관리형 노드 그룹을 사용한 노드 수명 주기 간소화 참조) 또는 Karpenter
를 사용하여 필요에 따라 Amazon EKS에서 노드를 자동으로 생성할 수 있습니다. 관리형 노드 그룹은 Kubernetes 클러스터 오토 스케일링 과 통합됩니다. 노드 관리 도구를 사용하면 워크로드를 배포하고 노드를 선택하는 방법을 설정하는 일정 예약 기능을 사용하여 스팟 인스턴스, 노드 통합, 가용성 등과 같은 작업에서 비용 절감 효과를 누릴 수 있습니다. -
클러스터 네트워킹 - CloudFormation 템플릿을 사용하여
eksctl은 Kubernetes 클러스터의 컨트롤 플레인과 데이터 영역(노드) 구성 요소 간의 네트워킹을 설정합니다. 또한 내부 및 외부 통신을 수행할 수 있는 엔드포인트를 설정합니다. 자세한 내용은 Amazon EKS 작업자 노드에 대한 클러스터 네트워킹 설명을 참조하세요. Amazon EKS에서 포드 간 통신은 Amazon EKS Pod Identity를 사용하여 수행됩니다(EKS Pod Identity가 포드에 AWS 서비스에 대한 액세스 권한을 부여하는 방법 알아보기 참조). 이 기능을 사용하는 경우 포드가 자격 증명 및 권한을 관리하는 AWS 클라우드 메서드를 활용할 수 있습니다. -
추가 기능 - Amazon EKS를 사용하면 Kubernetes 클러스터를 지원하는 데 일반적으로 사용되는 소프트웨어 구성 요소를 빌드하고 추가할 필요가 없습니다. 예를 들어 AWS Management Console에서 Amazon EKS 클러스터를 생성하는 경우 Amazon EKS kube-proxy(Amazon EKS 클러스터에서 kube-proxy 관리), Kubernetes용 Amazon VPC CNI 플러그인(Amazon VPC CNI를 통해 포드에 IP 할당), CoreDNS(Amazon EKS 클러스터에서 DNS에 대한 CoreDNS 관리) 추가 기능이 자동으로 추가됩니다. 사용 가능한 추가 기능의 목록을 포함하여 이러한 추가 기능에 대한 자세한 내용은 Amazon EKS 추가 기능을 참조하세요.
사용자가 자체 온프레미스 컴퓨터 및 네트워크에서 클러스터를 실행할 수 있도록 Amazon은 Amazon EKS Anywhere
Amazon EKS Anywhere는 Amazon EKS에서 사용하는 것과 동일한 Amazon EKS Distroetcd 참조).
클러스터 구성 요소
Kubernetes 클러스터 구성 요소는 컨트롤 플레인과 워커 노드라는 두 가지 주요 영역으로 구분됩니다. 컨트롤 플레인 구성 요소
컨트롤 플레인
컨트롤 플레인은 클러스터를 관리하는 서비스 세트로 구성됩니다. 이러한 서비스는 모두 단일 컴퓨터에서 실행되거나 여러 컴퓨터에 분산되어 있을 수 있습니다. 내부적으로는 이를 컨트롤 플레인 인스턴스(CPI)라고 합니다. CPI 실행 방법은 클러스터 규모와 고가용성 요구 사항에 따라 다릅니다. 클러스터의 수요가 증가하면 컨트롤 플레인 서비스 규모가 조정되어 해당 서비스의 인스턴스를 더 많이 제공할 수 있으며, 이때 요청은 인스턴스 간에서 로드 밸런싱됩니다.
Kubernetes 컨트롤 플레인의 구성 요소가 수행하는 태스크에는 다음이 포함됩니다.
