기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
세분화된 액세스 제어를 AWS Lake Formation 위해에서 EMR Serverless 사용
개요
Amazon EMR 릴리스 7.2.0 이상에서는 AWS Lake Formation 를 활용하여 S3에서 지원하는 데이터 카탈로그 테이블에 세분화된 액세스 제어를 적용합니다. 이 기능을 사용하면 Amazon EMR Serverless Spark 작업 내에서 read 쿼리에 대한 테이블, 행, 열 및 셀 수준 액세스 제어를 구성할 수 있습니다. Apache Spark 배치 작업 및 대화형 세션에 대한 세분화된 액세스 제어를 구성하려면 EMR Studio를 사용합니다. Lake Formation 및 EMR Serverless와 함께 사용하는 방법에 대해 자세히 알아보려면 다음 섹션을 참조하세요.
Amazon EMR Serverless를와 함께 사용하면 추가 요금이 AWS Lake Formation 발생합니다. 자세한 내용은 Amazon EMR 요금
EMR Serverless의 작동 방식 AWS Lake Formation
EMR Serverless를 Lake Formation과 함께 사용하면 EMR Serverless에서 작업을 실행하는 경우 Lake Formation 권한 제어를 적용하기 위해 각 Spark 작업에 권한 계층을 적용할 수 있습니다. EMR Serverless는 Spark 리소스 프로파일
Lake Formation에서 사전 초기화된 용량을 사용하는 경우 최소 2개의 Spark 드라이버를 사용하는 것이 좋습니다. Lake Formation이 활성화된 각 작업에는 사용자 프로파일과 시스템 프로파일에 대해 하나씩, 두 개의 Spark 드라이버가 사용됩니다. 최상의 성능을 위해 Lake Formation을 사용하지 않는 경우와 비교하여 Lake Formation 지원 작업에 대해 2배의 드라이버 수를 사용합니다.
EMR Serverless에서 Spark 작업을 실행하는 경우 동적 할당이 리소스 관리 및 클러스터 성능에 미치는 영향도 고려합니다. 리소스 프로파일당 최대 실행기 수의 spark.dynamicAllocation.maxExecutors 구성은 사용자 및 시스템 실행기 모두에 적용됩니다. 이 숫자를 허용되는 최대 실행기 수와 같도록 구성하면 사용 가능한 모든 리소스를 사용하는 한 가지 유형의 실행기로 인해 작업 실행이 중단될 수 있으며, 이로 인해 작업 실행 시 다른 실행기가 작동하지 않습니다.
따라서 리소스가 부족하지 않도록 EMR Serverless는 리소스 프로파일당 기본 최대 실행기 수를 spark.dynamicAllocation.maxExecutors 값의 90%로 설정합니다. 0에서 1 사이의 값으로 spark.dynamicAllocation.maxExecutorsRatio를 지정하는 경우 이 구성을 재정의할 수 있습니다. 또한 리소스 할당 및 전체 성능을 최적화하도록 다음 속성을 구성할 수도 있습니다.
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
다음은 Amazon EMR Serverless가 Lake Formation 보안 정책에 따라 보호되는 데이터에 액세스하는 방법에 대한 개략적인 개요입니다.
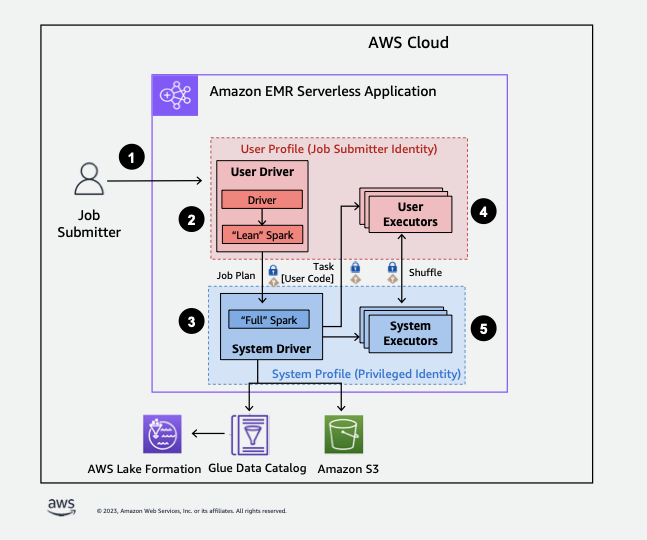
-
사용자가 Spark 작업을 AWS Lake Formation활성화된 EMR Serverless 애플리케이션에 제출합니다.
