기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon EMR 클러스터를 생성하고 작업하는 방법 이해
이 항목에서는 클러스터에 작업을 제출하는 방법, 데이터를 처리하는 방법, 처리 중 클러스터가 통과하는 다양한 단계 등을 포함하는 Amazon EMR 클러스터의 개요를 제공합니다.
클러스터 및 노드에 익숙해지기
Amazon EMR의 중심 구성 요소는 클러스터입니다. 클러스터는 Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스의 모음입니다. 클러스터에 있는 각 인스턴스를 노드라고 합니다. 각 노드에는 클러스터 내에서 역할(노드 유형이라고 함)이 있습니다. 또한 Amazon EMR은 각 노드 유형에 다양한 소프트웨어 구성 요소를 설치하여 각 노드에 Apache Hadoop과 같은 분산 애플리케이션의 역할을 부여합니다.
Amazon EMR의 노드 유형은 다음과 같습니다.
-
프라이머리 노드: 처리를 위해 다른 노드 간에 데이터와 작업의 배포를 조정하는 소프트웨어 구성 요소를 실행하여 클러스터를 관리하는 노드입니다. 프라이머리 노드는 작업 상태를 추적하고 클러스터 상태를 모니터링합니다. 모든 클러스터에는 프라이머리 노드가 있으며 프라이머리 노드만으로 단일 노드 클러스터를 생성할 수 있습니다.
-
코어 노드: 클러스터의 Hadoop 분산 파일 시스템(HDFS)에서 작업을 실행하고 데이터를 저장하는 소프트웨어 구성 요소가 있는 노드입니다. 다중 노드 클러스터에는 1개 이상의 코어 노드가 있습니다.
-
작업 노드: 작업만 실행하고 HDFS에 데이터를 저장하지는 않는 소프트웨어 구성 요소가 있는 노드입니다. 작업 노드는 선택 사항입니다.
클러스터를 생성할 때 인스턴스 그룹 또는 인스턴스 플릿의 두 가지 구성 중 하나를 선택하여 노드를 구성합니다. 인스턴스 그룹을 사용하면 각 그룹에 동일한 유형의 Amazon EC2 인스턴스가 포함되며 노드 유형당 여러 그룹을 가질 수 있습니다(기본 제외). 인스턴스 플릿의 경우 각 노드 유형에는 온디맨드 및 스팟 인스턴스의 대상 용량과 함께 인스턴스 유형을 혼합하여 포함할 수 있는 단일 플릿이 있습니다. 이 선택은 영구적이며 클러스터 생성 후에는 변경할 수 없습니다. 자세한 내용은 인스턴스 플릿이나 균일한 인스턴스 그룹을 사용하여 Amazon EMR 클러스터 생성 단원을 참조하십시오.
클러스터에 작업 제출
Amazon EMR에서 클러스터를 실행할 때 수행해야 할 작업을 지정하는 방법에 대한 몇 가지 옵션이 있습니다.
-
클러스터를 생성할 때 단계로 지정할 함수에서 수행할 작업의 전체 정의를 제공하세요. 이 작업은 대개 설정된 양의 데이터를 처리하고 처리가 완료되면 종료되는 클러스터에 대해 수행됩니다.
-
장기 실행 클러스터를 생성하고 Amazon EMR 콘솔, Amazon EMR API 또는를 사용하여 하나 이상의 작업이 포함될 수 있는 단계를 AWS CLI 제출합니다. 자세한 내용은 Amazon EMR 클러스터에 작업 제출 단원을 참조하십시오.
-
클러스터를 생성하고, SSH를 사용하여 필요한 대로 프라이머리 노드 및 기타 노드에 연결하며, 설치된 애플리케이션에서 제공한 인터페이스를 사용하여 작업을 수행하고 스크립트 방식이나 대화형으로 쿼리를 제출합니다. 자세한 내용은 Amazon EMR 릴리스 안내서를 참조하세요.
데이터 처리
클러스터를 시작할 때 데이터 치리 필요를 위해 설치할 프레임워크와 애플리케이션을 선택합니다. Amazon EMR 클러스터에서 데이터를 처리하려면 설치된 애플리케이션에 작업 또는 쿼리를 직접 제출하거나 클러스터에서 단계를 실행할 수 있습니다.