-
클러스터 구성 요소(API 서버)와의 통신 - API 서버(kube-apiserver
)는 Kubernetes API를 노출하므로 클러스터 내부와 외부 모두에서 클러스터에 요청을 보낼 수 있습니다. 즉, 클러스터의 객체(포드, 서비스, 노드 등)를 추가하거나 변경하는 요청은 포드를 실행하는 kubectl의 요청과 같은 외부 명령에서 발생할 수 있습니다. 마찬가지로, API 서버에서 클러스터 내 구성 요소로 요청을 보낼 수 있습니다(예: 포드 상태에 대한kubelet서비스의 쿼리). -
클러스터에 대한 데이터 저장(
etcd키 값 저장소) -etcd서비스는 클러스터의 현재 상태를 추적하는 중요한 역할을 합니다.etcd서비스에 액세스할 수 없게 되면 얼마 동안 워크로드가 계속 실행되더라도 클러스터의 상태를 업데이트하거나 쿼리할 수 없게 됩니다. 이러한 이유로 중요 클러스터는 일반적으로 로드 밸런싱된 여러 개의etcd서비스 인스턴스를 동시에 실행하고 데이터 손실 또는 손상에 대비하여etcd키 값 저장소를 주기적으로 백업합니다. Amazon EKS에서는 기본적으로 이 모든 작업이 자동으로 처리된다는 점에 유의하세요. Amazon EKS Anywhere는 etcd 백업 및 복원에 대한 지침을 제공합니다. etcd에서 데이터를 관리하는 방법을 알아보려면 etcd Data Model을 참조하세요. -
노드에 포드 예약(스케줄러) - Kubernetes에서 포드를 시작하거나 중지하기 위한 요청은 Kubernetes 스케줄러
(kube-scheduler )로 전달됩니다. 클러스터에는 포드를 실행할 수 있는 노드가 여러 개 있을 수 있으므로 포드를 실행할 노드(복제본의 경우, 여러 노드)를 선택하는 것은 스케줄러입니다. 요청된 포드를 기존 노드에서 실행할 수 있는 가용 용량이 충분하지 않은 경우 다른 프로비저닝이 수행되지 않는 한 요청이 실패합니다. 이러한 프로비저닝에는 새 노드를 자동으로 시작하여 워크로드를 처리할 수 있는 관리형 노드 그룹(관리형 노드 그룹을 사용한 노드 수명 주기 간소화) 또는 Karpenter 와 같은 서비스를 활성화하는 작업이 포함될 수 있습니다. -
구성 요소를 원하는 상태로 유지(컨트롤러 관리자) - Kubernetes 컨트롤러 관리자는 대몬 프로세스(kube-controller-manager
)로 실행되어 클러스터의 상태를 감시하고 클러스터를 변경하여 예상 상태를 재설정합니다. 특히 statefulset-controller,endpoint-controller,cronjob-controller,node-controller등 다양한 Kubernetes 객체를 감시하는 컨트롤러가 여러 개 있습니다. -
클라우드 리소스 관리(Cloud Controller Manager) - Kubernetes와 기본 데이터 센터 리소스에 대한 요청을 수행하는 클라우드 제공업체 간의 상호 작용은 Cloud Controller Manager
(cloud-controller-manager )에서 처리합니다. Cloud Controller Manager에서 관리하는 컨트롤러에는 경로 컨트롤러(클라우드 네트워크 경로 설정에 사용), 서비스 컨트롤러(클라우드 로드 밸런싱 서비스에 사용), 노드 수명 주기 컨트롤러(전체 해당 수명 주기에서 노드를 Kubernetes와 동기화하는 데 사용)가 포함될 수 있습니다.
워커 노드(데이터 플레인)
단일 노드 Kubernetes 클러스터의 경우 워크로드는 컨트롤 플레인과 동일한 시스템에서 실행됩니다. 하지만 좀 더 일반적인 구성은 Kubernetes 워크로드 실행 전용으로 사용되는 별도의 컴퓨터 시스템(노드
Kubernetes 클러스터를 처음 생성할 때 일부 클러스터 생성 도구를 사용하면 기존 컴퓨터 시스템을 식별하거나 제공업체가 새 컴퓨터 시스템을 생성하도록 하여 클러스터에 추가할 특정 수의 노드를 구성할 수 있습니다. 이러한 시스템에 워크로드를 추가하기 전에 각 노드에 서비스를 추가하여 다음 기능을 구현합니다.