-
EMR Serverless는 사용자 드라이버로 작업을 전송하고 사용자 프로파일에서 작업을 실행합니다. 사용자 드라이버는 태스크를 시작하고, 실행기를 요청하며, S3 또는 Glue Catalog에 액세스할 수 없는 린 버전의 Spark를 실행합니다. 작업 계획을 빌드합니다.
-
EMR Serverless는 시스템 드라이버라는 두 번째 드라이버를 설정하고 시스템 프로파일(권한 있는 자격 증명 포함)에서 실행합니다. EMR Serverless는 통신을 위해 두 드라이버 사이에서 암호화된 TLS 채널을 설정합니다. 사용자 드라이버는 채널을 사용하여 작업 계획을 시스템 드라이버로 전송합니다. 시스템 드라이버는 사용자가 제출한 코드를 실행하지 않습니다. 전체 Spark를 실행하고 S3 및 데이터 액세스를 위해 Data Catalog와 통신합니다. 실행기를 요청하고 작업 계획을 일련의 실행 단계로 컴파일합니다.
-
그런 다음, EMR Serverless는 사용자 드라이버 또는 시스템 드라이버를 사용하여 실행기에서 단계를 실행합니다. 모든 단계의 사용자 코드는 사용자 프로파일 실행기에서만 실행됩니다.
-
로 보호되는 데이터 카탈로그 테이블에서 데이터를 읽는 단계 AWS Lake Formation 또는 보안 필터를 적용하는 단계는 시스템 실행기에 위임됩니다.
Amazon EMR에서 Lake Formation 활성화
Lake Formation을 활성화하려면 EMR Serverless 애플리케이션을 생성할 때 런타임 구성 파라미터의 spark-defaults 분류 아래에서 spark.emr-serverless.lakeformation.enabled를 true로 설정합니다.
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
EMR Studio에서 새 애플리케이션을 생성하는 경우 Lake Formation을 활성화할 수도 있습니다. 추가 구성 아래에서 사용할 수 있는 세분화된 액세스 제어를 위해 Lake Formation 사용을 선택합니다.
Lake Formation을 EMR Serverless와 함께 사용하면 워커 간 암호화가 기본적으로 활성화되므로 워커 간 암호화를 다시 명시적으로 활성화하지 않아도 됩니다.
Spark 작업에 대해 Lake Formation 활성화
개별 Spark 작업에 대해 Lake Formation을 활성화하려면 spark-submit을 사용할 때 spark.emr-serverless.lakeformation.enabled를 true로 설정합니다.
--conf spark.emr-serverless.lakeformation.enabled=true
작업 런타임 역할 IAM 권한
Lake Formation 권한은 AWS Glue 데이터 카탈로그 리소스, Amazon S3 위치 및 해당 위치의 기본 데이터에 대한 액세스를 제어합니다. IAM 권한은 Lake Formation 및 AWS Glue API와 리소스에 대한 액세스를 제어합니다. Data Catalog의 테이블에 액세스할 수 있는 Lake Formation 권한이 있더라도(SELECT) glue:Get* API 작업에 IAM 권한이 없으면 작업이 실패합니다.
다음은 S3의 스크립트에 액세스할 수 있는 IAM 권한을 제공하는 방법, S3에 로그 업로드, AWS Glue API 권한 및 Lake Formation에 액세스할 수 있는 권한에 대한 정책 예제입니다.
작업 런타임 역할에 대한 Lake Formation 권한 설정
먼저 Lake Formation에 Hive 테이블의 위치를 등록합니다. 그런 다음, 원하는 테이블에서 작업 런타임 역할에 대한 권한을 생성합니다. Lake Formation에 대한 자세한 내용은 란 무엇입니까 AWS Lake Formation?를 참조하세요. AWS Lake Formation 개발자 안내서의 .
Lake Formation 권한을 설정한 후 Amazon EMR Serverless에서 Spark 작업을 제출할 수 있습니다. Spark 작업에 대한 자세한 내용은 Spark 예제를 참조하세요.