애플리케이션에 직접 작업 제출
Amazon EMR 클러스터에 설치된 소프트웨어에 직접 작업을 제출하고 상호 작용할 수 있습니다. 이렇게 하려면 일반적으로 보안 연결을 통해 프라이머리 노드에 연결하고 클러스터에서 직접 실행되는 소프트웨어에 사용할 수 있는 인터페이스와 도구에 액세스합니다. 자세한 내용은 Amazon EMR 클러스터에 연결하기 단원을 참조하십시오.
단계를 실행하여 데이터 처리
순서가 지정된 하나 이상의 단계를 Amazon EMR 클러스터에 제출할 수 있습니다. 각 단계는 클러스터에 설치된 소프트웨어에서 처리할 데이터를 조작하기 위한 지침이 포함된 작업 단위입니다.
다음은 네 개의 단계를 사용하는 예제 프로세스입니다.
-
처리를 위해 입력 데이터 세트 제출
-
Pig 프로그램을 사용하여 첫 번째 단계의 출력 처리.
-
Hive 프로그램을 사용하여 두 번째 입력 데이터 세트를 처리합니다.
-
출력 데이터 세트를 씁니다.
일반적으로 Amazon EMR에서 데이터를 처리할 때 입력은 Amazon S3 또는 HDFS와 같은 선택한 기본 파일 시스템에 파일로 저장된 데이터입니다. 이 데이터는 처리 시퀀스에 따라 한 단계에서 다음 단계로 전달됩니다. 최종 단계는 Amazon S3 버킷과 같은 지정된 위치에 출력 데이터를 씁니다.
단계는 다음 시퀀스로 실행됩니다.
-
요청을 제출하여 처리 단계를 시작합니다.
-
모든 단계의 상태는 PENDING으로 설정됩니다.
-
시퀀스의 첫 번째 단계가 시작되면 상태가 RUNNING으로 바뀝니다. 다른 단계는 PENDING 상태로 유지됩니다.
-
첫 번째 단계가 완료된 후에는 상태가 COMPLETED로 바뀝니다.
-
시퀀스의 다음 단계가 시작되고 상태가 RUNNING으로 바뀝니다. 완료되면 상태가 COMPLETED로 바뀝니다.
-
단계가 모두 완료되고 처리가 종료될 때까지 이 패턴이 각 단계에 대해 반복됩니다.
다음 다이어그램은 단계 시퀀스와 단계가 처리될 때 단계의 상태 변화를 나타냅니다.

한 단계가 처리 중에 실패하면 해당 상태가 실패로 바뀝니다. 각 단계별로 다음 상황을 결정할 수 있습니다. 기본적으로 시퀀스에 남아 있는 모든 단계는 CANCELLED로 설정되며 진행되는 단계에 실패해도 실행되지 않습니다. 또한 오류를 무시하고 남은 단계를 진행하도록 선택하거나 해당 클러스터를 즉시 종료하도록 선택할 수 있습니다.
다음 다이어그램은 단계 시퀀스와 처리 중 단계가 실패할 때 기본적인 단계 변화를 나타냅니다.

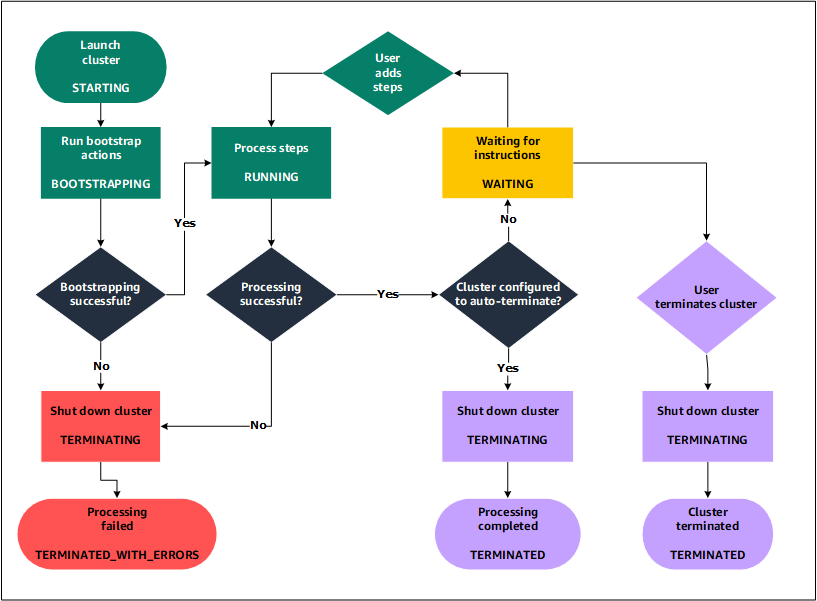
클러스터 수명 주기 이해
성공적인 Amazon EMR 클러스터는 다음 프로세스를 따릅니다.