-
각 노드 관리(
kubelet) - API 서버는 각 노드에서 실행되는 kubelet서비스와 통신하여 노드가 제대로 등록되었으며 스케줄러가 요청한 포드가 실행되고 있는지 확인합니다. kubelet은 포드 매니페스트를 읽고 로컬 시스템의 포드에 필요한 스토리지 볼륨 또는 기타 기능을 설정할 수 있습니다. 또한 로컬에서 실행 중인 컨테이너의 상태를 확인할 수 있습니다. -
노드에서 컨테이너 실행(컨테이너 런타임) — 각 노드의 컨테이너 런타임
은 노드에 할당된 각 포드에 요청된 컨테이너를 관리합니다. 즉, 적절한 레지스트리에서 컨테이너 이미지를 가져와 컨테이너를 실행하고 중지하며 컨테이너에 대한 쿼리에 응답할 수 있습니다. 기본 컨테이너 런타임은 containerd 입니다. Kubernetes 1.24부터 컨테이너 런타임으로 사용할 수 있는 Docker( dockershim)의 특수 통합이 Kubernetes에서 삭제되었습니다. 로컬 시스템에서 컨테이너를 테스트하고 실행하는 데 여전히 Docker를 사용할 수 있지만 Docker와 Kubernetes를 함께 사용하려면 이제 각 노드에 Docker Engine을 설치하여 Kubernetes와 함께 사용해야 합니다. -
컨테이너 간 네트워킹 관리(
kube-proxy) - 포드 간 통신을 지원하기 위해 Kubernetes는 포드 네트워크를 설정하여 해당 포드와 관련된 IP 주소 및 포트를 추적하는 서비스라는 기능을 사용합니다. kube-proxy 서비스는 모든 노드에서 실행되어 포드 간 통신이 이루어질 수 있도록 합니다.
확장 클러스터
클러스터를 지원하기 위해 Kubernetes에 추가할 수 있는 일부 서비스가 있지만 이러한 서비스는 컨트롤 플레인에서는 실행되지 않습니다. 이러한 서비스는 종종 kube-system 네임스페이스의 노드나 자체 네임스페이스에서 직접 실행됩니다(타사 서비스 공급자에서 자주 실행됨). 일반적인 예로는 클러스터에 DNS 서비스를 제공하는 CoreDNS 서비스를 들 수 있습니다. 클러스터의 kube-system에서 실행 중인 클러스터 서비스를 확인하는 방법에 대한 자세한 내용은 기본 제공 서비스 검색
클러스터에 추가하는 것을 고려할 수 있는 다양한 유형의 추가 기능이 있습니다. 클러스터를 정상 상태로 유지하기 위해 로깅, 감사, 지표 등의 작업을 수행할 수 있는 관찰성 기능(클러스터 성능 모니터링 및 로그 보기 참조)을 추가할 수 있습니다. 이 정보를 사용하여 종종 동일한 관찰성 인터페이스를 통해 발생하는 문제를 해결할 수 있습니다. 이러한 유형의 서비스에 대한 예로 Amazon GuardDuty, CloudWatch(Amazon CloudWatch를 사용한 클러스터 데이터 모니터링 참조), AWS Distro for OpenTelemetry
Amazon EKS 추가 기능의 전체 목록은 Amazon EKS 추가 기능 섹션을 참조하세요.
워크로드
Kubernetes는 워크로드
컨테이너
Kubernetes에서 배포하고 관리하는 애플리케이션 워크로드의 가장 기본적인 요소는 포드
포드는 배포 가능한 가장 작은 단위이기 때문에 보통 단일 컨테이너를 유지합니다. 하지만 컨테이너가 긴밀하게 연계된 경우 한 포드에 여러 컨테이너가 있을 수 있다. 예를 들어, 웹 서버 컨테이너는 로깅, 모니터링 또는 웹 서버 컨테이너와 밀접하게 연결된 기타 서비스를 제공할 수 있는 사이드카
포드 사양(PodSpec
포드는 배포하는 가장 작은 단위인 반면, 컨테이너는 빌드하고 관리하는 가장 작은 단위입니다.
컨테이너 빌드
포드는 실제로 하나 이상의 컨테이너를 포함하는 구조이며, 각 컨테이너 자체는 파일 시스템, 실행 파일, 구성 파일, 라이브러리 및 애플리케이션을 실제로 실행하기 위한 기타 구성 요소를 유지합니다. Docker Inc.라는 회사가 처음으로 컨테이너를 대중화했기 때문에 일부 사람들은 컨테이너를 Docker 컨테이너라고 부릅니다. 그러나 이후 Open Container Initiative
컨테이너를 빌드할 때는 일반적으로 Dockerfile(문자 그대로 이름이 지정됨)로 시작합니다. 해당 Dockerfile 내에서 다음을 식별합니다.