작업 실행 제출
Lake Formation 권한 부여 설정을 완료한 후 EMR Serverless에서 Spark 작업을 제출할 수 있습니다. 다음 섹션에서는 작업 실행 속성을 구성 및 제출하는 방법의 예를 보여줍니다.
권한 요구 사항
에 등록되지 않은 테이블 AWS Lake Formation
에 등록되지 않은 테이블 AWS Lake Formation의 경우 작업 런타임 역할은 AWS Glue 데이터 카탈로그와 Amazon S3의 기본 테이블 데이터에 모두 액세스합니다. 이를 위해서는 작업 런타임 역할에 AWS Glue 및 Amazon S3 작업 모두에 대한 적절한 IAM 권한이 있어야 합니다.
에 등록된 테이블 AWS Lake Formation
에 등록된 테이블 AWS Lake Formation의 경우 작업 런타임 역할은 AWS Glue 데이터 카탈로그 메타데이터에 액세스하고 Lake Formation에서 제공하는 임시 자격 증명은 Amazon S3의 기본 테이블 데이터에 액세스합니다. 작업을 실행하는 데 필요한 Lake Formation 권한은 Spark 작업이 시작하는 AWS Glue 데이터 카탈로그 및 Amazon S3 API 호출에 따라 달라지며 다음과 같이 요약할 수 있습니다.
-
DESCRIBE 권한을 사용하면 런타임 역할이 데이터 카탈로그에서 테이블 또는 데이터베이스 메타데이터를 읽을 수 있습니다.
-
ALTER 권한을 사용하면 런타임 역할이 데이터 카탈로그에서 테이블 또는 데이터베이스 메타데이터를 수정할 수 있습니다.
-
DROP 권한을 사용하면 런타임 역할이 데이터 카탈로그에서 테이블 또는 데이터베이스 메타데이터를 삭제할 수 있습니다.
-
SELECT 권한은 런타임 역할이 Amazon S3에서 테이블 데이터를 읽을 수 있도록 허용합니다.
-
INSERT 권한은 런타임 역할이 Amazon S3에 테이블 데이터를 쓸 수 있도록 허용합니다.
-
DELETE 권한은 런타임 역할이 Amazon S3에서 테이블 데이터를 삭제할 수 있도록 허용합니다.
참고
Lake Formation은 Spark 작업이 AWS Glue를 호출하여 테이블 메타데이터를 검색하고 Amazon S3를 호출하여 테이블 데이터를 검색할 때 권한을 느리게 평가합니다. 권한이 부족한 런타임 역할을 사용하는 작업은 Spark가 누락된 권한이 필요한 AWS Glue 또는 Amazon S3를 호출할 때까지 실패하지 않습니다.
참고
다음 지원되는 테이블 매트릭스에서:
-
Supported로 표시된 작업은 Lake Formation 자격 증명만 사용하여 Lake Formation에 등록된 테이블의 테이블 데이터에 액세스합니다. Lake Formation 권한이 충분하지 않으면 작업이 런타임 역할 자격 증명으로 돌아가지 않습니다. Lake Formation에 등록되지 않은 테이블의 경우 작업 런타임 역할 자격 증명이 테이블 데이터에 액세스합니다.
-
Amazon S3 위치에서 지원되는 IAM 권한으로 표시된 작업은 Lake Formation 자격 증명을 사용하여 Amazon S3의 기본 테이블 데이터에 액세스하지 않습니다. 이러한 작업을 실행하려면 테이블이 Lake Formation에 등록되어 있는지 여부에 관계없이 작업 런타임 역할에 테이블 데이터에 액세스하는 데 필요한 Amazon S3 IAM 권한이 있어야 합니다.
참고
Amazon EMR 7.12부터 테이블 데이터를 수정하는 DML 및 DDL 작업은 Lake Formation 자격 증명을 사용합니다. Amazon EMR 7.11 이전 버전에서 이러한 작업(DELETE, UPDATE 및 MERGE 제외)은 대신 작업 런타임 역할 자격 증명을 사용하여 테이블 데이터를 수정합니다. Amazon EMR 7.11 이전 버전은 DELETE, UPDATE 및 MERGE 작업을 지원하지 않습니다.