-
Amazon EMR은 먼저 사용자가 지정한 내용에 따라 각 인스턴스의 클러스터에서 EC2 인스턴스를 프로비저닝합니다. 자세한 내용은 Amazon EMR 클러스터 하드웨어 및 네트워킹 구성 단원을 참조하십시오. 모든 인스턴스에 대하여 Amazon EMR은 Amazon EMR에 대한 기본 AMI를 사용하거나 사용자가 지정한 사용자 지정 Amazon Linux AMI를 사용합니다. 자세한 내용은 사용자 지정 AMI를 사용하여 Amazon EMR 클러스터 구성에 더 많은 유연성 제공 단원을 참조하십시오. 이 단계 중에 클러스터 상태는
STARTING입니다. -
Amazon EMR은 사용자가 각 인스턴스에 지정한 부트스트랩 작업을 실행합니다. 부트스트랩 작업을 사용하여 사용자 지정 애플리케이션을 설치하고 필요한 사용자 지정을 수행할 수 있습니다. 자세한 내용은 부트스트랩 작업을 생성하여 Amazon EMR 클러스터에서 추가 소프트웨어 설치 단원을 참조하십시오. 이 단계 중에 클러스터 상태는
BOOTSTRAPPING입니다. -
Amazon EMR은 Hive, Hadoop, Spark 등 클러스터를 생성할 때 지정한 기본 애플리케이션을 설치합니다.
-
부트스트랩 작업이 성공적으로 완료되고 기본 애플리케이션이 설치된 후 클러스터 상태는
RUNNING입니다. 이 시점에서 클러스터 인스턴스에 연결할 수 있으며 해당 클러스터는 사용자가 클러스터를 생성할 때 지정했던 단계를 순차적으로 실행합니다. 실행 후 추가 단계를 제출하여 모든 이전 단계가 완료된 후 실행되도록 할 수 있습니다. 자세한 내용은 Amazon EMR 클러스터에 작업 제출 단원을 참조하십시오. -
해당 단계를 성공적으로 실행한 후 클러스터 상태는
WAITING가 됩니다. 마지막 단계를 완료한 후 자동 종료하도록 클러스터를 구성한 경우TERMINATING상태에서TERMINATED상태로 변경됩니다. 클러스터가 대기하도록 구성된 경우 더 이상 클러스터가 필요하지 않으면 클러스터를 수동으로 종료해야 합니다. 클러스터를 수동으로 종료하면TERMINATING상태로 바뀐 후,TERMINATED상태가 됩니다.
종료 방지 기능이 활성화되어 있지 않으면 클러스터 수명 주기 중 오류로 인해 Amazon EMR이 클러스터 및 모든 인스턴스를 종료합니다. 오류로 인해 클러스터를 종료하는 경우 클러스터에 저장된 데이터가 삭제되고 클러스터 상태는 TERMINATED_WITH_ERRORS가 됩니다. 종료 방지 기능이 활성화된 경우 클러스터로부터 데이터를 가져온 다음 종료 방지 기능을 비활성화하고 클러스터를 종료할 수 있습니다. 자세한 내용은 종료 방지를 사용하여 Amazon EMR 클러스터가 실수로 종료되지 않도록 보호 단원을 참조하십시오.
다음 다이어그램은 클러스터의 수명 주기와 수명 주기의 각 스테이지가 특정 클러스터 상태에 매핑되는 방식을 나타냅니다.