-
기본 이미지 — 기본 컨테이너 이미지는 일반적으로 최소 버전의 운영 체제 파일 시스템(예: Red Hat Enterprise Linux
또는 Ubuntu ) 또는 특정 유형의 애플리케이션을 실행하기 위한 소프트웨어를 제공하도록 개선된 최소 시스템(예: nodejs 또는 python 앱)에서 빌드되는 컨테이너입니다. -
애플리케이션 소프트웨어 — Linux 시스템에 추가하는 것과 거의 같은 방식으로 애플리케이션 소프트웨어를 컨테이너에 추가할 수 있습니다. 예를 들어, Dockerfile에서
npm및yarn을 실행하여 Java 애플리케이션을 설치하거나yum및dnf를 실행하여 RPM 패키지를 설치할 수 있습니다. 즉, Dockerfile에서 RUN 명령을 사용하면 기본 이미지의 파일 시스템에서 사용 가능한 모든 명령을 실행하여 결과 컨테이너 이미지 내에서 소프트웨어를 설치하거나 소프트웨어를 구성할 수 있습니다. -
지침 — Dockerfile 참조
는 구성 시 Dockerfile에 추가할 수 있는 지침을 기술합니다. 여기에는 컨테이너 자체의 내용을 빌드하는 데 사용되고(로컬 시스템의 파일 ADD또는COPY), 컨테이너가 실행될 때 실행할 명령을 식별하고(CMD또는ENTRYPOINT), 컨테이너를 실행되는 시스템에 연결하는 데 사용되는(실행할USER, 마운트할 로컬VOLUME또는EXPOSE할 포트) 지침이 포함됩니다.
docker 명령 및 서비스는 전통적으로 컨테이너를 빌드하는 데 사용되었지만(docker build), 컨테이너 이미지를 빌드하는 데 사용할 수 있는 다른 도구로는 podman
컨테이너 저장
컨테이너 이미지를 빌드한 후에는 워크스테이션의 컨테이너 배포 레지스트리
컨테이너 이미지를 보다 공개적인 방식으로 저장하려면 퍼블릭 컨테이너 레지스트리로 푸시할 수 있습니다. 퍼블릭 컨테이너 레지스트리는 컨테이너 이미지를 저장하고 배포할 수 있는 중앙 위치를 제공합니다. 퍼블릭 컨테이너 레지스트리의 예로는 Amazon Elastic Container Registry
Amazon Elastic Kubernetes Service(Amazon EKS)에서 컨테이너화된 워크로드를 실행할 경우 Amazon Elastic Container Registry에 저장된 Docker 공식 이미지의 사본을 가져오는 것이 좋습니다. Amazon ECR은 2021년부터 이러한 이미지를 저장하고 있습니다. Amazon ECR 퍼블릭 갤러리
실행 중인 컨테이너
컨테이너는 표준 형식으로 빌드되므로 컨테이너 런타임을 실행할 수 있고(예: Docker) 콘텐츠가 로컬 시스템의 아키텍처와 일치하는(예: x86_64 또는 arm) 모든 시스템에서 컨테이너를 실행할 수 있습니다. 컨테이너를 테스트하거나 로컬 데스크톱에서 실행하려면 docker run 또는 podman run 명령을 사용하여 로컬 호스트에서 컨테이너를 시작할 수 있습니다. 하지만 Kubernetes의 경우 각 워커 노드에는 컨테이너 런타임이 배포되어 있으며 Kubernetes가 노드에서 컨테이너를 실행하도록 요청하기만 하면 됩니다.
컨테이너가 노드에서 실행되도록 할당되면 노드는 요청된 버전의 컨테이너 이미지가 노드에 이미 존재하는지 확인합니다. 존재하지 않는 경우 Kubernetes는 컨테이너 런타임에 적절한 컨테이너 레지스트리에서 해당 컨테이너를 가져온 다음 해당 컨테이너를 로컬에서 실행하도록 지시합니다. 컨테이너 이미지는 랩톱, 컨테이너 레지스트리 및 Kubernetes 노드 사이에서 이동하는 소프트웨어 패키지를 나타낸다는 것을 기억하세요. 컨테이너는 해당 이미지의 실행 중인 인스턴스를 나타냅니다.
포드
컨테이너가 준비되면 포드를 사용하는 작업에 포드를 구성하고, 배포하고, 액세스 가능하게 만드는 작업이 포함됩니다.
포드 구성
포드를 정의할 때 포드에 속성 세트를 할당합니다. 이러한 속성에는 최소한 포드 이름과 실행할 컨테이너 이미지가 포함되어야 합니다. 하지만 포드 정의를 사용하여 구성할 수 있는 다른 사항도 많습니다(포드에 들어갈 수 있는 항목에 대한 자세한 내용은 PodSpec
-
스토리지 - 실행 중인 컨테이너를 중지하고 삭제하면 더 많은 영구 스토리지를 설정하지 않는 한 해당 컨테이너의 데이터 스토리지가 사라집니다. Kubernetes는 다양한 스토리지 유형을 지원하며 이를 볼륨
이라는 이름으로 추상화합니다. 스토리지 유형에는 CephFS , NFS , iSCSI 등이 포함됩니다. 로컬 컴퓨터의 로컬 블록 디바이스 를 사용할 수도 있습니다. 클러스터에서 이러한 스토리지 유형 중 하나를 사용할 경우 컨테이너 파일 시스템에서 선택한 탑재 지점에 스토리지 볼륨을 탑재할 수 있습니다. 영구 볼륨 은 포드가 삭제된 후에도 계속 존재하는 볼륨이고, 임시 볼륨 은 포드가 삭제될 때 삭제됩니다. 클러스터 관리자가 클러스터에 대해 서로 다른 스토리지 클래스 를 생성한 경우 사용 후 볼륨을 삭제하거나 회수할지 여부, 추가 공간이 필요할 경우 볼륨을 확장할지 여부, 특정 성능 요구 사항을 충족하는지 여부 등, 사용하는 스토리지의 속성을 선택할 수 있는 옵션이 제공됩니다. -
보안 암호 — 포드 사양의 컨테이너에 보안 암호
를 제공할 때 해당 컨테이너에 파일 시스템, 데이터베이스 또는 기타 보호된 자산에 액세스하는 데 필요한 권한을 제공할 수 있습니다. 키, 암호 및 토큰은 비밀로 저장할 수 있는 항목입니다. 보안 암호를 사용하면 이 정보를 컨테이너 이미지에 저장할 필요가 없어지고 실행 중인 컨테이너에 암호만 제공하면 됩니다. 보안 암호와 비슷한 것은 ConfigMap 입니다. ConfigMap에는 서비스 구성을 위한 키-값 쌍과 같은 덜 중요한 정보가 들어 있는 경향이 있습니다. -
컨테이너 리소스 — 컨테이너를 추가로 구성하기 위한 객체는 리소스 구성의 형태를 취할 수 있습니다. 각 컨테이너에 사용할 수 있는 메모리 및 CPU 양을 요청하고 컨테이너가 사용할 수 있는 리소스의 총량을 제한할 수 있습니다. 예제는 포드 및 컨테이너 리소스 관리
를 참조하세요. -
중단 — 포드는 모르는 사이에 중단되거나(노드가 다운됨) 자발적으로 중단될 수 있습니다(업그레이드가 필요함). 포드 중단 예산
을 구성하면 중단이 발생했을 때 애플리케이션의 가용성을 어느 정도 제어할 수 있습니다. 예제는 애플리케이션에 대한 중단 예산 지정 을 참조하세요. -
네임스페이스 - Kubernetes는 Kubernetes 구성 요소와 워크로드를 서로 분리하는 다양한 방법을 제공합니다. 동일한 네임스페이스
에서 특정 애플리케이션의 모든 포드를 실행하는 것은 해당 포드를 함께 보호하고 관리하는 일반적인 방법입니다. 사용할 네임스페이스를 직접 생성하거나 네임스페이스를 지정하지 않도록 선택할 수 있습니다(이 경우 Kubernetes가 default네임스페이스 사용). Kubernetes 컨트롤 플레인 구성 요소는 일반적으로 kube 시스템네임스페이스에서 실행됩니다.
앞서 설명한 구성은 일반적으로 Kubernetes 클러스터에 적용할 YAML 파일에 함께 수집됩니다. 개인용 Kubernetes 클러스터의 경우 이러한 YAML 파일을 로컬 시스템에 저장하기만 하면 됩니다. 그러나 더 중요한 클러스터와 워크로드의 경우 GitOps
포드 정보를 함께 수집하고 배포하는 데 사용되는 객체는 다음 배포 방법 중 하나로 정의됩니다.
포드 배포
포드를 배포하기 위해 선택하는 방법은 해당 포드로 실행하려는 애플리케이션의 유형에 따라 달라집니다. 다음은 몇 가지 옵션입니다.
-
상태 비저장 애플리케이션 — 상태 비저장 애플리케이션은 클라이언트의 세션 데이터를 저장하지 않으므로 다른 세션에서 이전 세션에서 발생한 일을 다시 참조할 필요가 없습니다. 따라서 포드가 비정상 상태가 된 경우 새 포드로 대체하거나 상태를 저장하지 않고 다른 포드로 이동하는 것이 더 쉬워집니다. 상태 비저장 애플리케이션(예: 웹 서버)을 실행 중인 경우, 배포
를 사용하여 포드 와 ReplicaSet 을 배포할 수 있습니다. ReplicaSet은 동시에 실행하려는 포드의 인스턴스 수를 정의합니다. ReplicaSet을 직접 실행할 수도 있지만 한 번에 실행해야 하는 포드의 복제본 수를 정의하기 위해 배포 내에서 직접 복제본을 실행하는 것이 일반적입니다. -
상태 저장 애플리케이션 — 상태 저장 애플리케이션은 포드의 자격 증명과 포드가 시작되는 순서가 중요한 애플리케이션입니다. 이러한 애플리케이션에는 안정적인 영구 스토리지가 필요하며 일관된 방식으로 배포하고 확장해야 합니다. Kubernetes에 상태 저장 애플리케이션을 배포하려면 StatefulSets
를 사용하면 됩니다. 일반적으로 StatefulSet으로 실행되는 애플리케이션의 예로는 데이터베이스가 있습니다. StatefulSet 내에서 복제본, 포드 및 해당 컨테이너, 마운트할 스토리지 볼륨, 컨테이너에서 데이터가 저장되는 위치를 정의할 수 있습니다. ReplicaSet으로 배포되는 데이터베이스의 예는 Run a Replicated Stateful Application 을 참조하세요. -
노드별 애플리케이션 - Kubernetes 클러스터의 모든 노드에서 애플리케이션을 실행하려는 경우가 있습니다. 예를 들어, 데이터 센터에서 모든 컴퓨터가 모니터링 애플리케이션 또는 특정 원격 액세스 서비스를 실행하도록 요구할 수 있습니다. Kubernetes의 경우 DaemonSet
을 사용하여 선택한 애플리케이션이 클러스터의 모든 노드에서 실행되도록 할 수 있습니다. -
애플리케이션 실행 완료 — 일부 애플리케이션은 특정 작업을 완료하기 위해 실행되어야 합니다. 여기에는 월별 상태 보고서를 실행하거나 오래된 데이터를 정리하는 애플리케이션이 포함될 수 있습니다. Job
객체를 사용하여 애플리케이션을 시작 및 실행한 다음 작업이 완료되면 종료하도록 설정할 수 있습니다. CronJob 객체를 사용하면 Linux crontab 형식으로 정의된 구조를 사용하여 특정 시간, 분, 날짜 또는 요일에 애플리케이션이 실행되도록 설정할 수 있습니다.
네트워크에서 애플리케이션에 액세스할 수 있게 만들기
애플리케이션이 여러 위치로 이동하는 마이크로서비스 세트로 배포되는 경우가 많기 때문에 Kubernetes에는 이러한 마이크로서비스가 서로를 찾을 수 있는 방법이 필요했습니다. 또한 다른 사용자가 Kubernetes 클러스터 외부에서 애플리케이션에 액세스하려면 Kubernetes에는 해당 애플리케이션을 외부 주소 및 포트에 노출할 방법이 필요했습니다. 이러한 네트워킹 관련 기능은 각각 서비스 객체와 수신 객체를 통해 수행됩니다.
-
서비스 - 포드는 서로 다른 노드와 주소로 이동할 수 있기 때문에 첫 번째 포드와 통신해야 하는 다른 포드가 첫 번째 포드의 위치를 알아내기 어려울 수 있습니다. 이 문제를 해결하기 위해 Kubernetes에서는 애플리케이션을 서비스
로 표현할 수 있습니다. 서비스를 사용하면 특정 이름으로 포드 또는 포드 세트를 식별한 다음, 포드에서 해당 애플리케이션의 서비스를 노출하는 포트와 다른 애플리케이션이 해당 서비스에 연결하기 위해 사용할 수 있는 포트를 지정할 수 있다. 클러스터 내의 다른 포드는 단순히 이름을 사용하여 서비스를 요청할 수 있으며 Kubernetes는 해당 요청을 해당 서비스를 실행하는 포드의 인스턴스에 대한 적절한 포트로 전달합니다. -
수신 - 수신
은 Kubernetes 서비스로 표시되는 애플리케이션을 클러스터 외부의 클라이언트도 사용할 수 있게 해주는 역할을 합니다. 수신의 기본 기능에는 로드 밸런서(수신에서 관리), 수신 컨트롤러, 컨트롤러에서 서비스로 요청을 라우팅하는 규칙이 포함됩니다. Kubernetes에서 선택할 수 있는 수신 컨트롤러 는 여러 개가 있습니다.
다음 단계
기본적인 Kubernetes 개념 및 Amazon EKS와의 관계를 이해하면 Amazon EKS 설명서와 쿠버네티스 문서
